.svg.png.webp)
En informatique, la répartition de charge (en anglais : load balancing) désigne le processus de répartition d’un ensemble de tâches sur un ensemble de ressources, dans le but d’en rendre le traitement global plus efficace. Les techniques de répartition de charge permettent à la fois d’optimiser le temps de réponse pour chaque tâche, tout en évitant de surcharger de manière inégale les nœuds de calcul.
La répartition de charge est issue de la recherche dans le domaine des ordinateurs parallèles. Deux principales approches coexistent : les algorithmes statiques, qui ne tiennent pas compte de l’état des différentes machines, et les algorithmes dynamiques, qui sont en général plus généraux et performants, mais nécessitent des échanges d’information entre les différentes unités de calculs, au risque d’une perte d’efficacité.
Ces techniques sont par exemple très utilisées dans le domaine des services HTTP où un site à forte audience doit pouvoir gérer des centaines de milliers de requêtes par seconde.
Spécifications d'un algorithme de répartition
Un algorithme de répartition des charges cherche toujours à répondre à un problème spécifique. Entre autres, la nature des tâches qui seront exécutées, la complexité algorithmique que l’on s’autorise, l’architecture matérielle sur laquelle les algorithmes vont fonctionner ou encore la tolérance d’erreurs que l’on s’accorde doivent être pris en compte. Un compromis doit donc être trouvé pour répondre au mieux à un cahier des charges précis.
Nature des tâches
Selon la nature des tâches, les algorithmes de répartitions seront plus ou moins efficaces. De ce fait, plus on dispose d’information sur les tâches au moment de la prise de décision, plus les possibilités d’optimisation des algorithmes seront grandes.
Taille des tâches
La connaissance parfaite du temps d’exécution de chacune des tâches permet d’arriver à une répartition de charge optimale (voir l'algorithme de somme préfixale décrit ci-dessous)[1]. Malheureusement, il s’agit en fait d’un cas idéalisé. Il est en effet extrêmement rare que l’on connaisse le temps exact d’exécution de chaque tâche.
Il existe cependant plusieurs techniques pour avoir une idée des différents temps d’exécution. Tout d’abord, si l’on a la chance d’avoir des tâches de taille relativement homogène, il est possible de considérer que chacune d’entre elles nécessitera environ le temps moyen d’exécution. Si en revanche, le temps d’exécution est très irrégulier, il faut avoir recours à des techniques plus subtiles. L’une d’elles consiste à ajouter quelques métadonnées à chacune des tâches. En fonction des temps d’exécution précédents pour des métadonnées similaires, il est possible de faire des inférences pour une tâche future en se basant sur les statistiques[2].
Dépendances
Dans certains cas, les taches dépendent les unes des autres. Ces interdépendances peuvent s’illustrer par un graphe orienté acyclique. Intuitivement, certaines tâches ne peuvent pas commencer tant que d’autres n’ont pas été terminées.
À supposer que le temps requis pour chacune des tâches soit connu à l’avance, il faut donc préalablement trouver un ordre d’exécution qui minimise le temps total de calcul. Bien qu’il s’agisse ici d’un problème NP-difficile, donc souvent impossible à résoudre informatiquement, il existe toutefois des algorithmes d'ordonnancement qui calculent des répartitions des tâches honorables par des méthodes métaheuristiques.
Séparabilité des tâches
Une autre particularité des tâches est leur capacité à pouvoir être découpée en sous-tâches en cours d’exécution. L’algorithme de « Tree-Shaped Computation » présenté ensuite tire justement partie de cette spécificité.
Algorithmes statiques et dynamiques
Algorithmes statiques
Un algorithme de répartition de charge est dit “statique” lorsqu’il ne prend pas en compte l’état du système dans la répartition des tâches. Par état du système, on entend ici le niveau de charge (voire parfois surcharge) de certains processeurs. Bien entendu, le nombre de processeurs, leur puissance respective et les vitesses de communications sont connues. Il s’agit donc d’associer les tâches aux processeurs de manière à minimiser une certaine fonction de performance. Toute l’astuce réside donc dans la conception de cette fonction de performance.
Les techniques sont toujours centralisées autour d’un organe qui distribue les charges et assure la minimisation de ladite fonction. Cette minimisation peut prendre en compte des informations liées aux tâches à distribuer, et en tirer un temps d’exécution probable.
L’avantage des algorithmes statiques est qu’ils sont faciles à mettre en place et sont, dans le cas de tâches assez régulières (comme dans le traitement des requêtes HTTP d’un site internet), extrêmement efficace. Cependant, il subsiste une variance statistique dans l’assignation des tâches qui peut entraîner une surcharge de certaines unités de calcul.
Algorithmes dynamiques
Contrairement aux algorithmes de répartition de charge statiques, on qualifie de dynamiques ceux dont la charge de chacune des unités de calcul (aussi appelées nœuds) du système est pris en compte. Dans cette approche, les tâches peuvent se déplacer dynamiquement d’un nœud surchargé à un nœud en sous-charge, afin d'être traitées plus rapidement. Si ces algorithmes sont bien plus compliqués à mettre en place, ils peuvent produire, lorsqu’ils sont bien écrits, d’excellents résultats. Notamment lorsque le temps d’exécution varie fortement d’une tâche à l’autre.
L’architecture est cette fois-ci beaucoup plus modulable puisqu’il n’est pas obligatoire d’avoir un organe spécialement destiné à la distribution du travail. Lorsque les tâches sont assignées de manière unique à un processeur en fonction de son état à un moment donné, on parle d’assignation unique. Si par-contre, celles-ci peuvent être redistribuées en permanence en fonction de l’état du système et de ses évolutions, on parle d’assignation dynamique. Dans ce dernier cas, il faut faire attention à ne pas engendrer des coûts de communication trop importants entre les différentes unités, au risque de ralentir la résolution du problème global. Le pire des cas étant une partie de ping-pong entre les processeurs, résultant en un blocage indéfini de la résolution[3].
Architecture matérielle
Machines de puissance hétérogènes
Les infrastructures informatiques parallèles sont souvent composées de machines de différentes puissances. Dès lors, ce paramètre peut être pris en compte dans la répartition de charge.
Par exemple, les unités de plus faible puissance peuvent recevoir en priorité les requêtes demandant une plus petite quantité de calcul, ou dans le cas où la taille des requêtes est homogène ou inconnue, en recevoir moins que les plus grosses unités.
Mémoire partagée ou distribuée
On distingue souvent les ordinateurs parallèles en deux grandes catégories : ceux où tous les processeurs partagent une unique mémoire commune sur laquelle ils lisent et écrivent en parallèle (modèle PRAM), et ceux où chaque unité de calcul a sa propre mémoire (modèle de la mémoire distribuée), et où les échanges d’informations se font par messages.
Pour les ordinateurs à mémoire commune, la gestion des conflits d’écriture ralentit grandement la vitesse d’exécution individuelle de chacune des unités de calcul. Celles-ci peuvent cependant parfaitement travailler en parallèle. À l’inverse, dans le cas d’échange de message, chacun des processeurs peut travailler à plein régime. En revanche, quand vient le moment des échanges de messages, tous les processeurs sont obligés d’attendre les processeurs les plus lents pour commencer la phase de communication. On parle de synchronisation.
En réalité, rares sont les systèmes appartenant exactement à une seule des catégories. En général, les processeurs ont chacun une mémoire interne pour stocker les données nécessaires aux prochains calculs, et sont organisés dans des clusters successifs. Il n’empêche que les ordinateurs parallèles ont habituellement une tendance structurelle distribuée ou partagée. Il convient donc d’adapter de manière unique l’algorithme de répartition de charge à une architecture parallèle. Sinon, on risque de perdre grandement en efficacité dans la résolution parallèle du problème.
Hiérarchie
En s’adaptant aux structures matérielles vues précédemment, on retrouve parmi les algorithmes de répartition de charge deux grandes catégories. D’une part celle où les tâches sont attribuées par un « maître », et exécutées par des « travailleurs » (modèle maître-esclave) qui tiennent le maître au courant de l’évolution de leur travail, celui-ci pouvant alors se charger d’attribuer (voire réattribuer) la charge de travail. La littérature parle d’architecture « Master-Worker ». À l’inverse, le contrôle peut être distribué entre les différents nœuds. L’algorithme de répartition de charge est alors exécuté sur chacun d’entre eux et la responsabilité de l’attribution des tâches (ou parfois ré-attribution pour certains algorithmes) est partagée. Cette dernière catégorie suppose un algorithme de répartition des charges dynamique.
Encore une fois, la conception de chaque algorithme de répartition de charge étant unique, il convient de nuancer la distinction précédente. Ainsi, il est également possible d’avoir une stratégie intermédiaire, avec par exemple des nœuds « maîtres » pour chaque sous cluster eux-mêmes soumis à un « maître » global. On rencontre aussi, des organisations en plusieurs niveaux, avec une alternance entre stratégie de contrôle « maître-esclave » et distribuée. Ces dernières stratégies devenant rapidement complexes, on ne les rencontre que rarement. Les concepteurs préférant des algorithmes plus facilement pilotables.
Adaptabilité à des architectures plus grandes (scalabilité)
Dans le cadre d’algorithmes s’exécutant sur du très long terme (serveurs, cloud…), l’architecture de l’ordinateur évolue avec le temps car elle s’adapte à la demande. Il est toutefois préférable de ne pas devoir concevoir un nouvel algorithme à chaque fois.
Un paramètre extrêmement important d’un algorithme de répartition de charge est donc sa capacité à s’adapter à une architecture matérielle évolutive. On appelle cela la scalabilité (de l’anglais « scalable ») de l’algorithme. On dit aussi qu’un algorithme est scalable pour un paramètre d’entrée lorsque ses performances restent relativement indépendantes de la taille de ce paramètre.
Lorsque l’algorithme est capable de s’adapter à un nombre variant d’unités de calculs, mais que celui doit être fixé avant son exécution, on parle de version moulable (« moldable » en anglais). Si à l’inverse, l’algorithme est capable de s’adapter en temps réel aux ressources disponibles, on dit que l’algorithme est malléable. La plupart des algorithmes de répartition de charge sont au moins moulables[4].
Tolérance d'erreurs
Dans les grands centres informatique, il n'est pas envisageable qu’une exécution n’aboutisse pas en raison d’une panne sur l’une des machines. Il est donc nécessaire de trouver des solutions pour détecter ces dysfonctionnements matériels et redistribuer la charge de travail sur des unités fonctionnelles, tout en signalant la panne matérielle à la maintenance[5].
Approches
Répartition statique avec connaissance complète des tâches : la somme préfixale
Si les tâches sont indépendantes les unes des autres, si l’on connait parfaitement leur temps d’exécution respectif, et si enfin les tâches sont divisibles, il existe un algorithme simple et optimal.
En divisant les tâches de manière à donner la même quantité de calcul à chaque processeur, il ne reste plus qu’à regrouper les résultats. À l’aide d’un algorithme de somme préfixale, le calcul de cette répartition est réalisable en un temps logarithmique du nombre de processeurs.
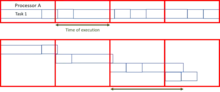
Si toutefois les tâches ne sont pas divisibles (on dit alors qu’elles sont atomiques), bien que l’optimisation de l’assignation des tâches soit un problème difficile, il est toujours possible d’approximer une répartition relativement équitable des tâches, à condition que la taille de chacune d’elles soit très inférieure à la quantité totale de calcul effectué par chacun des nœuds[1].
La plupart du temps, on ne connait pas le temps d’exécution d’une tâche et l’on peut tout-au-mieux en avoir une idée probable. C'est pourquoi cet algorithme, bien que particulièrement efficace ne reste que théorique. De ce fait, il sert essentiellement de référence pour comparer les temps d’exécution des autres algorithmes.
Répartition statique de charge sans connaissance préalable
Dans le cas où le temps d’exécution n’est pas du tout connu à l’avance, il est toujours possible de faire de la répartition statique de charge. Pour cela, de nombreuses méthodes existent. Encore une fois, ces méthodes peuvent s’adapter à un problème en particulier.
Round-Robin
Cet algorithme est très simple, la première requête est envoyée au premier serveur, puis la suivante au second, et ainsi de suite jusqu'au dernier. Ensuite on recommence en attribuant la prochaine requête au premier serveur, etc.
Que les requêtes soient urgentes ou non, elles seront toutes traitées de la même manière[6].
Cet algorithme peut être pondéré afin que les unités les plus puissantes reçoivent le plus grand nombre de requêtes, et les reçoivent en premier.
Assignation aléatoire
Il s’agit simplement d’assigner de manière aléatoire les tâches aux différents serveurs. Cette méthode donne d’assez bons résultats. Si par ailleurs, on connait par avance le nombre de tâches, il est encore plus efficace de calculer une permutation aléatoire à l’avance. Cela permet d’éviter des coûts de communications lors de chacune des assignations. On n'a plus besoin en effet de maître de la distribution car chacun sait quelle tâche lui est assignée. Quand bien même le nombre de tâches ne serait pas connu, il est toujours possible de se passer de communication avec une génération pseudo-aléatoire d’assignation connue de tous les processeurs.
La performance de cette stratégie (mesurée en temps d’exécution total pour un ensemble de tâches fixe données) décroît avec la taille maximale des tâches.
Autres
Évidemment, d’autres méthodes d’assignation existent aussi :
•Moins de travail : assigne davantage de tâches aux serveurs en exécutant le moins (la méthode peut aussi être pondérée).
•Hachage : répartit les requêtes en fonction d’une table de hachage.
•…
Algorithmes « Master-Worker »
Peut-être l’algorithme de répartition de charge dynamique le plus simple, un maître distribue la charge de travail à l’ensemble des travailleurs (aussi parfois appelé « esclave »). Au début, tous les travailleurs sont inactifs et le signalent au maître. Dès lors celui-ci leur distribue les tâches. Quand il n’a plus de tâche à donner, il en informe les travailleurs afin qu’ils cessent de demander des requêtes.
L’avantage de ce système est qu’il répartit de manière très équitable la charge. De fait, si l’on ne tient pas compte du temps nécessaire à l’assignation, le temps d’exécution serait comparable à l'algorithme de somme préfixale vue précédemment.
Le problème de cet algorithme est qu’il s’adapte difficilement à un grand nombre de processeurs. Les communications et les temps d’allumage prenant trop de temps. Ce manque de scalabilité le rend rapidement inopérant dans les très grands serveurs ou très gros ordinateurs parallèles. Le maître joue en effet le rôle de goulot d’étranglement.

On peut toutefois améliorer l’efficacité en limitant l’abondance de petites tâches que l’on assemble en deux plus grandes, ce qui limite la communication. La qualité de l’algorithme peut aussi être grandement améliorée en remplaçant le maître par une liste partagée de tâche dans lequel les différents processeurs vont se servir. Si cet algorithme est un peu plus difficile à implémenter, il promet toutefois une bien meilleure scalabilité, quoiqu’encore insuffisante pour les très grands centres de calculs.
Architecture non hiérarchique, sans connaissance du système : le « work-stealing »
Pour pallier les problèmes de scalabilité lorsque l’on ne connait pas le temps de réalisation des tâches, l’une des techniques les plus célèbres et celle du « work-stealing » (“vol de travail” en anglais).
Le principe consiste à attribuer à chacun des processeurs un certain nombre de tâches de manière aléatoire ou définie à l’avance, puis à autoriser les processeurs inactifs à « voler » du travail à des processeurs actifs ou surchargés. Si cette technique peut s’avérer particulièrement efficace, elle est délicate à implémenter car il faut s’assurer que les échanges de message ne se substituent pas à la résolution effective du problème
Dans le cas où les tâches sont atomiques, on distingue deux grandes stratégies, celles où les processeurs peu chargés offrent leur capacité de calcul à ceux les plus en difficulté, et celles où les unités les plus chargées souhaitent alléger la charge de travail qui leur est attribuée. Il a été montré[7] que lorsque le réseau est très chargé, il est plus efficace que les unités les moins chargées offrent leur disponibilité et que lorsque le réseau est peu chargé, ce soient les processeurs surchargés qui demandent un soutien de la part des plus inactifs. Cela permet en effet de limiter le nombre de messages échangés te se comprend intuitivement.
Dans le cas où l’on part d’une seule grande tâche que l’on ne peut diviser au-delà d’un niveau atomique, il existe un algorithme très efficace, intitulé « Tree-Shaped computation »[8], où la tâche parente est distribuée dans un arbre de travail.
Principe
Initialement, tous les processeurs possèdent une tâche vide, sauf un qui travaille séquentiellement dessus. Les processeurs inactifs émettent alors des demandes à d’autres processeurs aléatoirement (pas nécessairement actifs). Si celui-ci est capable de subdiviser la tâche sur laquelle il travaille, il le fait en envoyant une partie de son travail au nœud à l’origine de la requête. Sinon, il renvoie une tâche vide. Cela induit donc une structure d’arbre. Il convient, ensuite de transmettre un signal de terminaison au processeur parent lorsque la sous-tâche est terminée, afin qu’à son tour, il fasse parvenir le message à son parent jusqu’à remonter à la racine de l’arbre. Lorsque le premier processeur, c’est-à-dire la racine, a terminé, il est possible de partager un message global de terminaison. À la fin, il est nécessaire d’assembler les résultats en remontant l’arbre.
Efficacité
Là encore, l’efficacité d’un tel algorithme est proche de la somme préfixale dès lors que le temps de découpe de tâche et de communication n’est pas trop élevé par rapport au travail à effectuer. Pour éviter des coûts de communication trop élevés, il est encore une fois possible d’imaginer une liste des tâches sur une mémoire partagée. Une demande consiste donc simplement à lire à partir d’une certaine position sur cette mémoire commune.
Exemple d'application : les requêtes HTTP
Les requêtes HTTP forment sûrement l’un des domaines d’applications des algorithmes de répartition de charge le plus répandu, et donc sûrement aussi l’un des domaines les plus aboutis. Il convient donc d’en décrire les spécificités.
Terminologie
Dans le domaine de la répartition de charge, on appelle :
- « Serveur virtuel », un pool de serveurs affecté à une tâche, l'adresse et le port utilisés doivent être réglés sur le répartiteur de charge et, selon le mode, sur les serveurs de calcul.
- « Serveur réel », un des serveurs dans le pool.
Réglages et paramètres des répartiteurs de charge
Sur les répartiteurs de charge les plus courants, on peut pondérer la charge de chaque serveur indépendamment. Cela est utile lorsque, par exemple, on veut mettre, à la suite d'un pic ponctuel de charge, un serveur de puissance différente dans la grappe pour alléger sa surcharge. On peut ainsi y ajouter un serveur moins puissant, si cela suffit, ou un serveur plus puissant en adaptant le poids.
Il est généralement également possible de choisir entre plusieurs algorithmes d'ordonnancement :
- Round-Robin : C'est l'algorithme le plus simple, une requête est envoyée au premier serveur, puis une au second, et ainsi de suite jusqu'au dernier, puis un tour est recommencé avec une première requête au premier serveur, etc.
- Round-Robin pondéré : Les serveurs de poids fort prennent les premières requêtes et en prennent davantage que ceux de poids faible.
- Moins de connexion : Assigne davantage de requêtes aux serveurs en exécutant le moins.
- Moins de connexion, pondéré : Assigne davantage de requêtes aux serveurs en exécutant le moins en tenant compte de leur poids.
- Hachage de destination : Répartit les requêtes en fonction d'une table de hachage contenant les adresses IP des serveurs.
- Hachage de source : Répartit les requêtes en fonction d'une table de hachage basée sur les adresses IP d'où proviennent les requêtes.
- ...
Il y a deux façons de router les paquets, lors des requêtes :
- Network address translation (NAT, traduction d'adresse réseau) : Dans ce cas, le répartiteur reçoit les requêtes, les renvoie aux différents serveurs de calcul en adresse IP privée, reçoit les réponses et les renvoie aux demandeurs. Cette technique est très simple à mettre en place, mais demande au répartiteur d'assumer toute la charge du trafic réseau.
- Routage direct (DR, Direct Routing) : Dans ce cas, les requêtes arrivent sur le répartiteur, sont renvoyées aux serveurs de calcul, qui renvoient directement les réponses au demandeur. Cela oblige à monopoliser davantage d'adresses IP (les adresses IPv4 sont limitées et de plus en plus difficiles à obtenir auprès du RIPE), mais allège considérablement le trafic réseau du répartiteur de charge et enlève donc par là-même un goulot d'étranglement. Dans la majorité des cas, pour le HTTP, les requêtes (URL et quelques variables) sont beaucoup plus petites que les réponses, qui sont généralement des fichiers dynamiques (XHTML) produits par un langage de script ou des fichiers statiques (JavaScript, CSS, images, sons, vidéos).
Le protocole Virtual Router Redundancy Protocol (VRRP, protocole de redondance de routeur virtuel), permet de gérer la reprise sur panne d'un des répartiteurs de charge.
Les fermes de serveurs

Dans une ferme de serveurs (server cluster en anglais) un groupe de serveurs fonctionne comme un dispositif informatique unique. Les machines sont reliées entre elles et exécutent un logiciel qui contrôle leur activité et leur disponibilité, dans le but d'exploiter leur disponibilité par la répartition de charge. Les informations relatives à la disponibilité de chaque machine sont envoyées à un serveur maître, et celui-ci distribue les tâches entre les machines de la ferme en choisissant de préférence celles qui sont le plus disponibles, ceci en vue d'éviter la saturation d'une des machines de la ferme[9].
Les institutions favorisent les fermes de serveurs, en particulier pour les applications internet, parce que celles-ci permettent d'assurer une haute disponibilité de l'application, ainsi qu'une scalabilité élevée : la croissance peut être prise en charge dans une très large mesure par l'adaptation du matériel[9]. La popularisation d'Internet dans les années 1990 a permis pour la première fois de mettre des services à disposition du monde entier, et l'équilibrage de charge a permis à ces services de supporter de manière sûre, fiable et rapide des demandes provenant de plusieurs millions d'utilisateurs[10].
Selon une étude parue en 2003, le moteur de recherche Google est une ferme de serveurs composée de 6 000 micro-ordinateurs, qui peut répondre à 1000 demandes de recherche par seconde. De la même manière, tous les services Internet populaires utilisent à l'insu du client une batterie d'ordinateurs, et la technique de l'équilibrage de charge[10].
La mise en œuvre
La répartition de charge permet de distribuer des applications à travers un réseau. Cette technique permet de distribuer n'importe quel service entre différents ordinateurs et emplacements géographiques. Elle est principalement utilisée pour les serveurs web, ainsi que les points d'accès VPN, les proxy ou les pare-feu[11],[12].
La visite d'un site web provoque l'émission de requêtes HTTP. Chaque requête contient le nom du serveur à qui elle est destinée, qui devra alors la traiter. Le travail du serveur peut être allégé en envoyant les requêtes suivantes à d'autres serveurs à tour de rôle[11]. Une technique consiste à faire correspondre le nom du serveur avec plusieurs ordinateurs en modifiant continuellement les tables de correspondance du service DNS. La distribution par le DNS ne tient cependant pas compte de l'état des serveurs, en particulier de la disponibilité et des pannes éventuelles. Les demandes peuvent alors être envoyées à des serveurs qui sont déjà 100 % occupés, ou à des serveurs en panne. L'utilisation d'un dispositif de répartition permet de résoudre ces deux problèmes[11],[12].
Le répartiteur peut être un routeur, un switch, un système d'exploitation ou un logiciel applicatif. Il répartit les demandes en les distribuant uniquement aux serveurs disponibles. Le destinataire des demandes peut également être imposé : dans un site de vente en ligne, lorsqu'une demande sécurisée est faite par un acheteur - par exemple l'achat d'un produit - les demandes suivantes provenant de cet acheteur seront toutes envoyées au même serveur[11],[12]. Le répartiteur simule la présence d'un serveur : les clients communiquent avec le répartiteur comme s'il s'agissait d'un serveur. Celui-ci répartit les demandes provenant des clients et les transmet aux différents serveurs. Lorsqu'un serveur répond à une demande, celle-ci est transmise au répartiteur ; puis le répartiteur transmet la réponse au client en modifiant l'adresse IP de l'expéditeur pour faire comme si cette réponse provenait du serveur[12].
Les machines de la ferme doivent avoir accès au même lot de fichiers, ceci peut être réalisé à l'aide d'un système de fichiers distribué ou à l'aide d'un réseau de stockage (abr. SAN). Les serveurs ne vérifient pas individuellement les sessions parce que, du fait de la répartition, plusieurs serveurs peuvent être impliqués lors d'une même session[11].
Principes
Analyse du risque
Si de gros volumes de données sont concernés il sera difficile de tout sauvegarder sans mettre en place de grosses unités de sauvegarde et de bande passante. La perte de données doit être envisagée afin de choisir celles dont l'impact est fort (sauvegardes importantes) ou faible (données transitoires). Par exemple, pour un site marchand, perdre le contenu d'un panier est bien plus dommageable que la liste des articles que l'internaute vient de visiter.
Un autre indicateur important consiste à estimer le temps d'indisponibilité toléré sur un an en pourcentage. On le quantifie en « nombre de neuf ».
- 99 % de disponibilité : moins de 3,65 jours hors service tolérés par an
- 99,9 % : moins de 8,75 heures
- 99,999 % : moins de 5,2 minutes (référence dans le monde des télécommunications)
Partage de charge dans le cadre des réseaux
Le principe de la répartition de charge s'applique aussi au domaine des connexions réseau. Il existe plusieurs façons de mettre en place ce type de solution. On peut soit acheter un boîtier d'équilibrage de charge et l'administrer soi-même ; soit, comme certaines entreprises le proposent : acquérir le boîtier et faire appel au service de supervision qui l'accompagne.
Des constructeurs équipementiers ont conçu des boîtiers de partage de charge.
Depuis 1985, des sociétés telles que Cisco, Alcatel-Lucent ou HPC ont développé des services complets de répartition de charge dans le domaine des réseaux et connexions Internet, et améliorent régulièrement les algorithmes les régissant.
Notes et références
- 1 2 Sanders, Peter, 1967-, Dietzfelbinger, Martin, et Dementiev, Roman,, Sequential and parallel algorithms and data structures : the basic toolbox, , 509 p. (ISBN 978-3-030-25209-0 et 3-030-25209-4, OCLC 1119668318, lire en ligne)
- ↑ (en) Qi Liu, Weidong Cai, Dandan Jin et Jian Shen, « Estimation Accuracy on Execution Time of Run-Time Tasks in a Heterogeneous Distributed Environment », Sensors, vol. 16, no 9, , p. 1386 (ISSN 1424-8220, PMID 27589753, PMCID PMC5038664, DOI 10.3390/s16091386, lire en ligne, consulté le )
- ↑ (en) Alakeel, Ali, « A Guide to Dynamic Load Balancing in Distributed Computer Systems », International Journal of Computer Science and Network Security, (IJCSNS), vol 10, (lire en ligne)
- ↑ Sajjad Asghar, Eric Aubanel et David Bremner, « A Dynamic Moldable Job Scheduling Based Parallel SAT Solver », 2013 42nd International Conference on Parallel Processing, , p. 110–119 (DOI 10.1109/ICPP.2013.20, lire en ligne, consulté le )
- ↑ G. Punetha Sarmila, N. Gnanambigai et P. Dinadayalan, « Survey on fault tolerant — Load balancing algorithmsin cloud computing », 2015 2nd International Conference on Electronics and Communication Systems (ICECS), IEEE, (ISBN 978-1-4799-7225-8, DOI 10.1109/ecs.2015.7124879, lire en ligne, consulté le )
- ↑ « Load balancer : pour un meilleur temps d’accès au serveur », sur IONOS Digitalguide (consulté le )
- ↑ (en) Derek L Eager, Edward D Lazowska et John Zahorjan, « A comparison of receiver-initiated and sender-initiated adaptive load sharing », Performance Evaluation, vol. 6, no 1, , p. 53–68 (ISSN 0166-5316, DOI 10.1016/0166-5316(86)90008-8, lire en ligne, consulté le )
- ↑ (de) Peter Sanders, « Tree Shaped Computations as a Model for Parallel Applications », sur Workshop on Application Based Load Balancing (ALV '98), München, 25. - 26. März 1998 - Veranst. vom Sonderforschungsbereich 342 "Werkzeuge und Methoden für die Nutzung paralleler Rechnerarchitekturen". Ed.: A. Bode, (DOI 10.5445/ir/1000074497, consulté le )
- 1 2 (en) Nathan J. Muller,Network manager's handbook,McGraw-Hill Professional - 2002, (ISBN 9780071405676)
- 1 2 (en) Hossein Bidgoli,The Internet encyclopedia, Volume 1,John Wiley and Sons - 2004, (ISBN 9780471222026)
- 1 2 3 4 5 (en) Charles Bookman,Linux clustering: building and maintaining Linux clusters,Sams Publishing - 2003, (ISBN 9781578702749)
- 1 2 3 4 (en) Mauricio Arregoces - Maurizio Portolani,Data center fundamentals,Cisco Press - 2003, (ISBN 9781587050237)
Articles connexes
- Round-robin
- Shortest Path Bridging (IEEE 802.1aq)
- CARP
- Virtual Router Redundancy Protocol
- HAProxy, logiciel libre de répartition de charge
- Linux Virtual Server, solution de répartition de charge open-source pour Linux.
- IPVS, répartiteur de charge du noyau linux.
- RAID, répartition au niveau des disques durs
- Grappe de serveurs
- Edge computing
Liens externes