Quand il s'agit de mettre dans un tableau de taille raisonnable (typiquement résidant dans la mémoire principale de l'ordinateur) un ensemble de données de taille variable et arbitraire, on utilise une fonction de hachage pour attribuer à ces données des indices de ce tableau. Par conséquent, une fonction de hachage est une fonction qui associe des valeurs de taille fixe à des données de taille quelconque. Les valeurs renvoyées par une fonction de hachage sont appelées valeurs de hachage, codes de hachage, résumés, signatures ou simplement hachages. Les valeurs sont généralement utilisées pour être les indices d'une table de taille raisonnable appelée table de hachage. Le hachage ou adressage de stockage dispersé est donc l'utilisation d'une fonction de hachage pour créer les indices d'une table de hachage.
Les fonctions de hachage sont utilisées dans les applications de stockage et d'indexation de données pour accéder aux données en un temps réduit, en fait quasi-constant. Elles requièrent un espace de stockage à peine plus grand que l'espace total requis pour les données. Ainsi, le hachage est une forme d'accès aux données efficace en termes de calcul et d'espace de stockage.
L'intérêt des fonctions de hachage repose sur de bonnes propriétés statistiques. En effet, le comportement dans le pire des cas est mauvais, mais il se manifeste avec une probabilité extrêmement faible, en fait négligeable, et le comportement dans le cas moyen est optimal (collision minimale ).
Les fonctions de hachage sont liées (et souvent confondues avec) les sommes de contrôle, les clés de contrôle, les empreintes numériques, la compression avec perte, les générateurs de nombres aléatoires, les codes correcteur et les chiffrements. Bien que les concepts se chevauchent dans une certaine mesure, chacun a ses propres utilisations et exigences et est conçu et optimisé différemment. La fonction de hachage diffère de ces concepts principalement en termes d'intégrité (cryptographie)

Principe général

Une fonction de hachage est typiquement une fonction qui, pour un ensemble de très grande taille (théoriquement infini) et de nature très diversifiée, va renvoyer des résultats aux spécifications précises (en général des chaînes de caractère de taille limitée ou fixe) optimisées pour des applications particulières. Les chaînes permettent d'établir des relations (égalité, égalité probable, non-égalité, ordre...) entre les objets de départ sans accéder directement à ces derniers, en général soit pour des questions d'optimisation (la taille des objets de départ nuit aux performances), soit pour des questions de confidentialité.
Autrement dit : à 1 fichier (ou à 1 mot) va correspondre une signature unique (le résultat de la fonction de hachage).
En termes très concrets, on peut voir une fonction de hachage (non cryptographique) comme un moyen de replier l'espace de données que l'on suppose potentiellement très grand et très peu rempli pour le faire entrer dans la mémoire de l'ordinateur. En revanche, une fonction de hachage cryptographique est ce que l'on appelle une fonction à sens unique, ce qui veut dire que le calcul de la fonction de hachage est facile et rapide tandis que le calcul de sa fonction inverse est infaisable par calcul et donc non calculable en pratique. Grâce à la valeur de hachage, on peut discriminer deux objets apparemment proches, ce qui peut être utilisé pour garantir l'intégrité des objets, autrement dit leur non-modification par une erreur ou un acteur malveillant.
Tables de hachages
Article principal : table de hachage
Les fonctions de hachage sont utilisées conjointement avec des tables de hachage pour stocker et récupérer des éléments de données ou des enregistrements de données. La fonction de hachage traduit chaque donnée ou enregistrement en un indice dans la table de hachage. Lorsqu'un élément n'est pas encore présent dans la table, l'indice donne accès à un emplacement vide (également appelé compartiment), auquel cas l'élément est ajouté à la table à cet endroit. Si la fonction de hachage produit un indice correspondant à un emplacement déjà occupé, il faut résoudre cette « collision » ; le nouvel élément peut être oublié (non ajouté à la table), ou peut remplacer l'ancien élément, ou peut être ajouté à la table à un autre emplacement. Dans ce dernier cas, on utilise une procédure de « remplacement » qui dépend de la structure de la table de hachage. Dans le hachage chaîné, chaque emplacement est la tête d'une liste chaînée, l' élément qui entre en collision est ajouté à la liste chaînée et la recherche dans la liste est linéaire. L'ordre dans la liste chaînée peut être aléatoire ou être un ordre déduit des données, ou être un ordre qui provient de la fréquence des demandes d'accès aux données, afin d'en accélérer l'accès linéaire.
Dans le hachage d'adresse ouvert, la table est sondée à partir de l'emplacement occupé d'une manière spécifiée, généralement par sondage linéaire , sondage quadratique ou double hachage jusqu'à ce qu'un emplacement ouvert soit localisé ou que la table entière soit sondée (débordement). La recherche de l'élément suit la même procédure jusqu'à ce que l'élément soit localisé, qu'un créneau libre soit trouvé ou que le tableau entier ait été recherché (élément absent du tableau).
Utilisations spécialisées
Les fonctions de hachage sont également utilisées pour créer des caches pour les grands ensembles de données stockés sur des supports lents. Un cache est généralement plus simple qu'une table de recherche hachée car toute collision peut être résolue en supprimant ou en réécrivant le plus ancien des deux éléments en collision[3].
Les fonctions de hachage sont un ingrédient essentiel du filtre Bloom, une structure de données probabiliste efficace en espace qui est utilisée pour tester si un élément est membre d'un ensemble .
Un cas particulier de hachage est connu sous le nom de hachage géométrique ou méthode de la grille . Dans ces applications, l'ensemble de toutes les entrées est une sorte d' espace métrique, et la fonction de hachage peut être interprétée comme une partition de cet espace dans une grille de cellules . La table est souvent un tableau avec deux indices ou plus (appelés fichier de grille, index de grille, grille de compartiment et noms similaires), et la fonction de hachage renvoie un tuple d'index . Ce principe est largement utilisé en infographie , en géométrie computationnelle et dans de nombreuses autres disciplines, pour résoudre de nombreux problèmes de proximité dans le plan ou dans l'espace tridimensionnel , tels que la recherche de paires les plus proches dans un ensemble de points, de formes similaires dans une liste de formes, d'images similaires dans une base de données d'images , etc.
Les tables de hachage sont également utilisées pour implémenter des tableaux associatifs et des ensembles dynamiques[4].
Propriétés
Uniformité
Une bonne fonction de hachage doit mapper les entrées attendues aussi uniformément que possible sur sa plage de sortie. Autrement dit, chaque valeur de hachage dans la plage de sortie doit être générée avec à peu près la même probabilité . La raison de cette dernière exigence est que le coût des méthodes basées sur le hachage augmente fortement à mesure que le nombre de collisions (paires d'entrées mappées sur la même valeur de hachage) augmente. Si certaines valeurs de hachage sont plus susceptibles de se produire que d'autres, une plus grande partie des opérations de recherche devra rechercher dans un plus grand ensemble d'entrées de table en collision.
Notez que ce critère exige uniquement que la valeur soit uniformément distribuée , et non aléatoire en aucun cas. Une bonne fonction de randomisation est (à moins de problèmes d'efficacité de calcul) généralement un bon choix en tant que fonction de hachage, mais l'inverse n'est pas nécessairement vrai.
Les tables de hachage ne contiennent souvent qu'un petit sous-ensemble des entrées valides. Par exemple, une liste de membres d'un club peut ne contenir qu'une centaine de noms de membres, sur le très grand nombre de noms possibles. Dans ces cas, le critère d'uniformité doit être valable pour presque tous les sous-ensembles typiques d'entrées qui peuvent être trouvées dans le tableau, et pas seulement pour l'ensemble global de toutes les entrées possibles.
En d'autres termes, si un ensemble typique de m enregistrements est haché en n emplacements de table, la probabilité qu'un seau reçoive beaucoup plus que m / n enregistrements devrait être extrêmement faible. En particulier, si m est inférieur à n , très peu de compartiments doivent avoir plus d'un ou deux enregistrements. Un petit nombre de collisions est pratiquement inévitable, même si n est beaucoup plus grand que m – voir le problème de l'anniversaire .
Dans des cas particuliers où les clés sont connues à l'avance et que l'ensemble de clés est statique, une fonction de hachage peut être trouvée qui atteint une uniformité absolue (ou sans collision). Une telle fonction de hachage est dite hachage parfait. Il n'existe aucun moyen algorithmique de construire une telle fonction - la recherche d'une est une fonction factorielle du nombre de clés à mapper par rapport au nombre d'emplacements de table dans lesquels elles sont exploitées. Trouver une fonction de hachage parfaite sur plus d'un très petit ensemble de clés est généralement irréalisable en termes de calcul; la fonction résultante est susceptible d'être plus complexe en termes de calcul qu'une fonction de hachage standard et ne fournit qu'un avantage marginal par rapport à une fonction avec de bonnes propriétés statistiques qui produit un nombre minimum de collisions. Voir la fonction de hachage universelle.
Tests et mesures
Lors du test d'une fonction de hachage, l'uniformité de la distribution des valeurs de hachage peut être évaluée par le test du chi carré. Ce test est une mesure de la qualité de l'ajustement : il s'agit de la distribution réelle des éléments dans les compartiments par rapport à la distribution attendue (ou uniforme) des éléments. La formule est :
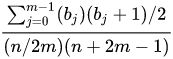
où: "n" est le nombre de clés, "m" est le nombre de seaux, "bj" est le nombre d'articles dans le compartiment "j".
Un rapport dans un intervalle de confiance (0,95 - 1,05) indique que la fonction de hachage évaluée a une distribution uniforme attendue.
Les fonctions de hachage peuvent avoir certaines propriétés techniques qui les rendent plus susceptibles d'avoir une distribution uniforme lorsqu'elles sont appliquées. L'un est le critère strict d'avalanche: chaque fois qu'un seul bit d'entrée est complété, chacun des bits de sortie change avec une probabilité de 50 %. La raison de cette propriété est que des sous-ensembles sélectionnés de l'espace de clés peuvent avoir une faible variabilité. Pour que la sortie soit distribuée uniformément, une faible quantité de variabilité, même un bit, doit se traduire par une grande quantité de variabilité (c'est-à-dire une distribution sur l'espace de table) dans la sortie. Chaque bit doit changer avec une probabilité de 50 % car si certains bits hésitent à changer, les clés se regroupent autour de ces valeurs. Si les bits veulent changer trop facilement, le mappage se rapproche d'une fonction XOR fixe d'un seul bit. Des tests standard pour cette propriété ont été décrits dans la littérature[5]. La pertinence du critère pour une fonction de hachage multiplicative est évaluée ici[6].
Efficacité
Dans les applications de stockage et de récupération de données, l'utilisation d'une fonction de hachage est un compromis entre le temps de recherche et l'espace de stockage des données. Si le temps de recherche était illimité, une liste linéaire non ordonnée très compacte serait le meilleur moyen ; si l'espace de stockage était illimité, une structure accessible de manière aléatoire et indexable par la valeur-clé serait très grande, très clairsemée, mais très rapide. Une fonction de hachage prend un temps fini pour mapper un espace de clés potentiellement grand à une quantité réalisable d'espace de stockage interrogeable dans un laps de temps limité, quel que soit le nombre de clés. Dans la plupart des applications, la fonction de hachage doit être calculable avec un minimum de latence et accessoirement en un minimum d'instructions.
La complexité de calcul varie en fonction du nombre d'instructions requises et de la latence des instructions individuelles, les plus simples étant les méthodes au niveau du bit (pliage), suivies des méthodes multiplicatives, et les plus complexes (les plus lentes) sont les méthodes basées sur la division.
Étant donné que les collisions devraient être peu fréquentes et entraîner un retard marginal mais qu'elles sont par ailleurs inoffensives, il est généralement préférable de choisir une fonction de hachage plus rapide plutôt qu'une fonction nécessitant plus de calculs mais économisant quelques collisions.
Les implémentations basées sur la division peuvent être particulièrement préoccupantes car la division est microprogrammée sur presque toutes les architectures de puces. La division ( modulo ) par une constante peut être inversée pour devenir une multiplication par l'inverse multiplicatif de la taille du mot de la constante. Cela peut être fait par le programmeur ou par le compilateur. La division peut également être réduite directement en une série de soustractions de décalage et d'ajouts de décalage, bien que la minimisation du nombre de ces opérations requises soit un problème de taille; le nombre d'instructions de montage qui en résultent peut être supérieur à une dizaine, et noyer le pipeline. Si l'architecture comporte des unités fonctionnelles de multiplication matérielle, la multiplication par l'inverse est probablement une meilleure approche.
Nous pouvons autoriser la taille de table n à ne pas être une puissance de 2 et ne pas avoir à effectuer d'opération de reste ou de division, car ces calculs sont parfois coûteux. Par exemple, soit n significativement inférieur à 2 b . Considérons une fonction génératrice de nombres pseudo -aléatoires P (clé) uniforme sur l'intervalle [0, 2 b − 1] . Une fonction de hachage uniforme sur l'intervalle [0, n -1] est n P (clé)/2 b . On peut remplacer la division par un décalage de bit à droite (éventuellement plus rapide) : nP(touche) >> b .
Si les clés sont hachées à plusieurs reprises et que la fonction de hachage est coûteuse, le temps de calcul peut être économisé en précalculant les codes de hachage et en les stockant avec les clés. La correspondance des codes de hachage signifie presque certainement que les clés sont identiques. Cette technique est utilisée pour la table de transposition dans les programmes de jeu, qui stocke une représentation hachée 64 bits de la position du plateau.
Universalité
Un schéma de hachage universel est un algorithme aléatoire qui sélectionne une fonction de hachage h parmi une famille de telles fonctions, de telle sorte que la probabilité d'une collision de deux clés distinctes soit 1/ m , où m est le nombre de valeurs de hachage distinctes souhaité—indépendamment des deux touches. Le hachage universel garantit (au sens probabiliste) que l'application de la fonction de hachage se comportera aussi bien que si elle utilisait une fonction aléatoire, pour toute distribution des données d'entrée. Cependant, il aura plus de collisions qu'un hachage parfait et peut nécessiter plus d'opérations qu'une fonction de hachage à usage spécial.
Applicabilité
Une fonction de hachage est applicable dans une variété de situations. Une fonction de hachage qui n'autorise que certaines tailles de table, des chaînes jusqu'à une certaine longueur ou qui ne peut pas accepter de graine (c'est-à-dire autoriser le double hachage) n'est pas aussi utile qu'une autre.
Déterminisme
Une procédure de hachage doit être déterministe , ce qui signifie que pour une valeur d'entrée donnée, elle doit toujours générer la même valeur de hachage. En d'autres termes, il doit être fonction des données à hacher, au sens mathématique du terme. Cette exigence exclut les fonctions de hachage qui dépendent de paramètres variables externes, tels que les générateurs de nombres pseudo-aléatoires ou l'heure de la journée. Il exclut également les fonctions qui dépendent de l'adresse mémoire de l'objet haché dans les cas où l'adresse peut changer pendant l'exécution (comme cela peut arriver sur les systèmes qui utilisent certaines méthodes de récupération de place ), bien que parfois le rehachage de l'élément soit possible.
Le déterminisme est dans le cadre de la réutilisation de la fonction. Par exemple, Python ajoute la fonctionnalité selon laquelle les fonctions de hachage utilisent une graine aléatoire qui est générée une fois lorsque le processus Python démarre en plus de l'entrée à hacher[7]. Le hachage Python ( SipHash ) est toujours une fonction de hachage valide lorsqu'il est utilisé dans une seule exécution. Mais si les valeurs sont persistantes (par exemple, écrites sur le disque), elles ne peuvent plus être traitées comme des valeurs de hachage valides, car lors de la prochaine exécution, la valeur aléatoire peut différer.
Plage définie
Il est souvent souhaitable que la sortie d'une fonction de hachage ait une taille fixe (mais voir ci-dessous). Si, par exemple, la sortie est limitée à des valeurs entières de 32 bits, les valeurs de hachage peuvent être utilisées pour indexer dans un tableau. Un tel hachage est couramment utilisé pour accélérer les recherches de données[8]. La production d'une sortie de longueur fixe à partir d'une entrée de longueur variable peut être réalisée en divisant les données d'entrée en morceaux de taille spécifique. Les fonctions de hachage utilisées pour les recherches de données utilisent une expression arithmétique qui traite de manière itérative des morceaux de l'entrée (tels que les caractères d'une chaîne) pour produire la valeur de hachage.
Plage de variables
Dans de nombreuses applications, la plage de valeurs de hachage peut être différente pour chaque exécution du programme ou peut changer au cours de la même exécution (par exemple, lorsqu'une table de hachage doit être étendue). Dans ces situations, il faut une fonction de hachage qui prend deux paramètres : les données d'entrée z et le nombre n de valeurs de hachage autorisées.
Une solution courante consiste à calculer une fonction de hachage fixe avec une très grande plage (disons, 0 à 2 32 − 1 ), à diviser le résultat par n et à utiliser le reste de la division . Si n est lui-même une puissance de 2 , cela peut être fait par masquage et décalage de bits . Lorsque cette approche est utilisée, la fonction de hachage doit être choisie de manière que le résultat ait une distribution assez uniforme entre 0 et n - 1 , pour toute valeur de n pouvant survenir dans l'application. Selon la fonction, le reste peut n'être uniforme que pour certaines valeurs de n, par exemple nombres impairs ou premiers .
Plage variable avec un minimum de mouvement (fonction de hachage dynamique)
Lorsque la fonction de hachage est utilisée pour stocker des valeurs dans une table de hachage qui survit à l'exécution du programme et que la table de hachage doit être étendue ou réduite, la table de hachage est appelée table de hachage dynamique.
Une fonction de hachage qui déplacera le nombre minimum d'enregistrements lorsque la table est redimensionnée est souhaitable. Ce qu'il faut, c'est une fonction de hachage H ( z , n ) - où z est la clé hachée et n est le nombre de valeurs de hachage autorisées - telle que H ( z , n + 1) = H ( z , n ) avec probabilité proche de n /( n + 1) .
Le hachage linéaire et le stockage en spirale sont des exemples de fonctions de hachage dynamiques qui s'exécutent en temps constant mais relâchent la propriété d'uniformité pour obtenir la propriété de mouvement minimal. Le hachage extensible utilise une fonction de hachage dynamique qui nécessite un espace proportionnel à n pour calculer la fonction de hachage, et il devient une fonction des clés précédentes qui ont été insérées. Plusieurs algorithmes qui préservent la propriété d'uniformité mais nécessitent un temps proportionnel à n pour calculer la valeur de H ( z , n ) ont été inventés.
Une fonction de hachage avec un minimum de mouvement est particulièrement utile dans les tables de hachage distribuées .
Normalisation des données
Dans certaines applications, les données d'entrée peuvent contenir des caractéristiques qui ne sont pas pertinentes à des fins de comparaison. Par exemple, lors de la recherche d'un nom personnel, il peut être souhaitable d'ignorer la distinction entre les majuscules et les minuscules. Pour de telles données, il faut utiliser une fonction de hachage compatible avec le critère d' équivalence des données utilisé : c'est-à-dire que deux entrées considérées comme équivalentes doivent produire la même valeur de hachage. Cela peut être accompli en normalisant l'entrée avant de la hacher, comme en majuscule toutes les lettres.
Hachage des types de données entiers
Il existe plusieurs algorithmes courants pour le hachage des entiers. La méthode donnant la meilleure distribution dépend des données. L'une des méthodes les plus simples et les plus courantes dans la pratique est la méthode de division modulo.
Fonction de hachage d'identité
Si les données à hacher sont suffisamment petites, on peut utiliser les données elles-mêmes (réinterprétées comme un entier) comme valeur hachée. Le coût de calcul de cette fonction de hachage d' identité est effectivement nul. Cette fonction de hachage est parfaite , car elle mappe chaque entrée à une valeur de hachage distincte.
La signification de "suffisamment petit" dépend de la taille du type utilisé comme valeur hachée. Par exemple, en Java , le code de hachage est un entier 32 bits. Ainsi, les objets entiers Integer32 bits et virgule flottante 32 bits Floatpeuvent simplement utiliser directement la valeur ; alors que l'entier Long64 bits et la virgule flottante 64 bits Doublene peuvent pas utiliser cette méthode.
D'autres types de données peuvent également utiliser ce schéma de hachage. Par exemple, lors du mappage de chaînes de caractères entre majuscules et minuscules , on peut utiliser l'encodage binaire de chaque caractère, interprété comme un entier, pour indexer une table qui donne la forme alternative de ce caractère ("A" pour "a", " 8" pour "8", etc.). Si chaque caractère est stocké sur 8 bits (comme en ASCII étendu ou ISO Latin 1 ), la table n'a que 2 8 = 256 entrées ; dans le cas des caractères Unicode , le tableau aurait 17×2 16 =1 114 112 entrées.
La même technique peut être utilisée pour mapper des codes de pays à deux lettres comme "us" ou "za" aux noms de pays (26 2 = 676 entrées de table), des codes postaux à 5 chiffres comme 13083 aux noms de ville (100 000 entrées), etc. Les valeurs de données non valides (telles que le code de pays "xx" ou le code postal 00000) peuvent être laissées non définies dans le tableau ou mappées à une valeur "null" appropriée.
Pliage
Un code de hachage pliant est produit en divisant l'entrée en n sections de m bits, où 2 m est la taille de la table, et en utilisant une opération au niveau du bit préservant la parité telle que ADD ou XOR pour combiner les sections, suivies d'un masque ou de décalages vers coupez tous les bits en excès à l'extrémité supérieure ou inférieure. Par exemple, pour une taille de table de 15 bits et une valeur de clé de 0x0123456789ABCDEF, il existe cinq sections composées de 0x4DEF, 0x1357, 0x159E, 0x091A et 0x8. En ajoutant, nous obtenons 0x7AA4, une valeur de 15 bits.
Carrés médians
Un code de hachage à carrés moyens est produit en mettant au carré l'entrée et en extrayant un nombre approprié de chiffres ou de bits du milieu. Par exemple, si l'entrée est 123 456 789 et que la taille de la table de hachage est de 10 000, la mise au carré de la clé produit 15 241 578 750 190 521, de sorte que le code de hachage est pris comme les 4 chiffres du milieu du nombre à 17 chiffres (en ignorant le chiffre supérieur) 8750. produit un code de hachage raisonnable s'il n'y a pas beaucoup de zéros à gauche ou à droite dans la clé. Il s'agit d'une variante du hachage multiplicatif, mais pas aussi bonne car une clé arbitraire n'est pas un bon multiplicateur.
Hachage de division
Une technique standard consiste à utiliser une fonction modulo sur la clé, en sélectionnant un diviseur qui est un nombre premier proche de la taille de la table, donc . La taille de la table est généralement une puissance de 2. Cela donne une distribution de . Cela donne de bons résultats sur un grand nombre de jeux de clés. Un inconvénient important du hachage de division est que la division est microprogrammée sur la plupart des architectures modernes, y compris x86, et peut être 10 fois plus lente que la multiplication. Un deuxième inconvénient est qu'il ne brisera pas les clés en cluster. Par exemple, les clés 123000, 456000, 789000, etc. modulo 1000 correspondent toutes à la même adresse. Cette technique fonctionne bien dans la pratique car de nombreux ensembles de clés sont déjà suffisamment aléatoires et la probabilité qu'un ensemble de clés soit cyclique par un grand nombre premier est faible.



Hachage multiplicatif
Le hachage multiplicatif standard utilise la formule qui produit une valeur de hachage dans . La valeur est une valeur choisie qui devrai être première à ; elle doit être grande et sa représentation binaire est un mélange aléatoire de 0 et de 1. Un cas particulier se présente lorsque et sont des puissances de 2 et est la word size de la machine. Dans ce cas cette formule devient . C'est particulier car l'arithmétique modulo se fait par défaut dans les langages de programmation de bas niveau et la division entière par une puissance de 2 est simplement un décalage vers la droite, donc, en C, par exemple, cette fonction devient









unsigned hash(unsigned K)
{
return (a*K) >> (w-m);
}
et pour et cela se traduit par une simple multiplication d'entiers et un décalage vers la droite, ce qui en fait l'une des fonctions de hachage les plus rapides à calculer.

Le hachage multiplicatif est susceptible d'une «erreur courante» qui conduit à une mauvaise diffusion - les bits d'entrée de valeur supérieure n'affectent pas les bits de sortie de valeur inférieure. Une transmutation sur l'entrée qui décale l'étendue des bits supérieurs retenus vers le bas et les XOR ou les ADD à la clé avant que l'étape de multiplication ne corrige cela. La fonction résultante ressemble donc à :
unsigned hash(unsigned K)
{
K ^= K >> (w-m);
return (a*K) >> (w-m);
}
Hachage Fibonacci
Le hachage de Fibonacci est une forme de hachage multiplicatif dans lequel le multiplicateur est , où est la longueur du mot machine et est le nombre d'or (environ 5/3). Une propriété de ce multiplicateur est qu'il distribue uniformément sur l'espace table, des blocs de clés consécutives par rapport à n'importe quel bloc de bits dans la clé. Les clés consécutives dans les bits de poids fort ou les bits de poids faible de la clé (ou d'un autre champ) sont relativement fréquentes. Les multiplicateurs pour différentes longueurs de mots sont:


- 16: a=40503
- 32: a=2654435769
- 48: a=173961102589771
- 64: a=11400714819323198485
Hachage de données de longueur variable
Lorsque les valeurs de données sont des chaînes de caractères longues (ou de longueur variable), telles que des noms personnels, des adresses de pages Web ou des messages électroniques, leur distribution est généralement très inégale, avec des dépendances compliquées. Par exemple, le texte dans n'importe quelle langue naturelle a des distributions hautement non uniformes de caractères et de paires de caractères , caractéristiques de la langue. Pour de telles données, il est prudent d'utiliser une fonction de hachage qui dépend de tous les caractères de la chaîne et dépend de chaque caractère d'une manière différente.
Milieu et extrémités
Les fonctions de hachage simplistes peuvent ajouter les n premiers et derniers caractères d'une chaîne avec la longueur, ou former un hachage de la taille d'un mot à partir des 4 caractères du milieu d'une chaîne. Cela évite d'itérer sur la chaîne (potentiellement longue), mais les fonctions de hachage qui ne hachent pas tous les caractères d'une chaîne peuvent facilement devenir linéaires en raison de redondances, de regroupements ou d'autres pathologies dans le jeu de clés. De telles stratégies peuvent être efficaces en tant que fonction de hachage personnalisée si la structure des clés est telle que le milieu, les extrémités ou d'autres champs valent zéro ou une autre constante invariante qui ne différencie pas les clés ; alors les parties invariantes des clés peuvent être ignorées.
Pliage des caractères
L'exemple paradigmatique du pliage par caractères consiste à additionner les valeurs entières de tous les caractères de la chaîne. Une meilleure idée consiste à multiplier le total de hachage par une constante, généralement un nombre premier important, avant d'ajouter le caractère suivant, en ignorant le débordement. L'utilisation d'un 'ou' exclusif au lieu d'ajouter est également une alternative plausible. L'opération finale serait un modulo, un masque ou une autre fonction pour réduire la valeur du mot à un index de la taille de la table. La faiblesse de cette procédure est que les informations peuvent se regrouper dans les bits supérieurs ou inférieurs des octets, lequel regroupement restera dans le résultat haché et provoquera plus de collisions qu'un hachage aléatoire approprié. Les codes d'octets ASCII, par exemple, ont un bit supérieur de 0 et les chaînes imprimables n'utilisent pas les 32 premiers codes d'octets,
L'approche classique surnommée le hachage PJW basé sur le travail de Peter. J. Weinberger chez ATT Bell Labs dans les années 1970, a été initialement conçu pour hacher les identifiants dans les tables de symboles du compilateur comme indiqué dans le Dragon book. Cette fonction de hachage compense les octets de 4 bits avant de les AJOUTER ensemble. Lorsque la quantité s'enroule, les 4 bits de poids fort sont décalés et s'ils ne sont pas nuls, XOR est renvoyé dans l'octet de poids faible de la quantité cumulée. Le résultat est un code de hachage de taille de mot auquel un modulo ou une autre opération de réduction peut être appliquée pour produire l'index de hachage final.
Aujourd'hui, en particulier avec l'avènement des tailles de mots de 64 bits, un hachage de chaînes de longueur variable beaucoup plus efficace par blocs de mots est disponible.
Pliage de longueur de mot
Les microprocesseurs modernes permettront un traitement beaucoup plus rapide si les chaînes de caractères 8 bits ne sont pas hachées en traitant un caractère à la fois, mais en interprétant la chaîne comme un tableau d'entiers 32 bits ou 64 bits et en hachant/accumulant ces "mot large" valeurs entières au moyen d'opérations arithmétiques (par exemple, multiplication par constante et décalage de bits). Le mot final, qui peut avoir des positions d'octet inoccupées, est rempli de zéros ou d'une valeur "randomisée" spécifiée avant d'être replié dans le hachage. Le code de hachage accumulé est réduit par un modulo final ou une autre opération pour produire un index dans la table.
Hachage de conversion de base
De manière analogue à la façon dont une chaîne de caractères ASCII ou EBCDIC représentant un nombre décimal est convertie en une quantité numérique pour le calcul, une chaîne de longueur variable peut être convertie en ( x 0 a k −1 + x 1 a k −2 +...+ X k -2 une + X k -1 ) . Il s'agit simplement d'un polynôme dans une base a > 1 qui prend les composantes ( x 0 , x 1 ,..., x k −1 ) comme caractères de la chaîne d'entrée de longueur k . Il peut être utilisé directement comme code de hachage, ou une fonction de hachage lui est appliquée pour mapper la valeur potentiellement grande à la taille de la table de hachage. La valeur de a est généralement un nombre premier au moins suffisamment grand pour contenir le nombre de caractères différents dans le jeu de caractères des clés potentielles. Le hachage de conversion de base des chaînes minimise le nombre de collisions[9]. Les tailles de données disponibles peuvent limiter la longueur maximale de chaîne pouvant être hachée avec cette méthode. Par exemple, un double mot long de 128 bits ne hachera qu'une chaîne alphabétique de 26 caractères (sans tenir compte de la casse) avec une base de 29 ; une chaîne ASCII imprimable est limitée à 9 caractères en utilisant la base 97 et un mot long de 64 bits. Cependant, les clés alphabétiques sont généralement de longueur modeste, car les clés doivent être stockées dans la table de hachage. Les chaînes de caractères numériques ne posent généralement pas de problème ; 64 bits peuvent compter jusqu'à 10 19 , soit 19 chiffres décimaux de base 10.
Analyse
Le résultat du pire cas pour une fonction de hachage peut être évalué de deux manières : théorique et pratique. Le pire cas théorique est la probabilité que toutes les clés correspondent à un seul emplacement. Dans le pire des cas pratiques, on s'attend à la plus longue séquence de sondes (fonction de hachage + méthode de résolution de collision). Cette analyse prend en compte le hachage uniforme, c'est-à-dire que toute clé sera mappée sur un emplacement particulier avec une probabilité de 1/ m , caractéristique des fonctions de hachage universelles.
Alors que Knuth s'inquiète d'une attaque contradictoire sur les systèmes en temps réel, Gonnet a montré que la probabilité d'un tel cas est « ridiculement petite ». Sa représentation était que la probabilité que k de n clés correspondent à un seul emplacement estoù α est le facteur de charge, n / m .
Notes et références
- ↑ Hachage effectué en ligne par l'outil proposé par le site Defuse.ca.
- ↑ Vingt mille lieues sous les mers, projet Gutenberg, consulté le 14/09/2017
- ↑ (en) Stokes, Jon, « Understanding CPU caching and performance », Ars Technica, (lire en ligne)
- ↑ (en) Menezes, Alfred J.; van Oorschot, Paul C.; Vanstone, Scott A, Handbook of Applied Cryptography, CRC Press, (ISBN 978-0849385230, lire en ligne)
- ↑ (en) Castro, et.al., « The strict avalanche criterion randomness test », ScienceDirect, (lire en ligne)
- ↑ (en) Malte Sharupke, « Fibonacci Hashing: The Optimization that the World Forgot », Probably Dance, (lire en ligne)
- ↑ (en) « Data model - Python 3.6.1 documentation »
- ↑ (en) Sedgewick, Robert, 14. Hashing". Algorithms in Java (3 ed.), (ISBN 978-0201361209)
- ↑ (en) Ramakrishna, M. V.; Zobel, Justin, Performance in Practice of String Hashing Functions,
Stokes, Jon (2002-07-08). "Understanding CPU caching and performance". Ars Technica. Retrieved 2022-02-06.
Annexes
Bibliographie
(en) Donald E. Knuth, The Art of Computer Programming, vol. 3 : Sorting and Searching, , 2e éd. [détail de l’édition], chap. 6 Searching, section 6.4 Hashing