| Créateur | Doug Cutting et Mike Cafarella (en) |
|---|---|
| Développé par | Apache Software Foundation |
| Première version | [1] |
| Dernière version |
2.10.2 ()[2] 3.2.4 ()[3] 3.3.6 ()[4] |
| Dépôt | git-wip-us.apache.org/repos/asf/hadoop.git, gitbox.apache.org/repos/asf?p=hadoop.git et github.com/apache/hadoop |
| Écrit en | Java |
| Système d'exploitation | Multiplateforme et POSIX |
| Environnement | Machine virtuelle Java |
| Type | Framework |
| Licence | Licence Apache version 2.0 et licence publique générale GNU |
| Documentation | cwiki.apache.org/confluence/display/hadoop |
| Site web | hadoop.apache.org |
Hadoop est un framework libre et open source écrit en Java destiné à faciliter la création d'applications distribuées (au niveau du stockage des données et de leur traitement) et échelonnables (scalables) permettant aux applications de travailler avec des milliers de nœuds et des pétaoctets de données. Ainsi chaque nœud est constitué de machines standard regroupées en grappe. Tous les modules de Hadoop sont conçus selon l'idée que les pannes matérielles sont fréquentes et qu'en conséquence elles doivent être gérées automatiquement par le framework.
Hadoop a été inspiré par la publication de MapReduce, GoogleFS et BigTable de Google. Hadoop a été créé par Doug Cutting et fait partie des projets de la fondation logicielle Apache depuis 2009.
Le noyau d'Hadoop est constitué d'une partie de stockage : HDFS (Hadoop Distributed File System), et d'une partie de traitement appelée MapReduce. Hadoop fractionne les fichiers en gros blocs et les distribue à travers les nœuds du cluster. Pour traiter les données, il transfère le code à chaque nœud et chaque nœud traite les données dont il dispose. Cela permet de traiter l'ensemble des données plus rapidement et plus efficacement que dans une architecture supercalculateur plus classique qui repose sur un système de fichiers parallèle où les calculs et les données sont distribués via les réseaux à grande vitesse.
Le framework Hadoop de base se compose des modules suivants :
- Hadoop Common ;
- Hadoop Distributed File System (HDFS), système de fichiers ;
- Hadoop YARN ;
- Hadoop MapReduce ;
Le terme Hadoop se réfère non seulement aux modules de base ci-dessus, mais aussi à son écosystème et à l'ensemble des logiciels qui viennent s'y connecter comme Apache Pig, Apache Hive, Apache HBase, Apache Phoenix, Apache Spark, Apache ZooKeeper, Apache Impala, Apache Flume, Apache Sqoop, Apache Oozie, Apache Storm.
Historique
En 2004[5], Google publie un article présentant son algorithme basé sur des opérations analytiques à grande échelle sur un grand cluster de serveurs, le MapReduce, ainsi que son système de fichier en cluster, le GoogleFS. Doug Cutting, qui travaille à cette époque sur le développement de Apache Lucene et rencontre des problèmes similaires à ceux de la firme de Mountain View, décide alors de reprendre les concepts décrits dans l'article pour développer sa propre version des outils en version open source, qui deviendra le projet Hadoop.
Il s'inspire du doudou de son fils de cinq ans, un éléphant jaune, pour le logo ainsi que pour le nom de ce nouveau framework Java[6].
En 2006, Doug Cutting rejoint Yahoo! avec le projet Nutch et les idées basées sur les premiers travaux de Google en termes de traitement et de stockage de données distribuées[7].
En 2008, Yahoo proposa Hadoop sous la forme d’un projet open source.
En 2011[8], Hadoop en sa version 1.0.0 voit le jour; en date du .
Le , la communauté open source lance Hadoop 2.0[8] celle-ci fut proposée au public à partir de novembre 2012 dans le cadre du projet Apache, sponsorisé par la Apache Software Foundation[7]. La révolution majeure a été l'ajout de la couche YARN dans la structure de Hadoop.
À partir de , la version 3.0.0-alpha1 est rendue disponible[8].
| Version | Date de sortie initiale | Dernière version | Date de sortie |
|---|---|---|---|
| 0.10 | 0.10.1 | 11 janvier 2007 | |
| 0.11 | 0.11.2 | 16 février 2007 | |
| 0.12 | 2 mars 2007 | 0.12.3 | 6 avril 2007 |
| 0.13 | 4 juin 2007 | 0.13.1 | 23 juillet 2007 |
| 0.14 | 4 septembre 2007 | 0.14.4 | 26 novembre 2007 |
| 0.15 | 29 octobre 2007 | 0.15.3 | 18 janvier 2008 |
| 0.16 | 7 février 2008 | 0.16.4 | 5 mai 2008 |
| 0.17 | 20 mai 2008 | 0.17.2 | 19 août 2008 |
| 0.18 | 22 août 2008 | 0.18.3 | 29 janvier 2009 |
| 0.19 | 21 novembre 2008 | 0.19.2 | 23 juillet 2009 |
| 0.20 | 22 avril 2009 | 0.20.205.0 | 17 octobre 2011 |
| 0.21 | 11 mai 2011 | 0.21.0 | |
| 0.22 | 10 décembre 2011 | 0.22.0 | |
| 0.23 | 11 novembre 2011 | 0.23.11 | 27 juin 2014 |
| 1.0 | 27 décembre 2011 | 1.0.4 | 2012-10-12 |
| 1.1 | 13 octobre 2012 | 1.1.2 | 15 février 2013 |
| 1.2 | 13 mai 2013 | 1.2.1 | 1er août 2013 |
| 2.0 | 23 mai 2012 | 2.0.6-alpha | 23 août 2013 |
| 2.1 | 25 août 2013 | 2.1.1-beta | 23 septembre 2013 |
| 2.2 | 11 décembre 2013 | 2.2.0 | |
| 2.3 | 20 février 2014 | 2.3.0 | |
| 2.4 | 7 avril 2014 | 2.4.1 | 30 juin 2014 |
| 2.5 | 11 août 2014 | 2.5.2 | 19 novembre 2014 |
| 2.6 | 18 novembre 2014 | 2.6.5 | 9 octobre 2016 |
| 2.7 | 21 avril 2015 | 2.7.7 | 31 mai 2018 |
| 2.8 | 22 mars 2017 | 2.8.5 | 15 septembre 2018 |
| 2.9 | 17 décembre 2017 | 2.9.2 | 19 novembre 2018 |
| 2.10 | 29 octobre 2019 | 2.10.2 | 31 mai 2022[9] |
| 3.0 | 13 décembre 2017[10] | 3.0.3 | 31 mai 2018[11] |
| 3.1 | 6 avril 2018 | 3.1.4 | 3 août 2020[12] |
| 3.2 | 16 janvier 2019 | 3.2.4 | 22 juillet 2022[13] |
| 3.3 | 14 juillet 2020 | 3.3.6 | 23 juin 2023[14] |
| 3.4 | 3.4.0-SNAPSHOT | 25 octobre 2023[15] | |
Légende : Ancienne version Ancienne version, toujours prise en charge Dernière version stable Dernière version avancée Version future | |||
Architecture
Hadoop Distributed File System
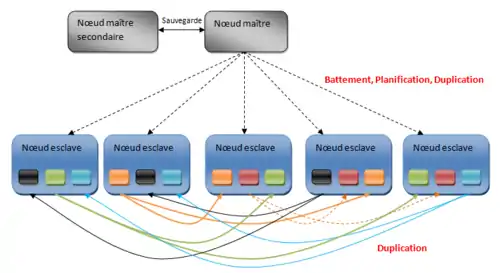
Le HDFS est un système de fichiers distribué, extensible et portable développé par Hadoop à partir du GoogleFS. Écrit en Java, il a été conçu pour stocker de très gros volumes de données sur un grand nombre de machines équipées de disques durs banalisés. Il permet l'abstraction de l'architecture physique de stockage, afin de manipuler un système de fichiers distribué comme s'il s'agissait d'un disque dur unique.
Une architecture de machines HDFS (aussi appelée cluster HDFS) repose sur deux types de composants majeurs :
- NameNode
- nœud de noms, ce composant gère l'espace de noms, l'arborescence du système de fichiers et les métadonnées des fichiers et des répertoires. Il centralise la localisation des blocs de données répartis dans le cluster. Il est unique mais dispose d'une instance secondaire qui gère l'historique des modifications dans le système de fichiers (rôle de backup). Ce NameNode secondaire permet la continuité du fonctionnement du cluster Hadoop en cas de panne du NameNode d'origine.
- DataNode
- nœud de données, ce composant stocke et restitue les blocs de données. Lors du processus de lecture d'un fichier, le NameNode est interrogé pour localiser l'ensemble des blocs de données. Pour chacun d'entre eux, le NameNode renvoie l'adresse du DataNode le plus accessible, c'est-à-dire le DataNode qui dispose de la plus grande bande passante. Les DataNodes communiquent de manière périodique au NameNode la liste des blocs de données qu'ils hébergent. Si certains de ces blocs ne sont pas assez répliqués dans le cluster, l'écriture de ces blocs s'effectue en cascade par copie sur d'autres.
Chaque DataNode sert de bloc de données sur le réseau en utilisant un protocole spécifique au HDFS. Le système de fichiers utilise la couche TCP/IP pour la communication. Les clients utilisent le Remote Procedure Call pour communiquer entre eux. Le HDFS stocke les fichiers de grande taille sur plusieurs machines. Il réalise la fiabilité en répliquant les données sur plusieurs hôtes et par conséquent ne nécessite pas de stockage RAID sur les hôtes. Avec la valeur par défaut de réplication, les données sont stockées sur trois nœuds : deux sur le même support et l'autre sur un support différent. Les DataNodes peuvent communiquer entre eux afin de rééquilibrer les données et de garder un niveau de réplication des données élevé.
Le HDFS n'est pas entièrement conforme aux spécifications POSIX, en effet les exigences relatives à un système de fichiers POSIX diffèrent des objectifs cibles pour une application Hadoop. Le compromis de ne pas avoir un système de fichiers totalement compatible POSIX permet d'accroître les performances du débit de données.
Le HDFS a récemment amélioré ses capacités de haute disponibilité, ce qui permet désormais au serveur de métadonnées principal d'être basculé manuellement sur une sauvegarde en cas d'échec (le basculement automatique est en cours d'élaboration). Les NameNodes étant le point unique pour le stockage et la gestion des métadonnées, ils peuvent être un goulot d'étranglement pour soutenir un grand nombre de fichiers, notamment lorsque ceux-ci sont de petite taille. En acceptant des espaces de noms multiples desservis par des NameNodes séparés, le HDFS limite ce problème.
MapReduce
Hadoop dispose d'une implémentation complète du concept du MapReduce.
HBase
HBase est une base de données distribuée disposant d'un stockage structuré pour les grandes tables.
Comme BigTable, HBase est une base de données orientée colonnes.
ZooKeeper
ZooKeeper est un logiciel de gestion de configuration pour systèmes distribués, basé sur le logiciel Chubby développé par Google. ZooKeeper est utilisé entre autres pour l'implémentation de HBase.
Hive
Hive est un logiciel d'analyse de données permettant d'utiliser Hadoop avec une syntaxe proche du SQL. Hive a été initialement développé par Facebook.
Pig
Pig est un logiciel d'analyse de données comparable à Hive, mais qui utilise le langage Pig Latin. Pig a été initialement développé par Yahoo!.
Utilisations
Plusieurs grands noms de l'informatique ont déclaré utiliser Hadoop, comme Facebook, Yahoo, Microsoft[16]. Yahoo exploite le plus grand cluster Hadoop au monde, avec plus de 100 000 CPU et 40 000 machines dédiées à cette technologie[17].
WikiTrends est un service gratuit d'analyse d'audience de l'encyclopédie Wikipédia lancé en . L'application, utilisant notamment Hadoop, permet de quantifier les thématiques les plus recherchées par les utilisateurs sur l'encyclopédie Wikipédia, au travers d'une interface de visualisation graphique[18],[19],[20].
Hadoop et le cloud
Hadoop peut être déployé dans un datacenter traditionnel mais aussi au travers du cloud[21]. Le cloud permet aux organisations de déployer Hadoop sans acquisition de matériel ou d'expertise spécifique.
Microsoft Azure
Azure HDInsight[22] est un service qui déploie Hadoop sur Microsoft Azure. HDInsight utilise Hortonworks Data Platform (HDP). HDInsight permet la programmation d'extensions en .NET (en plus du Java). HDInsight prend également en charge la création de clusters Hadoop utilisant Ubuntu.
En utilisant HDInsight dans le cloud, les entreprises peuvent exécuter le nombre de nœuds qu'elles souhaitent ; elles seront facturées en fonction du calcul et du stockage qui est utilisé. Les implémentations HDP peuvent également déplacer des données à partir d'un centre de données local vers le cloud pour la sauvegarde, le développement, les tests et les scénarios de rupture. Il est également possible d'exécuter des clusters HDP sur des machines virtuelles Azure.
Amazon EC2/S3 services
Il est possible d'exécuter Hadoop sur Amazon Elastic Compute Cloud (EC2) et sur Amazon Simple Storage Service (S3). À titre d'exemple, le New York Times a utilisé 100 instances Amazon EC2 et une application d'Hadoop pour traiter 4 To d'images raw TIFF (stockées dans Amazon S3) dans 11 millions de fichiers PDF.
Distributions
Hadoop est notamment distribué par quatre acteurs qui proposent des services de formation et un support commercial, mais également des fonctions supplémentaires :
- Cloudera[23] – La première distribution historique d'Hadoop qui intègre les packages classiques et certains développements propriétaires comme Cloudera Impala. C'est un service de formation et de support ;
- Hortonworks – Un service de formation et de support. Il n'est pas présent en France en 2013.
- MapR Technologies – MapR a développé un système de fichiers pour Hadoop palliant les limites du HDFS. MapR a également développé des technologies permettant la suppression du NameNode qui est un point de contention dans l'architecture Hadoop. Un cluster MapR est donc hautement disponible et permet également d'être intégré dans les politiques de sauvegarde des données des entreprises. Un cluster MapR est vu sur le réseau des clients comme un NAS partageant les données en NFS avec des droits POSIX. Il est à l'origine du projet Drill. Ouverture des activités européennes en . Il existe un bureau en France depuis ;
- IBM BigInsights for Hadoop – 100 % open source Apache Hadoop, propose des extensions analytiques et d'intégration dans les systèmes d'information d'entreprise. Il est disponible en France depuis 2010.
Notes et références
- ↑ « https://archive.apache.org/dist/hadoop/common/ »
- ↑ « Release 2.10.2 available » (consulté le )
- ↑ « Release 3.2.4 available » (consulté le )
- ↑ « Release 3.3.6 available » (consulté le )
- ↑ « Google Research Publication: MapReduce », sur research.google.com (consulté le )
- ↑ (en) « Hadoop Daddy Doug Cutting says there's an elephant in the room », The Register, (lire en ligne)
- 1 2 « Hadoop - Tout savoir sur la principale plateforme Big Data », sur www.lebigdata.fr (consulté le )
- 1 2 3 « Apache Hadoop Releases », sur hadoop.apache.org (consulté le )
- ↑ (en) « Release 2.10.2 available », sur hadoop.apache.org
- ↑ (en) « Release 3.0.0 generally available », sur hadoop.apache.org
- ↑ (en) « Release 3.0.3 available », sur hadoop.apache.org
- ↑ (en) « Release 3.1.4 available », sur hadoop.apache.org
- ↑ (en) « Release 3.2.4 available », sur hadoop.apache.org
- ↑ (en) « Release 3.3.6 available », sur hadoop.apache.org
- ↑ (en) « Apache Hadoop 3.4.0-SNAPSHOT », sur apache.github.io
- ↑ Liste d'entreprises déclarant utiliser Hadoop
- ↑ Apache.org, Utilisation d'Hadoop à travers le monde.
- ↑ « WikiTrends, première application Big Data à restituer plus de 21 To de statistiques en temps réel » [PDF], sur www.itrpress.com, (consulté le )
- ↑ Christophe Cerqueira (directeur du pôle Ingensi - groupe Cyrès), « WikiTrends, l'application Big Data “French Touch” », sur www.channelbp.com, (consulté le )
- ↑ Marlène Duretz, « Même pas mal », Le Monde, (lire en ligne)
- ↑ https://azure.microsoft.com/en-us/solutions/hadoop/
- ↑ https://azure.microsoft.com/en-us/services/hdinsight/
- ↑ Site officiel de Cloudera, présentant son service de formation et de support
Voir aussi
Articles connexes
- Apache Mesos
Liens externes
- (en) Site officiel