MapReduce est un patron de conception de développement informatique, inventé par Google[1], dans lequel sont effectués des calculs parallèles, et souvent distribués, de données potentiellement très volumineuses, typiquement supérieures en taille à un téraoctet.
Les termes « map » et « reduce », et les concepts sous-jacents, sont empruntés aux langages de programmation fonctionnelle utilisés pour leur construction (map et réduction de la programmation fonctionnelle et des langages de programmation tableau).
MapReduce permet de manipuler de grandes quantités de données en les distribuant dans un cluster de machines pour être traitées. Ce modèle connaît un vif succès auprès de sociétés possédant d'importants centres de traitement de données telles Amazon.com ou Facebook. Il commence aussi à être utilisé au sein du Cloud computing. De nombreux frameworks ont vu le jour afin d'implémenter le MapReduce. Le plus connu est Hadoop qui a été développé par Apache Software Foundation. Mais ce framework possède des inconvénients qui réduisent considérablement ses performances notamment en milieu hétérogène. Des frameworks permettant d'améliorer les performances de Hadoop ou les performances globales du MapReduce, tant en termes de vitesse de traitement qu'en consommation électrique, commencent à voir le jour.
Présentation
Un modèle de programmation
MapReduce est un modèle de programmation popularisé par Google. Il est principalement utilisé pour la manipulation et le traitement d’un nombre important de données au sein d’un cluster de nœuds.
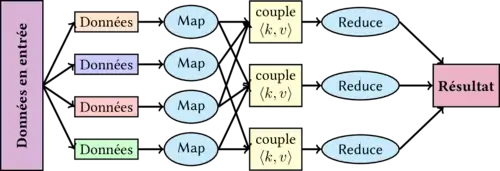
MapReduce consiste en deux fonctions map() et reduce().
- Dans l'étape Map, le nœud analyse un problème, le découpe en sous-problèmes, et le délègue à d'autres nœuds (qui peuvent en faire de même récursivement). Les sous-problèmes sont ensuite traités par les différents nœuds à l'aide de la fonction Map qui à un couple (clé, valeur) associe un ensemble de nouveaux couples (clé, valeur) : map(clé1,valeur1) → list(clé2,valeur2)
// En pseudo code cela donnerait Map(void * document) { int cles = 1; foreach mot in document calculIntermediaire(mot, cles); } - Vient ensuite l'étape Reduce, où les nœuds les plus bas font remonter leurs résultats au nœud parent qui les avait sollicités. Celui-ci calcule un résultat partiel à l'aide de la fonction Reduce (réduction) qui associe toutes les valeurs correspondantes à la même clé à une unique paire (clé, valeur). Puis il remonte l'information à son tour.
À la fin du processus, le nœud d'origine peut recomposer une réponse au problème qui lui avait été soumis : reduce(key2,list(valeur2))→ valeur2[2]// En pseudo code cela donnerait Reduce(int cles, Iterator values) { int result = 0; foreach v in values result += v; }
Un cluster MapReduce utilise une architecture de type Maître-esclave où un nœud maître dirige tous les nœuds esclaves.
MapReduce possède quelques caractéristiques[3] :
- Le modèle de programmation du MapReduce est simple mais très expressif. Bien qu’il ne possède que deux fonctions, map() et reduce(), elles peuvent être utilisées pour de nombreux types de traitement des données, les fouilles de données, les graphes… Il est indépendant du système de stockage et peut manipuler de nombreux types de variable.
- Le système découpe automatiquement les données en entrée en bloc de données de même taille. Puis, il planifie l’exécution des tâches sur les nœuds disponibles.
- Il fournit une tolérance aux fautes à grain fin grâce à laquelle il peut redémarrer les nœuds ayant rencontré une erreur ou affecter la tâche à un autre nœud.
- La parallélisation est invisible à l'utilisateur afin de lui permettre de se concentrer sur le traitement des données[4]
Une fois qu'un nœud a terminé une tâche, on lui affecte un nouveau bloc de données. Grâce à cela, un nœud rapide fera beaucoup plus de calculs qu'un nœud plus lent. Le nombre de tâches Map ne dépend pas du nombre de nœuds, mais du nombre de blocs de données en entrée. Chaque bloc se fait assigner une seule tâche Map. De plus, toutes les tâches Map n'ont pas besoin d'être exécutées en même temps en parallèle, les tâches Reduce suivent la même logique. Par exemple, si des données en entrée sont divisées en 400 blocs et qu'il y a 40 nœuds dans le cluster, le nombre de tâches Map sera de 400. Il faudra alors 10 vagues de Map pour réaliser le mapping des données[4],[5].
Le MapReduce est apparu en 2004. La technologie est encore jeune. Elle souffre de quelques points faibles[6] :
- Elle ne supporte pas les langages haut niveau comme le SQL
- Elle ne gère pas les index. Une tâche MapReduce peut travailler une fois les données en entrée stockées dans sa mémoire. Cependant, MapReduce a besoin d'analyser chaque donnée en entrée afin de la transformer en objet pour la traiter, ce qui provoque des baisses de performance.
- Elle utilise un seul flot de données. MapReduce est facile à utiliser avec une seule abstraction mais seulement avec un flot de donnée fixe. Par conséquent, certains algorithmes complexes sont difficiles à implémenter avec seulement les méthodes map() et reduce(). De plus, les algorithmes qui requièrent de multiples éléments en entrée ne sont pas bien supportés car le flot de données du MapReduce est prévu pour lire un seul élément en entrée et génère une seule donnée en sortie.
- Quelques points peuvent réduire les performances de MapReduce. Avec sa tolérance aux pannes et ses bonnes performances en passage à l'échelle, les opérations de MapReduce ne sont pas toujours optimisées pour les entrées/sorties. De plus, les méthodes map() et reduce() sont bloquantes. Cela signifie que pour passer à l'étape suivante, il faut attendre que toutes les tâches de l'étape courante soient terminées. MapReduce n'a pas de plan spécifique d'exécution et n'optimise pas le transfert de données entre ces nœuds.
Distribution et fiabilité
MapReduce tire sa fiabilité de la répartition, sur chaque nœud du réseau, des opérations à appliquer au jeu de données ; le développeur s'attend à ce que chaque nœud retourne périodiquement le travail accompli et les modifications de statut. Si un nœud ne retourne rien pendant cet intervalle, le nœud maître (appelé NameNode en Hadoop) (similaire au serveur maître du Google File System) considère le nœud comme mort, et envoie les données affectées à ce nœud à d'autres nœuds. Les opérations individuelles utilisent des opérations atomiques pour les nommages des fichiers de sortie comme une vérification double pour s'assurer qu'il n'y a aucun conflit parallèle avec un thread en cours ; quand les fichiers sont renommés, il est aussi possible de les copier sous un autre nom en plus du nom de la tâche (permis pour les effets de bords).
Les opérations de réduction fonctionnent sensiblement de la même manière, mais en raison de leurs propriétés inférieures concernant les opérations concurrentes, le nœud maître tente de programmer les opérations de réductions sur le même nœud, ou aussi proche possible du nœud détenant les données qui doivent être traitées. Cette propriété est préférée par Google car elle ne nécessite pas de bande passante supplémentaire. Ceci est un avantage car la bande passante est souvent limitée dans les réseaux internes aux entreprises.
Les facteurs de performance
D'après une étude[7] de 2010 de l'Université nationale de Singapour, il existe cinq facteurs qui influent sur les performances du MapReduce.
Le modèle de programmation MapReduce a été conçu pour qu'il soit indépendant du système de stockage des données. Il lit les paires <clé, valeur> à l'aide d'un lecteur. Le lecteur récupère chaque enregistrement contenu dans le système de stockage, puis il les place dans une paire <clé, valeur> afin de pouvoir les traiter lors de MapReduce. Bien que MapReduce ne dépende pas d'un système de stockage particulier, il éprouve des difficultés lorsque le système de stockage est une base de données. Les systèmes de bases de données parallèles commerciaux utilisent un moteur pour exécuter les requêtes et un moteur de stockage. Pour exécuter une requête, le moteur de requêtes lit directement les données depuis le moteur de stockage. MapReduce doit d'abord lire la valeur, puis la stocker dans une paire à l'aide du lecteur, ce qui explique pourquoi MapReduce est moins performant dans les bases de données. En comparant MapReduce et les systèmes de bases de données parallèles, trois facteurs, pouvant affecter les performances de MapReduce, ont été mis en évidence :
- mode d'entrée/sortie : la façon dont le lecteur récupère les informations ;
- l'analyse des données : la façon dont le lecteur analyse les données ;
- l'indexation.
MapReduce utilise un système de planification afin d'affecter les blocs de données aux nœuds disponibles dans le cluster. Ce système provoque des coûts d'exécution et peut ralentir l'exécution de MapReduce. Deux facteurs peuvent influencer les performances de MapReduce :
- la taille des blocs de données distribués ;
- l'algorithme de planification.
Mode entrée/sortie
Deux modes de lectures peuvent être utilisés par le lecteur afin de lire les données stockées dans un système de stockage.
- Le mode entrée/sortie direct avec lequel le lecteur lit directement les données stockées dans le disque local. Dans ce cas, les données sont transférées depuis la mémoire cache vers la mémoire du lecteur en utilisant l'accès direct à la mémoire.
- Le mode entrée/sortie streaming avec lequel le lecteur lit les données depuis un autre processus en cours d'exécution à l'aide de moyen de communication entre les processus comme TCP/IP ou JDBC.
D'après les tests réalisés dans cette étude[8], la différence de performance entre ces deux modes est faible (environ 10 %).
Le parsage des données
Quand le lecteur récupère les données depuis le système de stockage, il doit convertir les données en paire <clé, valeur> pour continuer l'exécution (ce processus s'appelle l'analyse de données). L'analyse consiste à décoder les données depuis leur format natif de stockage afin de les transformer vers un format qui pourra être utilisé par un langage de programmation. Il existe deux types de décodage, le décodage immuable et le décodage mutable. Le décodage immuable consiste à transformer des données en objets immuables. Les objets immuables en programmation orientée objet sont des objets dont l'état ne peut être modifié après leur création contrairement aux objets mutables.
Lorsque l'on utilise le décodage immuable, chaque donnée sera alors placée dans un objet immuable. Par conséquent, si l'on décode 4 millions de données, 4 millions d'objets immuables seront créés. Par défaut, le MapReduce de Google utilise des objets immuables[9].
Une autre méthode consiste à utiliser le décodage mutable. Avec ce décodage, un objet mutable est réutilisé pour décoder toutes les données. Ainsi, le nombre de données n'est plus important car seulement un objet sera créé.
D'après les études[10],[11],[12], les faibles performances du parsage sont dues au décodage immuable. Le décodage immuable est plus lent que le décodage mutable car il produit un grand nombre d'objets immuables durant le processus de décodage. La création de tous ces objets immuables augmente la charge de travail des processeurs.
L'indexation
Le MapReduce étant indépendant du système de stockage, il ne peut pas prendre en compte l'ensemble des données en entrée pour avoir un index disponible. MapReduce ne semble pas capable d'utiliser des index[10]. Cependant, trois méthodes pour utiliser les index ont été trouvées afin d'augmenter la vitesse du processus du traitement des données[13].
- MapReduce offre une interface aux utilisateurs pour spécifier un algorithme pour la distribution des nœuds. Par conséquent, il est possible d'implémenter un algorithme qui utilise l'index pour réduire les blocs de données.
- Si l'ensemble des données en entrée du MapReduce est un ensemble de fichiers indexés (avec des B-Arbres), on peut traiter ces données en implémentant un nouveau lecteur. Le lecteur va prendre certaines conditions de recherche et va l'appliquer à l'index afin de récupérer les données contenues dans chaque fichier.
- Si les données en entrée du MapReduce consistent en des tables indexées stockées dans n serveurs de bases de données, il est possible d'appliquer n tâches map pour traiter ces tables. Dans chaque tâche map, la fonction map() envoie une requête SQL vers un serveur de base de données pour récupérer les données. Ainsi, on utilise de façon transparente les index de la base de données.
Distribution des blocs/algorithme de planification
Pour réduire les temps de planification, il est possible de modifier la taille des blocs de données à distribuer aux nœuds du cluster. Si l'on augmente la taille des blocs de données, alors la planification sera plus rapide, car elle nécessitera moins de tâches map. Cependant, si l'on augmente trop la taille des blocs, alors le risque d'échec est plus important[14].
Utilisations
MapReduce peut être utilisé pour un grand nombre d'applications[15], dont grep distribué, tri distribué, inversion du graphe des liens web, vecteur de terme par hôte, statistiques d'accès au web, construction d'index inversé, classification automatique de documents, apprentissage automatique[16], traduction automatique statistique (distributed grep, distributed sort, web link-graph reversal, term-vector per host, web access log stats inverted index construction, document clustering, machine learning, statistical machine translation). De manière plus significative, quand MapReduce fut terminé, il a été utilisé pour régénérer entièrement les index Internet de Google, et a remplacé les vieux programmes ad hoc utilisés pour la mise à jour de ces index et pour les différentes analyses de ces index[17].
MapReduce génère un large nombre d'intermédiaires et de fichiers temporaires, qui sont généralement gérés et accédés via le Google File System pour de meilleures performances.
Hadoop
Présentation
Hadoop est une implémentation open source en Java du MapReduce distribué par la fondation Apache. Il a été mis en avant par des grands acteurs du web tels que Yahoo! et Facebook[18]. Les deux caractéristiques principales de Hadoop sont le framework MapReduce et le Hadoop Distributed File System (qui s’inspire du Google File System). Le HDFS permet de distribuer les données et de faire des traitements performants sur ces données grâce au MapReduce en distribuant une opération sur plusieurs nœuds afin de la paralléliser[19].
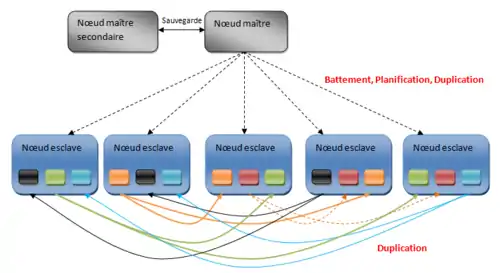
Dans Hadoop, le nœud maître est appelé le JobTracker et les nœuds esclaves sont appelés TaskTracker. Chaque nœud esclave va contenir les blocs de données en les répliquant. Le nœud maître connaît les emplacements des différentes répliques. Le nœud maître secondaire sert à effectuer des sauvegardes régulières du nœud maître afin de pouvoir le réutiliser en cas de problème[20].
Hadoop exécute une tâche de type MapReduce en commençant par diviser les données en entrée en bloc de données de même taille. Ensuite, chaque bloc est planifié pour être exécuté par un TaskTracker. Le processus d’assignement des tâches est implémenté comme un protocole de type « battement de cœur ». Cela signifie que le TaskTracker notifie le JobTracker que sa tâche est terminée afin que celui-ci lui assigne une nouvelle tâche à exécuter. Lorsque la fonction map est achevée, le système va regrouper toutes les paires intermédiaires et lancer une série de réductions pour produire le résultat final[21].
Performances
En milieu hétérogène
L'implémentation 2010 de Hadoop considère que le traitement se réalise sur un cluster de machines homogènes (c'est-à-dire qu'elles possèdent toutes les mêmes caractéristiques matérielles)[22]. Il ne tient pas compte non plus de la localité des données, il considère que toutes les données sont locales. Malheureusement, ces deux facteurs peuvent influencer les performances du MapReduce de manière conséquente[23].
En milieu homogène, tous les nœuds ont la même charge de travail, ce qui indique qu'aucune donnée ne devra être transférée d'un nœud vers un autre. En milieu hétérogène, un nœud ayant des performances élevées peut terminer son traitement local plus rapidement qu'un nœud ayant des performances plus faibles. Lorsque le nœud rapide a terminé son traitement, il devra récupérer les données non traitées d'un ou plusieurs autres nœuds plus lents. Le transfert d'une donnée d'un nœud lent vers un nœud rapide a un coût élevé[24].
Dans le Cloud
Présentation
Le MapReduce a émergé en 2004[25] comme un important modèle de programmation pour les applications utilisant d’énormes quantités de données grâce à sa répartition efficace du travail sur différents nœuds de calcul[26]. Il commence[27] notamment à être utilisé dans le Cloud Computing car son nombre de données stockées et manipulées ne cesse de croître. Il est donc nécessaire d'avoir un moyen d'améliorer le traitement des données au sein du Cloud.
En termes de ressources, le Cloud peut se caractériser en trois points : une capacité de stockage des données importante, de la puissance de calcul à la demande, utilise peu de bande passante[27]. La taille des données stockées dans le Cloud augmente sans cesse notamment les fichiers de type image, vidéo, audio ou les instruments scientifiques pour réaliser des simulations[28],[29]. Le traitement de ces données est devenu l'un des principaux défis du Cloud Computing[30].
Le Cloud utilise principalement des machines virtuelles(VM) pour exécuter les applications. Les VM permettent d’exploiter pleinement les ressources du système, d’améliorer la fiabilité du système en sauvegardant l'état du système à l'aide de fonctionnalité incluse dans les machines virtuelles et de réduire la consommation énergétique en réduisant le nombre de nœuds utilisés pour réaliser les tâches.
Combiner le Cloud Computing qui utilise des VM et le MapReduce peut s'avérer être intéressant. Principalement, parce que les technologies de virtualisation sont arrivées à maturité. Elles ont déjà été utilisées pour des grilles de calcul pour utiliser pleinement les ressources des nœuds de calcul, des applications HPC (High-Performance computing). De plus, d’un côté il y a la progression croissante de la popularité du Cloud (qui utilise des VM), de l’autre, le MapReduce commence à être largement utilisé grâce à ses nombreux points forts notamment pour sa scalabilité et sa tolérance aux fautes. C’est pourquoi, combiner ces deux technologies permettrait de créer un moyen efficace de traiter des données conséquentes sur le Cloud[31]. À cela s’ajoute le fait que le MapReduce utilise des tâches spéculatives. Ce sont des tâches qui peuvent être relancées sur un autre nœud si elles sont détectées comme étant trop lente. Le problème est que relancer une tâche peut faire diminuer les performances en augmentant le temps d'exécution étant donné que la tâche doit reprendre tout le traitement. Grâce aux nouvelles technologies des VM que sont la sauvegarde et la migration, les performances et la fiabilité du MapReduce sont améliorées[31]. La fonctionnalité de sauvegarde consiste à sauvegarder l’état du système, il peut ainsi retourner à cet état s'il rencontre une erreur grave qui empêche son bon fonctionnement[32]. La fonctionnalité de migration consiste à distribuer une VM ou une application sur plusieurs nœuds physiques sans stopper l’application.
Performance
Pour tester le MapReduce, les différentes mesures sont effectuées sur le framework Hadoop. Des tests de performance sont réalisés sur le HDFS car il joue un grand rôle dans l’exécution du MapReduce. En effet, c'est notamment le HDFS qui se charge de la répartition des tâches sur les différents nœuds, il décide aussi de la taille des données à traiter par nœud[22]. D’autres tests seront effectués sur la faisabilité d’utiliser des VM pour améliorer les performances du MapReduce en augmentant l’utilisation des ressources (en augmentant le nombre de VM par nœud). Les performances sont mesurées à l’aide de deux benchmark connus, le benchmark de tri et de comptage de mots.
- benchmark de tri
- ce benchmark utilise le map/reduce framework pour trier des données en entrée.
- Le benchmark « Comptage de mots »
- ce benchmark compte le nombre d’occurrences de chaque mot dans un fichier et écrit le résultat sur le disque local.
HDFS
L’évaluation des performances du HDFS se fait dans un cluster physique (PH-HDFS) et dans un cluster virtuel (VM-HDFS lors d’écriture et de lecture de données afin de montrer les différences de performances entre un cluster physique et un cluster virtuel.
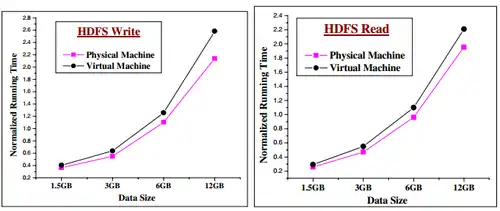
Dans cette évaluation, plusieurs transferts de données de différentes tailles sont effectués. Le PH-HDFS réalise des meilleurs temps, les écarts se creusent lorsque les données augmentent en taille.
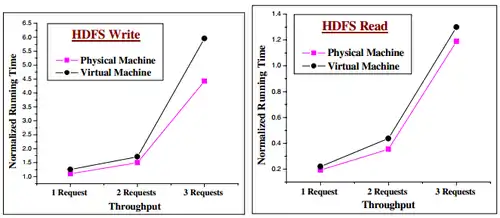
Dans cette évaluation, une ou plusieurs requêtes sont lancées simultanément et on mesure le temps nécessaire pour réaliser le transfert de données. Les performances du PH-HDFS sont meilleures que celles du VM-HDFS.
VMs feasiblity
Avec l’avènement des processeurs multi-cœurs, il est pertinent d’utiliser des processeurs multi-cœurs du cluster pour installer plusieurs VM par processeur afin d'utiliser pleinement les capacités du nœud. Pour les tests, plusieurs clusters ont été mis en place afin d'évaluer l'impact de l'augmentation du nombre de VM par nœud :
- Ph-Cluster : 7 nœuds physiques
- V-Cluster : 1 VM par nœud – 7 nœuds VM dans le cluster
- V2-Cluster : 2 VM par nœud – 13 nœuds VM dans le cluster
- V4-Cluster : 4 VM par nœud – 25 nœuds VM dans le cluster
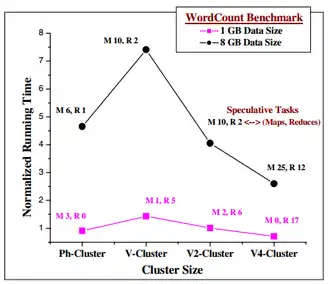
Comme le montre cette figure, le benchmark « comptage de mots » avec le Ph-Cluster est plus rapide que le V-Cluster. Lorsque les données font 1 Gb, la différence est faible. Mais lorsque les données sont beaucoup plus importantes (ici 8 Gb), on observe un écart important. Cela est causé par l’augmentation des tâches spéculatives ce qui cause une utilisation inefficace des ressources. En revanche, les clusters V2 et V4 sont beaucoup plus performants que le Ph-Cluster car il y a beaucoup plus de calculs par cycle.
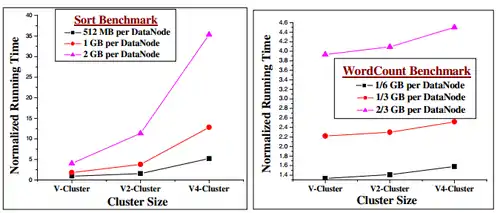
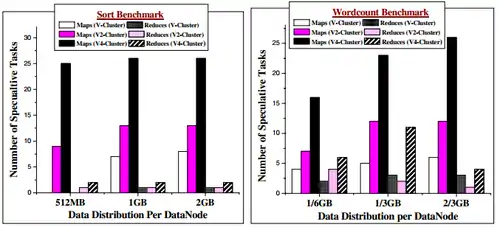
Lorsque le benchmark de tri est lancé, le temps d’exécution, pour la même distribution des données, augmente avec l’augmentation du nombre de VM déployées sur un nœud physique. De plus, les écarts se creusent lorsque la taille des données distribuées augmente. Cela est provoqué pour 3 raisons : les mauvaises performances du HDFS dans les VM lors des opérations de lecture/écriture (comme vu précédemment), l’augmentation du nombre de tâche spéculative (Figure 6) et l’importante quantité de données transférées pendant les étapes intermédiaires[33].
Extensions de Hadoop
Rappelons que Hadoop est un framework basé sur le modèle de programmation MapReduce. Étant très utilisé dans les calculs de très grandes masses de données, plusieurs améliorations de ce framework sont apparues. Ces extensions sont des frameworks : "BlobSeer" modifie le système de fichiers pour améliorer l’accès aux données, "Phoenix" répartit les tâches sur les processeurs en utilisant le MapReduce, et "Mars" améliore le calcul de données sur des processeurs graphiques.
Amélioration de Hadoop en milieu hétérogène
Présentation
Comme dit précédemment, le problème de performance de Hadoop en milieu hétérogène est dû au transfert des données entre les nœuds rapides et les nœuds lents. Lorsqu'une large quantité de données est transférée, cela affecte de manière significative.
Afin d'améliorer les performances de Hadoop, il faut minimiser le transfert des données entre les nœuds rapides et lents[4]. Pour cela, un mécanisme de placement de données a été implémenté; il distribue et stocke les données à travers de nombreux nœuds hétérogènes en fonction de leurs capacités. Avec cela, le transfert des données peut être réduit si le nombre de données placées dans le disque de chaque nœud est proportionnel à la vitesse de traitement des nœuds.
La réplication des données présente de nombreuses limitations. Premièrement, cela représente un coût important pour créer chaque réplique des données à l'intérieur d'un cluster ayant un nombre important de nœuds. Deuxièmement, distribuer un nombre important de répliques peut provoquer une surcharge de la bande passante du cluster. Troisièmement, stocker les répliques requiert des disques ayant une énorme quantité de stockage.
Amélioration
Des chercheurs se sont focalisés sur ce problème afin de produire un mécanisme de placement des données[34]. Pour corriger le problème, ils se sont penchés sur le meilleur moyen de placer les données où les fichiers ne seront découpés et distribués sur plusieurs nœuds sans les dupliquer.
Ce mécanisme est basé sur 2 algorithmes[24] qui sont incorporés dans le HDFS de Hadoop :
- Le premier algorithme consiste à distribuer des fragments du fichier en entrée.
- Le deuxième algorithme consiste à réorganiser les fragments du fichier et à corriger les erreurs qui peuvent arriver après l'exécution du premier algorithme.
Le premier algorithme fonctionne comme ceci[24]:
- il commence par diviser le fichier d'entrée en un nombre de fragments de même taille.
- Puis il assigne les fragments aux nœuds du cluster en fonction de la vitesse de traitement des nœuds. (Cela aura pour conséquence qu'un nœud avec des faibles performances aura moins de fragments à traiter qu'un nœud avec des meilleures performances).
Si l'on considère une application, utilisant le MapReduce, et un fichier d'entrée dans un cluster hétérogène de Hadoop. Le placement initial des données ne tient pas compte des performances des nœuds car Hadoop estime que tous les nœuds vont exécuter et terminer leur tâche avec, environ, le même temps. Des expérimentations[35], ont montré qu'en règle générale, le temps de traitement de chaque nœud était stable car le temps de réponse de chaque nœud est linéairement proportionnel à la taille des données. Avec ceci, on peut quantifier la vitesse de traitement de chaque nœud dans un environnement hétérogène. Le terme pour définir la performance de chaque nœud est "Ratio Performance"[34].
Le Ratio Performance de chaque nœud est déterminé à l'aide de cette procédure :
- Les opérations d'une application utilisant le MapReduce sont réalisées séparément sur chaque nœud
- On récupère ensuite les temps de réponse de chaque nœud
- Le temps de réponse le plus court est utilisé comme temps pour normaliser les mesures du temps de réponse
- Les valeurs normalisées, appelées Ratio Performance, sont utilisées par l'algorithme de placement pour distribuer les fragments de fichier aux nœuds.
Prenons un exemple afin de montrer comment les Ratio Performance sont calculées. Prenons 3 nœuds hétérogènes A, B et C dans un cluster Hadoop. Après avoir exécuté l'application séparément sur chaque nœud, on récupère le temps de réponse de chaque nœud A, B et C (10 s, 20 s et 30 s respectivement). Le temps de réponse du nœud A est le plus court, par conséquent, le Ratio Performance de A vaut 1. Les Ratio Performance de B et C valent 2 et 3 respectivement. Cela signifie que le nœud A pourra gérer 30 fragments du fichier d'entrée tandis que le nœud C en gérera seulement 10.
Après l'exécution de l'algorithme de distribution des fragments pour réaliser le placement initial, les fragments peuvent être corrompus pour plusieurs raisons:
- de nouvelles données ont été ajoutées au fichier de départ,
- des blocs de données ont été supprimés du fichier,
- de nouveaux nœuds ont été ajoutés au cluster.
Pour éviter ces problèmes, un deuxième algorithme[34] a été implémenté pour réorganiser les fragments du fichier en le basant sur le Ratio Performance des nœuds.
Cet algorithme fonctionne comme ceci :
- Les informations concernant la topologie du réseau et l'espace disque du cluster sont collectées par le serveur de distribution des données.
- Le serveur crée deux listes de nœuds (s'agit-il vraiment de listes de nœuds ? la description donne plutôt l'impression de deux vecteurs d'information sur les nœuds) : une liste de nœuds qui contient le nombre de fragments dans chaque nœud qui peuvent être ajoutés, une liste de nœuds qui contient le nombre de fragments locaux dans chaque nœud qui excédent la capacité de celui-ci.
- Le serveur de distribution des données transfère les fragments d'un nœud, dont la capacité du disque a été dépassé, vers un nœud qui possède encore de l'espace disque.
Dans le processus de migration des données entre 2 nœuds[34] (un surchargé et un ayant de l'espace disque), le serveur transfère les fragments du fichier depuis le nœud source de la liste des nœuds en surcharge vers un nœud ayant encore de l'espace de la liste des nœuds sous-utilisés. Ce processus est répété jusqu'à ce que le nombre de fragments dans chaque nœud soit en accord avec son Ratio Performance.
Performances
Afin de montrer les résultats de ces algorithmes de cette étude[36], deux tests ont été effectués, le Grep et le WordCount. Ces 2 applications tournent sur des clusters Hadoop. Grep est un outil de recherche pour une expression régulière dans un texte. WordCount est un programme utilisé pour compter les mots dans un texte.
Les résultats ont montré que ces algorithmes ont amélioré les performances du Grep de 17 % en moyenne et le WordCount de 7 % en moyenne.
BlobSeer
Présentation
Hadoop est un framework basé sur le modèle de programmation Map/Reduce. Et pour cela Hadoop doit s'appuyer sur un "puissant outil" : son système de fichier HDFS[37]. Le système de fichier HDFS (appelé Hadoop Distributed File System) est un paramètre important de la performance de calcul de Hadoop car il lui est spécifique. C'est-à-dire qu'il a été conçu de façon à maximiser les accès aux données.
Seulement des erreurs subsistent lorsque plusieurs processus accèdent à un même fichier. C'est le framework Blobseer qui propose une solution[37] à ce problème. En effet, ce framework propose de modifier le HDFS pour le remplacer par son propre système de fichier le BSFS (Blobseer File System).
Un nouveau système de fichier
Les raisons du changement de ce système de fichier sont liées aux problèmes d’accès concurrent sur un même fichier. Le système HDFS a été conçu de manière à permettre les meilleures performances de calcul de Hadoop, cependant cette implémentation ne suffit pas. Le système de fichier HDFS ne permet pas de maintenir[37] un haut débit sur les accès concurrents à un même fichier, de plus le système de fichier actuel ne permet pas certaines fonctionnalités telles que la gestion de versions ou encore différents update simultanés sur un même fichier.
L'un des points forts de Hadoop est de parcourir des pétaoctets en quelques heures seulement, cela est dû au fait que les fichiers ont une taille de plusieurs centaines de gigaoctets. De ce fait, il devient possible d'accéder à de petites parties d'un même fichier de façon concurrente. Il ne faut pas oublier qu'il serait impossible de travailler avec des millions de petits fichiers au lieu d'un seul, et même si le système de fichier le permet, maintenir un très haut débit n'est pas faisable.
Blobseer propose[37] donc un système de fichier qui permet d'accéder à des petites parties d'un grand fichier, permettant ainsi à des milliers de "clients" de modifier le même fichier sans problème de conflit. BSFS permet donc aussi la gestion de versions ce qui permet de supprimer les changements indésirables et la création de branches indépendantes ce qui ne devrait pas diminuer les performances de calcul ni la surcharge de l'espace de stockage qui serait dû à des milliers de petits fichiers.
Performances
Les performances du framework ont été testées sur grid5000[38]. Blobseer a été comparé avec Hadoop. Pour cela, les frameworks ont été utilisés sur des micro-tâches :
- Un seul processus qui écrit sur un fichier volumineux ( > 20 GB)[38],
- Des processus qui lisent les mêmes parties d'un seul fichier en même temps,
- Des processus qui écrivent dans un même fichier volumineux.
Les relevés de performances ont montré que le débit (l’accès au données) était jusqu'à deux fois supérieur à celui de Hadoop[38]. Ces résultats ont aussi révélé que le framework BlobSeer peut supporter jusqu’à deux fois plus de clients (c'est-à-dire le nombre d’accès sur un seul fichier). Le ratio des performances entre BlobSeer et Hadoop n'est pas supérieur à deux[38]. En effet, BlobSeer utilise les mêmes capacités de calcul que Hadoop, à la différence que le système de fichiers a été modifié.
Phoenix[39]
Présentation
Phoenix est une API basée sur le modèle MapReduce, proposé par google. La différence est que Phoenix est utilisé sur les ordinateurs multi-cœurs et donc, il n'utilise pas des serveurs mais des threads pour pouvoir utiliser le MapReduce. Phoenix est basé sur un langage fonctionnel, de façon à rendre la parallélisation totalement transparente à l'utilisateur. Phoenix est utilisé en C et C++.
La structure
C'est une API développée pour être utilisée avec du code C/C++ mais elle peut être facilement exportable en java/C#[40]. Pointeurs, Buffer, P-Threads sont utilisés pour augmenter la performance de l'API. Les Buffers permettent d'accéder aux données dans une mémoire partagée. Il y a deux types de buffers : les input/output sont les buffers contenant les données en entrée ainsi que celles en sortie, c'est-à-dire les données dont l'utilisateur a besoin, et les autres buffers. Ces derniers sont ceux utilisés pour réaliser le MapReduce, ce sont donc des buffers "invisibles" aux yeux de l'utilisateur. Les pointeurs sont utilisés évitant au maximum la non duplication des données améliorant ainsi significativement la vitesse de calcul des données. L'utilisation de P-Threads permet à l'API de répartir son travail sur plusieurs processeurs en suivant le modèle de programmation MapReduce.
Performances[41]
Les performances ont été calculées sur des tâches basiques telles que :
- Calculer la fréquence d'apparition d'un mot dans un texte,
- Trouver les dépendances entre les liens de toutes les pages d'un site web (quel lien relie telle page),
- Multiplication d'une matrice,
- Coder un texte avec une clé correspondant à un autre texte (String match),
- KMeans (classification des points en 3D dans des groupes),
- Calculer la fréquence des couleurs RGB dans un tableau d'images,
- Calculer la ligne qui correspond à un nuage de points sur un graphique,
avec comme valeur étalon, les performances des p-threads sans le modèle de MapReduce.
Les résultats de Phoenix[42] montrent qu'avec un processeur 4 cœurs, on peut accélérer les calculs de 40 % et avec 8 cœurs, on peut aller jusqu'à 50 %. Cependant, bien que la vitesse de calcul soit augmentée, sur de simples machines elle reste néanmoins équivalente à celle des p-threads. En effet, bien que le modèle de MapReduce soit très efficace sur des clusters a l'échelle de millions de données, l'implémentation du modèle n'est pas assez générale[43] pour couvrir la totalité des programmes.
Mars[44]
Présentation
Encouragé par le succès du modèle programmation MapReduce, le framework Mars[45] a vu le jour, permettant d'implémenter le modèle MapReduce sur des processeurs graphiques. Les processeurs graphiques (GPU) ont dix fois plus de bande passante mémoire que les CPU, et sont aussi jusqu'à dix fois plus rapides[46].
Performances
Pour évaluer ces performances, Mars a été comparé avec Phoenix[39], sur les mêmes tâches. Il en est ressorti que les performances de Mars sont 1,5 fois plus élevées que celles de Phoenix[47].
Optimisation
Mars est encore en cours d'étude, cependant trois points essentiels sont relevés pour une future évolution[47] :
- Mars ne peut pas s'occuper de trop grandes données, il est bloqué à la taille de la mémoire du GPU,
- Mars est implémenté sur des GPU NVIDIA, il serait intéressant de le développer sur les GPU AMD,
- Phoenix est implémenté sur des CPU et Mars sur des GPU. Un framework combinant les deux API pourrait voir le jour, dans le but d'intégrer les avantages des deux types de processeurs.
Alternatives à Hadoop
PQL
Présentation
PQL est un langage implémenté comme une extension de java[48]. Il a été conçu de façon à augmenter son expressivité et sa modularité, une comparaison entre son implémentation et celle de java sur des tâches parallèles similaires a été effectuée[48]. La parallélisation est un problème d’actualité dans l’informatique, c’est pourquoi il est important de créer des langages ou des librairies permettant de faciliter la parallélisation. Cependant il ne faut pas oublier la programmation séquentielle, c’est pourquoi l’implémentation d'un langage adapté à la programmation parallèle et séquentielle est essentiel. Tous les programmes implémentés avec PQL sont parallélisés grâce à la programmation déclarative.
Programmation Déclarative
PQL est un langage basé sur la programmation déclarative, ce qui veut dire que le programmeur peut spécifier ce qu'il veut faire sans pour autant préciser “comment” le faire. PQL a été implémenté pour trouver la méthode la plus rapide à exécuter. En effet, il va savoir quel bout de code devra être parallélisé ou non. Ce n’est pas au développeur de chercher la façon d’optimiser son code. PQL répartit la charge de travail sur les processeurs disponibles en utilisant le MapReduce. PQL a été optimisé pour les tâches parallèles de façon que l'utilisateur ait le moins de manipulations à faire comparé à un code parallèle écrit par l'utilisateur.
Language illustration
PQL utilise les booléens &&, ||, XAND, XOR ainsi que des mots-clés tels que reduce, forall, query, exists[49]. Le nombre de mots clés de PQL est explicitement réduit pour améliorer un maximum la parallélisation.
Une requête peut s’implémenter avec[49]: une Quantifier Expression (renvoie une quantité, utilise les forall, exists…), une Java Expression (du code Java), un id (variable, avec ou sans type), une QExpr (combine les cas précédents).
Exemple :
int[] array = query(Array[x]==y):range(1,1000).contains(x) && y=x*x;La requête va retourner un tableau d'entiers contenant les carrés de x entre 1 et 1000.
Une quantifier expression peut s’écrire sous la forme[49]: QUANT-EXPR::=<QUANT> <ID> ‘:’ <QUERY> query‘(’ <MATCH> ‘)’ ‘:’ <QUERY> (Container queries) reduce‘(’ id ‘)’ <ID>[over<ID-SEQ>]:<QUERY> (Reductions)
Exemple : forall int x : x == x toujours vrai (Quantifier) (ID) (x==x query)
Container queries : query (Map.get(x) == y): range(1, 10).contains(x) && y == x*x query‘(’ <MATCH> ‘)’ ‘:’ <QUERY> Va construire une map contenant les carrés de 1 à 10 (on peut accéder à l’élément 0 mais ça retournera un null)
Opération de réduction :
reduce (sumInt) x : myset.contains(x)
cette expression va additionner tous les x contenus dans myset
reduce (sumDouble) x over y : set.contains(y) && x == 1.0 / y
Additionne les inverses des éléments contenus dans la mapLes types peuvent être déclarés implicitement (l'utilisateur n'a pas besoin de déclarer le type) ou explicitement (l'utilisateur doit déclarer le type de la variable)[50]. PQL lève les exceptions mais on n’a pas de garantie de l’ordre[51]. PQL utilise == ou = pour les égalités (sauf pour les string et les objets .equals())[51].
L’utilisateur peut créer ses propres réductions. Elle doivent respecter plusieurs propriétés (méthode statique, associative, commutative…). Si ces propriétés n'étaient pas respectées, cela entraînerait des erreurs[52].
Performances
Pour évaluer PQL, différentes tâches ont été implémentées[53](calcul des primes d’un grand nombre d’employés, trouver une sous-chaîne dans une chaîne de chaînes de caractères, une liste de documents qui peuvent être reliés entre eux, le but étant de trouver les cycles, calculer le nombre d’occurrences de tous les mots dans plusieurs textes).
L'implémentation des solutions suivant les différentes façons[53] :
- Le PQL
- Une méthode Java mono thread
- Multi thread Java
- SQL
- Framework Hadoop
Lors de l’implémentation avec le mono-thread et PQL, des variables d’entrée sont utilisées mais sans aucune variable temporaire[54], tandis que pour les autres implémentations l'utilisation de variables et des tableaux intermédiaires était nécessaire que ce soit pour la communication ou l’optimisation. L’implémentation SQL est simple mais devient très vite compliquée si on la mélange avec du java.
L'implémentation PQL est simple à écrire car elle contient peu de lignes[55]. En effet, la solution qui contient le nombre de lignes minimum est toujours celle avec PQL. La deuxième étant la mono thread (mais non optimisée). Les autres méthodes contiennent 5 à 20 fois plus de lignes.
Dans les 4 tâches, seule la première ne fait pas de bonnes performances car le temps pour faire les opérations de merge des résultats est très élevé. Pour les autres tâches, PQL peut aller entre 2 et 6 fois plus vite que les autres implémentations[56]. Tous ces tests montrent que PQL est bien plus performant et utilise moins de lignes de code. Cependant, il est nécessaire de rappeler que SQL et Hadoop utilisent une table de données et donc que leur temps d’exécution est ralenti par l'accès à cette base. De plus, le framework Hadoop est optimisé pour des calculs sur des clusters et non pas sur une seule machine.
Framework "Écologique"
Présentation
Le MapReduce a surtout été récompensé pour sa flexibilité et son efficacité. Pourtant, à l’heure où l’écologie prend une place plus importante dans les nouvelles technologies, il est pertinent d’étudier la consommation énergétique du MapReduce et savoir comment la diminuer.
La plupart des frameworks implémentant le MapReduce, comme Hadoop, considèrent que le traitement se fait dans un milieu homogène. En réalité, il est très rare qu’un cluster contienne les mêmes machines. Les machines varient selon différents critères basés sur la consommation énergétique : quantité de pâte thermique, vitesse du ventilateur, taille du ventilateur, localisé plus ou moins proche d’une unité de refroidissement, quantité de poussière. Cela implique que des machines vont consommer plus d’énergie que d’autres pour réaliser le même traitement.
Un framework a donc été conçu[57] pour pouvoir planifier de façon dynamique les tâches en fonction de la consommation individuelle de chaque nœud du cluster.
Implémentation
Pour pouvoir planifier dynamiquement, il a d’abord fallu élaborer un moyen de connaître la consommation de chaque nœud. Dans cet article[57], une corrélation a été établie entre la température du CPU et la consommation d’énergie, cette relation présente cependant des imprécisions. En effet, une machine peut consommer une grande quantité d’énergie tout en ayant une température basse si elle se trouve à proximité d’une unité de refroidissement. En général cette corrélation reste correcte.
Lorsque le Nœud Maître du HDFS a distribué les données, il démarre un thread qui va mesurer la température de chaque nœud. Lorsqu’un nœud a fini son traitement, si sa température est inférieure à la température maximale définie par l’utilisateur, alors une nouvelle tâche est affectée au nœud, sinon le nœud sera mis en attente jusqu’à ce que sa température baisse ou que le traitement soit terminé. Toutefois, lorsque toutes les tâches ont été distribuées, le module de tolérance aux pannes va commencer son travail sans prendre en compte la température. En effet, si tous les nœuds sont en refroidissement, la tâche sera alors bloquée.
Pour réduire la consommation, deux paramètres vont être mis en place : température maximale d’un nœud et nombre de tâches pour réaliser un traitement. Dans les prochaines évolutions de ce framework, chaque nœud aura sa propre température définie car certains processeurs ont une température plus élevée lors de leur fonctionnement.
Performances
Les mesures ont été réalisées sur l’algorithme WordCount (calcule toutes les itérations de tous les mots d’un document) dans un milieu hétérogène.
Nous allons étudier les variations des performances en fonction des deux paramètres cités dans le chapitre précédent.
Température maximale
La limite de température, pour décider si un nœud est capable ou non d’exécuter un traitement, peut limiter les performances. Les tests ont été effectués avec trois températures différentes (80°, 110°, 120°).
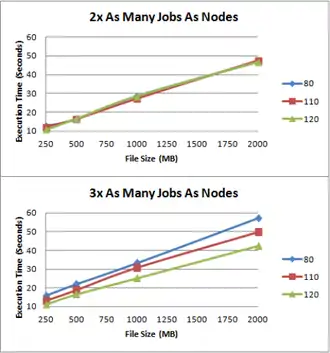
D’après la figure, nous constatons que plus la température maximale est faible, plus le temps d’exécution est important. Si la température maximale est trop proche de la température des CPU au repos, alors très peu de nœuds obtiendront une nouvelle tâche après avoir complété la première. Le problème est que cela pourrait entraîner un blocage de la tâche en cours jusqu’à ce qu’un nœud ait une température inférieure à la limite. En récupérant les informations du cluster dans lequel le framework est déployé, on pourrait éviter un tel risque. L’une des informations les plus importantes serait la température de chaque CPU au repos.
De plus, on remarque que plus le nombre de tâches par nœud est important et la température maximale est faible, plus le temps d’exécution augmente. Cela est dû au temps de refroidissement des nœuds pour repasser sous la limite.
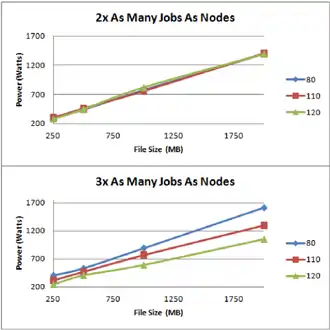
Nous constatons la même tendance pour la consommation électrique de chaque nœud. Avec ce framework, si nous choisissons correctement la température maximale, il est possible de faire des économies significatives sur la consommation électrique tout en limitant la baisse de performance.
Distribution des données
La distribution des données dans chaque nœud peut aussi influencer les performances et la consommation du MapReduce. Pour les mesures, nous avons un exemple avec un fichier de 500 MB et un de 1 GB.
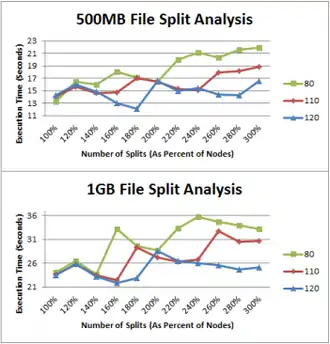
Dans les 2 graphes, nous constatons 2 points d’intersections, le premier arrive lorsque le ratio tâche/nœud est de 1 (cela signifie qu’il y a autant de tâches que de nœuds). Le deuxième arrive lorsque le ratio est de 2. Cela peut s’expliquer par le fait que le temps d’exécution entre le nœud le plus rapide et le nœud le plus lent est inférieur au temps d’exécution de la tâche. Ce qui implique que chaque nœud a reçu deux tâches. Toutefois, lorsque le ratio est de 3, les tâches sont beaucoup plus courtes, ce qui implique que le temps d’exécution entre le nœud le plus rapide et le nœud le plus lent est supérieur au temps d’exécution de la tâche. Dans la suite des travaux sur ce framework, une méthode sera mise en place pour savoir comment répartir les tâches de façon efficace. Nous pouvons remarquer que la température maximale joue encore un rôle très important dans la vitesse d’exécution.
Pour prouver que la température maximale et la distribution des données influe sur la consommation d’énergie. Des mesures ont été effectuées sur la consommation électrique d’un nœud dans un cluster.
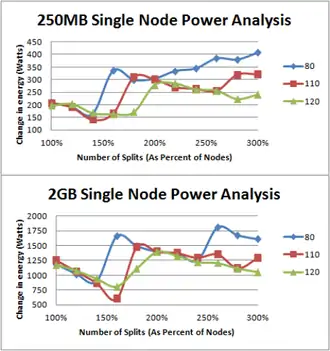
Nous pouvons voir qu’il y a deux pics de consommation pour le fichier de 2 GB lorsque la température maximale est de 80 °C. Cela arrive lorsque le nœud est replanifié. Quand le nœud n’est pas replanifié et que les tâches deviennent plus courtes, la division des tâches augmente et la consommation électrique diminue.
Grâce à ce framework, la consommation électrique d’un nœud a diminué de 36 %. Ce framework est encore en cours de développement mais il présente déjà des résultats très intéressants.
Brevet
Google a obtenu un brevet sur la fonction MapReduce, mais la validité de ce brevet est contestée[58],[59].
Comparaison
| Langage | ratio vitesse clusters | ratio de vitesse processeurs | Économie d'énergie | Environnement | |
|---|---|---|---|---|---|
| Hadoop | Java | 1 | NC | NC | Cluster |
| BlobSeer | Java | 1.35[60] | NC | NC | Cluster |
| Mars | Programming GPU | NC | 1.1 ~ 4[61] | NC | Processeur graphique |
| Phoenix | C/C++ | NC | 1 | NC | Processeur multi-cœurs |
| Framework Ecologique | Java | NC | NC | 36 % | Cluster |
Articles
- (en) « Evaluating MapReduce on Virtual Machines : The Hadoop Case », Cloud Computing 2009, Shadi Ibrahim, Hai Jin, Lu Lu, Li Qi, Song Wu, Xuanhua Shi,
- (en) « The performance of MapReduce : An In-Depth Study », Proceedings of the VLDB Endowment, Jiang Dawei, , p. 472-483
- (en) « Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters », 24th IEEE International Symposium on Parallel and distributed, Jiong Xie, Shu Yin, Xiaojun Ruan, Zhiyang Ding, Yun Tian, James Majors, Adam Manzanares, Xiao Qin,
- (en) « Configuring a MapReduce Framework for Dynamic and Efficient Energy Adaptation », 5th IEEE International Conference on Cloud Computing, Jessica Hartog, Zacharia Fadika, Elif Dede, Madhusudhan Govindaraju,
- (en) « Parallel Data Processing with MapReduce : A Survey », ACM, Kyong-Ha Lee, Yoon-Joon Lee, Hyunsik Choi, Yon Dohn Chung, Bongki Moon,
- (en) « BlobSeer: Bringing high throughput under heavy concurrency to Hadoop Map-Reduce applications », 24th IEEE International Symposium on Parallel and distributed, Bogdan Nicolae, Diana Moise,Gabriel Antoniu, Luc Bougé, Mathieu Dorier,
- (en) « MapReduce: Simplified Data processing on Large Cluster », ACM, Jeffrey Dean, Sanjay Ghemawat,
- (en) « Evaluating MapReduce for Multi-core and Multiprocesseur Systems », IEEE 13th International Symposium on High Performance Computer Architecture, 2007. HPCA 2007., Colby Ranger, Ramanan raghuraman,Arun Penmetsa,Gary Bradski, Christos Kozyrakis,
- (en) « Improving MapReduce Performance in Heterogeneous Environments », 8th USENIX Symposium on Operating Systems Design and Implementation, Matei Zaharia, Andy Konwinski, Anthony D. Joseph, Randy Katz, Ion Stoica,
- (en) « A Library to Run Evolutionary Algorithms in the Cloud using MapReduce », EvoApplication, Pedro Eazenda, James McDermott, Una-may O’Reilly,
- (en) « Mars : A MapReduce Framework on Graphics Processors », ECOOP 2012 - Object-Oriented Programming - 26th European Conference, Beijing, China, June 11-16, 2012., Bingsheng He, Wenbin Fang, Qiong Luo, Naga K. Govindaraju, Tuyong Wang,
- (en) « PQL: A Purely-Declarative Java Extension for Parallel Programming », 17th International Conference on Parallel Architecture and Compilation Techniques (PACT 2008), Toronto, Ontario, Canada, October 25-29, 2008, Christoph Reichenbach, Yannis Smaragdakis and Neil Immerman,
- (en) « An analysis of traces from a production MapReduce cluster », CMU-PDL-09-107, Soila Kavulya, Jiaqi Tan, Rajeev Gandhi and Priya Narasimhan,
- (en) « A comparison of approaches to large-scale data analysis », Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, A. Pavlo, E. Paulson, A. Rasin, D. J. Abadi, D. J. DeWitt, S. Madden, M. Stonebraker,
- (en) « Mapreduce and parallel dbmss : friends or foss? », Communications of the ACM, M. Stonebraker, D. Abadi, D. J. DeWitt, S. Madden, E.Paulson, A. Pavlo, A. Rasin,
- (en) « Hive - a warehousing solution over a map-reduce framework », Proceedings of the VLDB Endowment VLDB Endowment Homepage archive - August 2009, A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, S. Anthony, H. Liu, P. Wychoff, R. Murthy,
Articles connexes
Références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « MapReduce » (voir la liste des auteurs).
- ↑ http://www.google.com/patents/US7650331 Brevet octroyé
- ↑ The Hadoop Case 2009, p. 521
- ↑ The Performance of MapReduce : An In-depth Study 2010, p. 472
- 1 2 3 Parallel Data Processing with MapReduce A survey décembre 2011, p. 11-20
- ↑ An analysis of traces from a production MapReduce cluster 2009, p. 94-103
- ↑ Parallel Data Processing with MapReduce: A survey décembre 2011, p. 13
- ↑ The Performance of MapReduce : An In-depth Study 2010, p. 474
- ↑ The Performance of MapReduce : An In-depth Study 2010, p. 479
- ↑ « Protocolbuffers/protobuf », sur GitHub (consulté le ).
- 1 2 A comparison of approaches to large-scale data analysis 2009, p. 165-178
- ↑ Mapreduce and parallel dbmss : friends or foss? 2010, p. 64-71
- ↑ Hive - a warehousing solution over a map-reduce framework 2009, p. 1626-1629
- ↑ The Performance of MapReduce : An In-depth Study 2010, p. 475
- ↑ The Performance of MapReduce : An In-depth Study 2010, p. 478
- ↑ (en) Colby Ranger, Ramanan Raghuraman, Arun Penmetsa, Gary Bradski et Christos Kozyrakis, « Evaluating MapReduce for Multi-core and Multiprocessor Systems », HPCA 2007, Best Paper
- ↑ (en) Cheng-Tao Chu, Sang Kyun Kim, Yi-An Lin, YuanYuan Yu, Gary Bradski, Andrew Ng et Kunle Olukotun, « Map-Reduce for Machine Learning on Multicore », NIPS 2006
- ↑ (en) « How Google Works », baselinemag.com : « As of October, Google was running about 3,000 computing jobs per day through MapReduce, representing thousands of machine-days, according to a presentation by Dean. Among other things, these batch routines analyze the latest Web pages and update Google's indexes. »
- ↑ Liste d'entreprises déclarant utiliser Hadoop
- ↑ Hadoop en moins de 5 minutes
- ↑
- ↑ The Performance of MapReduce : An In-depth Study 2010, p. 473
- 1 2 Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters 2010, p. 1
- ↑ Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters 2010, p. 2
- 1 2 3 Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters 2010, p. 3
- ↑ Parallel Data Processing with MapReduce A survey décembre 2011, p. 14
- ↑ Jiang 2010, p. 472
- 1 2 The Hadoop Case 2009, p. 519
- ↑ « Actualités et évènements », sur inria.fr (consulté le ).
- ↑ « MapReduce for scientific simulation analysis », sur slideshare.net (consulté le ).
- ↑ The Hadoop Case 2009, p. 520
- 1 2 The Hadoop Case 2009, p. 522
- ↑ https://technet.microsoft.com/en-us/library/bb740891.aspx
- ↑ The Hadoop Case 2009, p. 525
- 1 2 3 4 Jiong Xie, Shu Yun, Xiaojun Ruan, Zhiyang Ding, Yun Tian, James Majors, Adam Manzanares, Xiao Qin, « Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters », ACM, , p. 3 (lire en ligne)
- ↑ Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters 2010, p. 4
- ↑ Improving MapReduce Performance through Data Placement in Heterogeneous Hadoop Clusters 2010, p. 7
- 1 2 3 4 BlobSeer Framework 2010
- 1 2 3 4 BlobSeer Framework 2010, p. 5
- 1 2 Phoenix 2007
- ↑ Phoenix 2007, ch. 3, p. 3
- ↑ Phoenix 2007, ch. 5, p. 8
- ↑ Phoenix 2007, ch. 5, p. 7
- ↑ Phoenix 2007, ch. 5.4, p. 9
- ↑ Mars 2012
- ↑ Mars 2012, ch. 1, p. 260
- ↑ (en) Query co-processing on commodity processors, (lire en ligne), p. 1267
- 1 2 Mars 2008, ch. 5, p. 267
- 1 2 PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 1
- 1 2 3 PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 4
- ↑ PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 9
- 1 2 PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 10
- ↑ PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 11
- 1 2 PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 15
- ↑ PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 16
- ↑ PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 17
- ↑ PQL: A Purely-Declarative Java Extension for Parallel Programming 2008, p. 22
- 1 2 Configuring a MapReduce Framework for Dynamic and Efficient Energy Adaptation 2012, p. 914-920
- ↑ « Why Hadoop Users Shouldn't Fear Google's New MapReduce Patent », sur gigaom.com, (consulté le ).
- ↑ « Google's MapReduce patent : what does it mean for Hadoop? », sur Ars Technica (consulté le ).
- ↑ BlobSeer 2010, p. 10
- ↑ Mars 2012, p. 266