Le partitionnement de données (ou data clustering en anglais) est une méthode en analyse des données. Elle vise à diviser un ensemble de données en différents « paquets » homogènes, en ce sens que les données de chaque sous-ensemble partagent des caractéristiques communes, qui correspondent le plus souvent à des critères de proximité (similarité informatique) que l'on définit en introduisant des mesures et classes de distance entre objets.
Pour obtenir un bon partitionnement, il convient d'à la fois :
- minimiser l'inertie intra-classe pour obtenir des grappes (cluster en anglais) les plus homogènes possibles ;
- maximiser l'inertie inter-classe afin d'obtenir des sous-ensembles bien différenciés.
Vocabulaire
La communauté scientifique francophone utilise différents termes pour désigner cette technique.
Le mot anglais clustering est communément employé. On parle également souvent de méthodes de regroupement. On distingue souvent les méthodes « hiérarchiques » et « de partition »
Clustering non supervisé
Le « clustering non supervisé » aussi appelé classification non supervisée, est un processus qui permet de rassembler des données similaires. Le fait qu’il ne soit pas supervisé signifie que des techniques d'apprentissage machine vont permettre de trouver certaines similarités pour pouvoir classer les données et ce de manière plus ou moins autonome.
Ce type d’analyse permet d’avoir un profil des différents groupes. Cela permet donc de simplifier l’analyse des données en faisant ressortir les points communs et les différences et en réduisant ainsi le nombre de variable des données. Cette technique n’est pas seulement utilisée dans le domaine génétique, mais permet aussi par exemple de lister de potentiels clients lors d’une action publicitaire.
Clustering hiérarchique ou dendrogramme
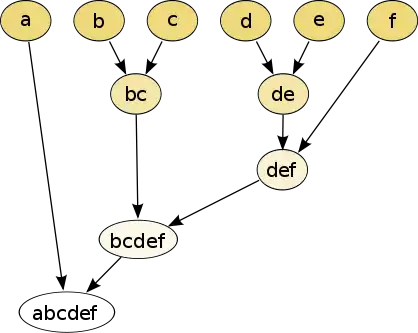
Le « clustering hiérarchique » est une autre technique de classification. Cette fois-ci, le paramètre comparé est décidé à l’avance. Ensuite, une fois le paramètre de comparaison choisi, la distance euclidienne est calculée [9]. Pour ce faire, on utilise sa définition donnée par l’équation (1).

Il suffit alors de lier les individus les plus proches entre eux, deux par deux, et ce jusqu’à former un diagramme en arbre appelé dendrogramme.
Les dendrogrammes se lisent de la façon suivante : pour connaître le niveau de proximité entre 2 individus, il faut regarder l’axe des ordonnées ; plus la liaison entre deux individus se fait à une ordonnée élevée, moins ceux-ci seront similaires du point de vue du paramètre observé. Si par ailleurs, nous voulons connaître les individus observés, il faut regarder l’axe des abscisses.
Selon le taux de proximité que nous souhaitons, il est alors possible de former un certain nombre de groupes.
Carte thermique
Une carte thermique est une représentation graphique de données statistiques dans une matrice à deux dimensions, qui utilise la technique de « clustering hiérarchique » . Les données y sont représentées sur une échelle reliant deux couleurs comme une couleur froide et une couleur chaude, d'où le nom de carte thermique, ou le noir et le blanc.
La couleur de la grille représente la valeur du paramètre utilisé pour relier les échantillons. On peut adopter la convention que plus la couleur est chaude (p. ex., rouge), plus la proximité est grande.
Différentes méthodes de tri peuvent être utilisées, par exemple un regroupement selon des caractéristiques connues ou un tri selon un paramètre externe.
Dans quel contexte peut-il être utile de réaliser une carte thermique ?
Cette technique de mise en relation de deux ensembles de données triés ayant une mesure en commun peut être utilisée dans beaucoup de domaines. Par exemple, durant le laboratoire, les données sont des mesures sur des gènes, les deux ensembles sont les patients et les gènes, le tri vient des dendrogrammes, et cela permet de localiser facilement, graphiquement, des catégories de patients liées à des catégories de gènes à risque. On peut utiliser le même concept sur des cartes thermiques.
De manière générale, on peut l’utiliser pour toute analyse descriptive, à partir du moment où il faut analyser un ensemble de données trop grand pour être analysé manuellement et qui correspond au type de données attendu par une carte thermique. Par exemple, la technique pourrait être utilisée pour trier des ponts, , ou bien pour déterminer quelles caractéristiques macroscopiques (mm-μm), associée à des compositions de matériaux (nm, molécules), ont les propriétés les plus intéressantes ; et ce ne sont que des exemples.
Intérêt et applications
Le partitionnement de données est une méthode de classification non supervisée (différente de la classification supervisée où les données d'apprentissage sont déjà étiquetées), et donc parfois dénommée comme telle.
Applications : on en distingue généralement trois sortes[1] :
- la segmentation d'une base de données ; elle peut servir à discrétiser une base de données.
La segmentation peut aussi permettre de condenser ou compresser les données d'une base de données spatiales (c'est-à-dire réduire la taille des paquets de données à traiter, dans l'ensemble de données considéré) ; par exemple, dans une image aérienne ou satellitaire un SIG peut traiter différemment les forêts, champs, prairies, routes, zones humides, etc. ici considérés comme des sous-espaces homogènes. Un traitement plus fin pouvant ensuite être appliqué à des sous-ensembles de ces classes (ex. : forêt de feuillus, de résineux, artificielles, naturelles, etc.).
OLAP est une méthode qui facilite l'indexation de telles bases ; - la classification (en sous-groupes, sous-populations au sein de la base de données), par exemple d'une base de données clients, pour la gestion de la relation client ;
- l'extraction de connaissances, qui se fait généralement sans objectif a priori (facteur de sérendipité, utile pour la génération d'hypothèse ou modélisation prédictive), pour faire émerger des sous-ensembles et sous-concepts éventuellement impossibles à distinguer naturellement.
Formalisation
Pour faire du partitionnement de données, lesdites données sont supposées être organisées dans une matrice dont chaque ligne correspond à un individu (ou observation) et chaque colonne correspond à un prédicteur (ou variable). On note le nombre d'individus et le nombre de prédicteurs : de telle façon, la matrice est de taille





L'objectif d'un algorithme de partitionnement sera de trouver les "meilleurs" groupes d'individus. Pour cela on se donne une dissimilarité entre les individus et (respectivement, ligne et de ).






Notons le nombre de groupes que l'on souhaite former. Cela revient à trouver une fonction d'attribution qui minimise une fonction coût.

![{\displaystyle C:[\![1,N]\!]\longrightarrow [\![1,K]\!]}](https://img.franco.wiki/i/3239a425c4d3befc8a4a8d385ea7b8d28d9ce9dc.svg)
Une fonction coût classique est la variabilité intra-classe (within-cluster variance en anglais) :

D'autres fonctions coûts existent (par exemple l'indice de Dunn, l'indice de Davies-Bouldin ou l'indice de Calinski-Harabasz). Elles peuvent être utilisées pour évaluer la qualité de classification[2].
Algorithmes
Il existe de multiples méthodes de partitionnement des données, parmi lesquelles :
- Les méthodes basées centroïdes telles que les algorithmes des k-moyennes ou k-médoïdes ;
- Les méthodes de regroupement hiérarchique ;
- Des algorithmes de maximisation de l'espérance (EM) ;
- Des algorithmes basés sur la densité tels que DBSCAN ou OPTICS ;
- Des méthodes connexionnistes telles que les cartes auto adaptatives.
Ces méthodes sont implémentées au sein de nombreux logiciels de fouille de données.
Notes et références
- ↑ Berkhin, 2002.
- ↑ (en) « Clustering Indices », sur cran.r-project.org, (consulté le )
Voir aussi
Bibliographie
- Anil K. Jain, M. N. Murty, P. J. Flynn, « Data Clustering: a Review », ACM Computing Surveys, vol. 31, no 3, . DOI 10.1145/331499.331504
- M.-S. Chen, J. Han, and P. S. Yu, « Data mining: an overview from a database perspective », IEEE Transactions on Knowledge and Data Engineering, vol. 8, no 6, p. 866–883, 1996.
- A. K. Jain, « Data clustering: 50 years beyond K-means », Pattern Recognition Letters, vol. 31, no 8, p. 651–666, .
Articles connexes
- Indice de Dunn
- indice de Davies-Bouldin
- Silhouette