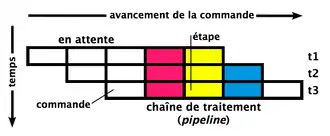
En microarchitecture, un pipeline (ou chaîne de traitement[1]), est l'élément d'un processeur dans lequel l'exécution des instructions est découpée en plusieurs étapes. Le premier ordinateur à utiliser cette technique est l'IBM Stretch, conçu en 1961. Avec un pipeline, le processeur peut commencer à exécuter une nouvelle instruction sans attendre que la précédente soit terminée. Chacune des étapes d’un pipeline est appelé étage. Le nombre d'étages d'un pipeline est appelé sa profondeur.
Analogie
Le pipeline est un concept s'inspirant du fonctionnement d'une ligne de montage. Considérons que l'assemblage d'un véhicule se compose de trois étapes (avec éventuellement des étapes intermédiaires) : 1. Installation du moteur. 2. Installation du capot. 3. Pose des pneus.
Un véhicule dans cette ligne de montage ne peut se trouver que dans une seule position à la fois. Une fois le moteur installé, le véhicule Y continue pour une installation du capot, laissant le poste « installation moteur » disponible pour un prochain véhicule X. Le véhicule Z se fait installer ses pneumatiques (roues) tandis que le second (Y) est à l'étape d'installation du capot. Dans le même temps un véhicule X commence l'étape d'installation du moteur.
Si l'installation du moteur, du capot et des roues prennent respectivement 20, 5 et 10 minutes, la réalisation de trois véhicules prendra, s'ils occupent un à un toute la chaîne de production, 105 minutes = (20 + 5 + 10) × 3. Si on place un véhicule dans la chaîne de production dès que l'étage auquel le véhicule doit accéder est libre (principe du pipelining), le temps total pour réaliser les trois véhicules est de (20+5+10) + 20×2 = 75 minutes (le temps d'assemblage d'un d'entre eux, plus autant de fois le temps de la plus longue étape qu'il ne reste de véhicules à monter, soit le temps minimum d'attente pour chaque véhicule).
Pipeline RISC classique
Pour donner un exemple de pipeline, nous allons aborder un pipeline parmi les plus connus. Celui-ci s'appelle le Classic RISC pipeline. Il s'agit du pipeline créé par David Patterson, inventeur des processeurs RISC et du concept de pipeline. Ce pipeline est utilisé dans de nombreux documents (cours de David Patterson, notamment) comme une introduction au concept de pipeline.
Avec ce pipeline, 5 étapes sont nécessaires pour traiter une instruction[2] :
- IF (Instruction Fetch) charge l'instruction à exécuter dans le pipeline.
- ID (Instruction Decode) décode l'instruction et adresse les registres.
- EX (Execute) exécute l'instruction (par la ou les unités arithmétiques et logiques).
- MEM (Memory), dénote un transfert depuis un registre vers la mémoire dans le cas d'une instruction du type STORE (accès en écriture) et de la mémoire vers un registre dans le cas d'un LOAD (accès en lecture).
- WB (Write Back) stocke le résultat dans un registre. La source de ce résultat peut être la mémoire (à la suite d'une instruction LOAD), l'unité de calcul (à la suite d'un calcul à l'étape EX) ou bien un registre (cas d'une instruction MOV).
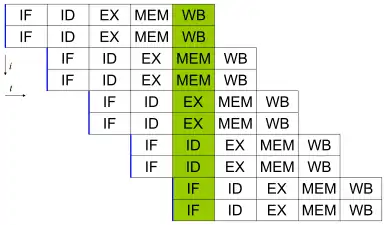
En supposant que chaque étape met 1 cycle d'horloge pour s'exécuter, il faut normalement 5 cycles pour exécuter une instruction, 15 pour 3 instructions :
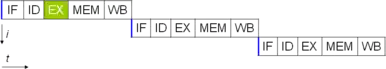
En utilisant la technique du pipeline, notre processeur peut alors contenir plusieurs instructions, chacune à une étape différente.
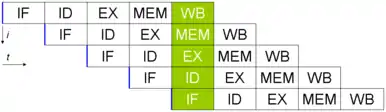
Les 5 instructions s'exécuteront en 9 cycles, et le processeur sera capable de terminer une instruction par cycle à partir de la cinquième, bien que chacune d'entre elles nécessite 5 cycles pour s'exécuter complètement. Au 5e cycle, tous les étages sont en cours d'exécution.
Autres pipelines
Une organisation alternative au pipeline RISC classique serait de découper nos instructions en seulement deux étapes :
- Une étape nommée Fetch, qui charge et décode une instruction, et qui met à jour le Program Counter ;
- et une étape nommée Exec, qui effectuerait l'opération proprement dite (avec les accès à la mémoire et/ou aux registres).
Ce type de pipeline est notamment utilisé sur certains microcontrôleurs Atmel AVR et PIC.
Autre exemple de pipeline : celui de l'IBM Stretch project composé des trois étapes suivantes :
- Fetch : chargement de l'instruction depuis la mémoire et mise à jour du Program Counter ;
- Decode : décodage de l'instruction ;
- Exec : exécution de l'instruction, avec éventuellement des accès mémoires.
On pourrait aussi créer un pipeline à 7 étages :
- PC : mise à jour du Program Counter ;
- Fetch : chargement de l'instruction depuis la mémoire ;
- Decode : décodage de l'instruction ;
- Register Read : lecture des opérandes dans les registres ;
- Exec : calcul impliquant l'ALU ;
- Mem : accès mémoire en lecture ou écriture ;
- Writeback : écriture du résultat d'une lecture ou d'un calcul dans les registres.
etc.
Certaines fonctionnalités de la microarchitecture d'un processeur nécessitent l'ajout d'étages de pipelines supplémentaires. Par exemple, un processeur implémentant le renommage de registres demandera une étape supplémentaire pour renommer les registres. En pratique, les processeurs les plus performants utilisent des pipelines extrêmement longs (de l'ordre d'une vingtaine d'étages) pour ajouter de nombreuses étapes augmentant les performances (exécution dans le désordre) et augmenter la fréquence d'horloge (moins de travail à chaque étage).
Profondeurs
Aujourd'hui tous les microprocesseurs sont pipelinés :
| Processeur | Profondeur |
|---|---|
| Intel Pentium 4 Prescott | 31 |
| Intel Pentium 4 | 20 |
| AMD K10 | 16 |
| IBM POWER5 | 16 |
| IBM PowerPC 970 | 16 |
| Intel Core 2 Duo | 14 |
| Intel Pentium II | 14 |
| Sun UltraSPARC IV | 14 |
| Sun UltraSPARC IIi | 14 |
| AMD Opteron 1xx | 12 |
| AMD Athlon | 12 |
| IBM POWER4 | 12 |
| Intel Pentium III | 10 |
| Intel Itanium | 10 |
| MIPS R4400 | 8 |
| Motorola PowerPC G4 | 7 |
Certaines architectures ont largement augmenté le nombre d'étages, celui-ci pouvant aller jusqu'à 31 pour la microarchitecture Prescott d'Intel. Une telle architecture sera appelée superpipelinée.
Mise en œuvre
Dans un processeur doté de pipeline, chaque étape d'une instruction doit être effectuée dans un circuit séparé des autres. Cela n'est pas toujours possible, et il arrive que certains circuits communs doivent malgré tout être partagés, comme les ports d'accès au cache, et qu'il soit possible de bloquer le pipeline pour attendre un résultat précédent. Mais, en principe, un pipeline dispose d'un circuit pour traiter chaque étape.
En électronique, les pipelines sont une classe de circuit bien plus importante que ce que l'on appelle « pipeline » dans un processeur : il s'agit de tout type de circuit où des données progressent. Tous les circuits électroniques comportent donc des pipelines, avec des structures parfois complexes (des boucles et des embranchements par exemple).
Le pipeline traitant les instructions d'un processeur est plus complexe qu'un pipeline où les instructions avanceraient d'étage en étage : il comporte des étapes d'interaction avec les registres, la mémoire et les unités de calcul, et souvent la possibilité de bloquer la progression des données pour attendre la résolution d'une instruction.
Reste que les données doivent passer d'un étage à un autre. Pour ce faire, il existe trois grands types d'implémentations :
- les pipelines synchrones ;
- les pipelines asynchrones ;
- les pipelines à vagues.
Synchrones
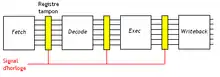
Les différents étages sont séparés par des registres tampons, qui sont tous reliés au signal d'horloge du processeur. À chaque cycle d'horloge, les registres deviennent accessibles en écritures, ce qui fait que les données passent à l'étage suivant. C'est de loin la technique la plus utilisée.
Asynchrones
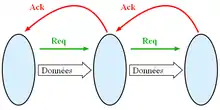
Les différents étages sont séparés par des registres tampons, et les transferts entre registres sont décidés par un protocole asynchrone.
À vagues
Il n'y a pas de registres entre les étages : en contrôlant leur vitesse de propagation, les données envoyées une par une dans le pipeline sont récupérées dans l'ordre à l'autre bout sans nécessiter de mémorisation temporaire.
Problèmes ou aléas
Les pipelines provoquent de nouveaux problèmes, en particulier d'interdépendance, ils ne sont pas tous listés ci-dessous, juste deux cas simples sont abordés.
Dépendances structurelles
Il arrive que dans certains cas bien précis, plusieurs étages du pipeline aient besoin d’accéder à la même ressource matérielle. Cette ressource peut être la mémoire, un registre, une unité de calcul, ou tout autre chose encore. Si celle-ci n'est pas conçue pour cela, deux instructions entrent en concurrence pour l'accès à cette ressource. Une des deux doit passer avant l'autre, et l'autre instruction doit être mise en attente. Dans ce cas, il peut être nécessaire de bloquer tous les étages du pipeline qui précèdent l'instruction bloquée. Idéalement, ce genre de dépendance se règle souvent en dupliquant la ressource à partager. Il suffit de dupliquer la ressource fautive en autant d'exemplaires qu'il peut en avoir besoin simultanément dans le pipeline. Cela dit, ce n'est pas toujours possible, notamment pour les accès mémoires.
Dépendances de données
Deux instructions ont une dépendance de donnée si elles veulent lire ou écrire dans le même registre ou la même adresse mémoire. Différents cas se présentent alors, suivant que les deux instructions écrivent ou lisent cette donnée.
| Type | Effets |
|---|---|
| Read after Read | Nos deux instructions doivent lire la même donnée, mais pas en même temps ! |
| Read after write | La première instruction va écrire son résultat dans un registre ou dans la RAM, et un peu plus tard, la seconde va lire ce résultat et effectuer une opération dessus. |
| Write after Read | La première instruction va lire un registre ou le contenu d'une adresse en RAM, et la seconde va écrire son résultat au même endroit un peu plus tard. |
| Write after Write | Nos deux instructions effectuent des écritures au même endroit : registre ou adresse mémoire. |
Ces dépendances imposent un certain ordre d’exécution pour nos instructions. L'ordre d’exécution des lectures et des écritures ne doit pas changer, sous peine de se retrouver avec des résultats faux. Or, sur les processeurs dotés de pipeline, il se peut que les lectures et écritures changent d'ordre : les lectures et écritures dans les registres ne se font pas aux mêmes étages, et une instruction peut donc lire une donnée pas encore écrite, etc.
Respecter l'ordre des lecture/écriture en mémoire et dans les registres peut être très complexe et nécessite la présence de circuits capables de maintenir cet ordre. Diverses optimisations existent pour rendre la situation plus supportable. Certaines dépendances peuvent être éliminée via renommage de registres, ou par des mécanismes de memory disambiguation. D'autres techniques comme le Forwarding/Bypassing permettent de diminuer l'impact de ces dépendances sur les performances.
Dépendances de contrôle
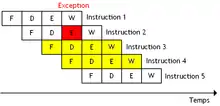
Les branchements, les exceptions matérielles et les interruptions posent quelques problèmes. Lorsqu'un branchement entre dans le pipeline, l'adresse à laquelle brancher n'est connue que quelques cycles plus tard, vers la fin de l'étage de Decode dans le meilleur des cas. La même chose arrive lors de la levée d'une exception ou d'une interruption.
Pourtant, entre le moment où le branchement entre dans le pipeline et celui où l'adresse est connue, le processeur aura continué de charger des instructions dans son pipeline. Des instructions sont ainsi chargées par erreur dans le pipeline. Sur le schéma de droite, ce sont les instructions en jaune. Pour réduire ce genre de problèmes, les processeurs peuvent fournir diverses fonctionnalités, comme des branch delay slots (en), ou des mécanismes de prédiction de branchement.
Architecture superscalaire
Une architecture superscalaire contient plusieurs pipelines en parallèle. Il est possible d'exécuter plusieurs instructions simultanément. Sur un processeur superscalaire de degré 2, deux instructions sont chargées depuis la mémoire simultanément. C'est le cas des processeurs récents conçus pour maximiser la puissance de calcul. Notons toutefois qu'en général, chaque pipeline est spécialisé dans le traitement d'un certain type d'instruction : aussi seules des instructions de types compatibles peuvent être exécutées simultanément.
Architecture vectorielle
Sur de tels processeurs, une instruction va s'appliquer à un ensemble de données, appelé vecteur. Une seule instruction va donc exécuter la même opération de façon parallèle sur tout le vecteur. Ce genre d'architecture est efficace pour les applications de calcul scientifique et s'est notamment trouvée dans les superordinateurs comme les Cray.
Notes et références
Articles connexes
- Pipelining HTTP
- Multiplieur-accumulateur