في الرؤية الحاسوبية ، يمكن تطبيق نموذج حقيبة الكلمات bag-of-words model لتصنيف الصور عن طريق معاملة ملامح الصور image features كأنها كلمات.[1][2][3] ففي مجال التعرف و تصنيف الوثائق، حقيبة الكلمات هي عبارة عن متجهه رياضي vector يعبر عن مدي تكرار هذه الكلمات في النص و يكون ذلك عن طريق مدرج تكراري histogram لكل الكلمات الممكنة في النص. أما في مجال الرؤية الحاسوبية تكون حقيبة الكلمات هي عبارة عن مدرج تكراري يعبر عن مدي تكرار ملمح معين للصورة في صورة معينة.

التمثيل بناءً علي نموذج حقيبة الكلمات
تمثيل الصور بناءً علي نموذج حقيبة الكلمات
لتمثيل صورة عن طريق نموذج حقيبة الكلمات، يتم معاملة الصورة كأنها وثيقة نصية. بالمثل ؛ يجب تعريف الكلمات الممثلة للصور. و للوصول إلي ذلك يتم إتباع ثلاثة خطوات أساسية: اكتشاف ملامح الصور Feature detection ، توصيف ملامح الصور Feature description ، إنتاج قاموس ملامح الصور codebook generation. و هنا؛ يمكن تعريف نموذج حقيبة الكلمات علي أنه : "تمثيل ملامح الصور المستقلة عن طريق مدرج تكراري".
تمثيل ملامح الصور

بعد اكتشاف ملامح الصورة، يتم التعبير عن الصورة عن طريق مجموعة من رقع محلية مختلفة. طريقة تمثيل ملامح الصورة تعتمد في الأساس علي كيفية التعبير عن هذه الرقعة patch بشكل متجه عددي vector . و يجب أن يعبر الوصف الجيد للرقعة علي مدي الإضاءة intensity ، مدي الدوران rotation ، مقياس الرسم scale و غير ذلك من الصفات. أحد أشهر و أهم طرق وصف الرقع يسمي SIFT. فهذه الطريقة تقول بتحويل كل رقعة في الصورة إلي متجه عددي طوله 128 عنصر. بعد الانتهاء من هذه الخطوة يتم التعبير عن كل صورة بعدد من هذه المواصفات حيث يعد ترتيب هذه المواصفات غير مهم.
إنتاج قاموس ملامح الصور
أخر خطوة في نموذج حقيبة الكلمات هو تحويل المتجه العددي الممثل لرقع الصور إلي قاموس كلمات. تعتبر الكلمة داخل هذا القاموس تمثيلاً لعدد مختلف من الرقع المتشابهة. أحد الطرق السهلة للوصول إلي ذلك هو تطبيق خوارزم مشهور للتقسيم يسمي k-means clustering علي جميع المواصفات المجمعة من كل الصور. بعد تنفيذ هذا الخوارزم تكون كلمات القاموس عبارة عن مراكز المجموعات المقسمة. و يعتبر عدد هذه المراكز هو حجم قاموس الكلمات.
بعد ذلك يتم حساب مدي انتماء كل ملمح في الصورة لهذه المراكز المجمعة في قاموس الكلمات، و يتم تمثيل الصورة كاملة في صورة مدرج تكراري histogram.
التعلم و التعرف بناءً علي نموذج حقيبة الكلمات
لقد طور الباحثون في علم الرؤية الحاسوبية العديد من طرق التعليم للاستفادة من نموذج حقيبة الكلمات في المهام المتعلقة بالصور، مثل تصنيف العناصر أو تصنيف المشاهد. هذه الطرق يمكن بالكاد تقسيمها إلي نماذج منتجة، و نماذج مميزة. في حالة تصنيف العديد من التصنيفات، يمكن استخدام مصفوفة التشويش كعامل لقياس مدي جودة التصنيف.
النماذج المنتجة Generative models
بما أن نموذج حقيبة الكلمات هو نموذج مشابه معالجة اللغات الطبيعية ، فإن النماذج المنتجة قد تم تطويرها في الأساس في مجال معالجة الكلمات و تم تبنيها في مجال الرؤية الحاسوبية و سوف نقوم بإستعراض طريقتين من هذه الطرق.
طريقة Naïve Bayes
تعتبر طريقة مميز Naïve Bayes هي أبسط الطرق. حيث يقوم بإستخدام لغة النماذج المرئية graphical models. الفكرة الأساسية لهذا النموذج هي أن لكل تصنيف توزيعة معينة علي قاموس الكلمات codebook ، و هذه التوزيعة تختلف من تصنيف لتصنيف أخر. فعلى سبيل المثال تصنيف الوجوه و تصنيف السيارات؛ فتصنيف الوجه سيحتوي على قيم أكبر عند كلمات مثل "الأنف" ، "العين" ، "الفم" ، بينما تصنيف السيارة سيحتوي على قيم أكبر عند كلمات مثل "نافذة" ، "إطار". يقوم هذا المميز بتعلم هذه التوزيعات عن طريق تدريبه بعدد من أمثلة التدريب.
و بما أن هذا المميز يتميز ببساطته و فعاليته، فهو في العادة يستخدم كأداة للمقارنة.
نماذج Bayes الهرمية
في الطريقة السابقة كان الفرض الأساسي هو أن التوزيعة بالنسبة لكتاب الكلمات مميزة تماماً و لا تتكرر. و لكن هذا الشرط غير صالح في جميع الأحوال. على سبيل المثال قد يكون هناك تصنيف معين يحتوي على كثير من الكلمات المتداخلة كصورة بها وجوه و سيارات. هناك طريقتان للقضاء علي هذه المشكلة و سنأخذ أحدهما كمثال و هي Latent Dirichlet allocation . فمثلاً لتمثيل صورة طبيعية معينة بإستخدام هذه الطريقة يكون عن طريق التالي:
- تصنيف الصورة يكون مثل تصنيف الملف.
- خليط التصنيفات في الصورة يماثل خليط الموضوعات في الملف النصي.
- مفتاح التصنيف يماثل مفتاح الموضوعات.
- الملمح الصوري يماثل الكلمة في قاموس الكلمات.
و قد أظهرت هذه الطريقة نتائج مبشرة في تصنيف المشاهد الطبيعية علي 13 Natural Scene Categories.
النماذج المميزة Discriminative models
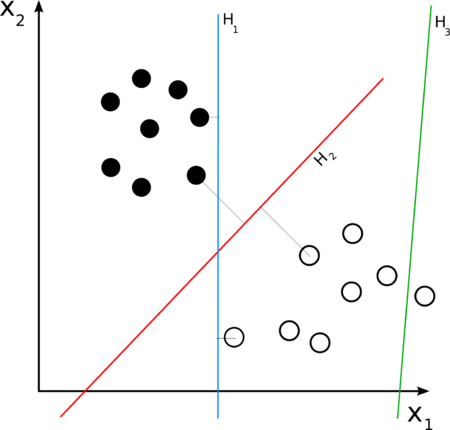
و بما إن التعبير عن الصور يتم عن طريق نموذج حقيبة الكلمات، فإن أي نموذج مميز مناسب لتمييز الكلمات يمكن محاولته أيضاً، مثال ذلك آله متجه الدعم Support vector machine ، أو AdaBoost. و أيضاً kernel trick هي طريقة مناسبة عند استخدام مميز معتمد علي النواة kernel based classifier. نواة المطابقة الهرمية أو Pyramid match kernel هي أحد الطرق الحديثة التي تم تطويرها اعتمادا علي نموذج حقيبة الكلمات، هذا النموذج يتم تدريب مميز classifier به، و قد تم اختباره مع كثير من الأمثلة. و قد أظهر نتائج مبشرة علي عدد من الأنماط التي تم الاختبار عليها و تسجيل نتائجها.
نواة المطابقة الهرمية Pyramid match kernel
نواة المطابقة الهرمية هي خوارزم سريع يقوم بمطابقة عدد من الملامح في نموذج حقيبة الكلمات إلي مدرجات تكرارية في مستوي متعدد الدقة. أحد مميزات استخدام مدرج تكراري متعدد الدقة هي إمكانية التقاط و تسجيل الملامح المتكررة و المتقاربة. نواة المطابقة الهرمية يقوم ببناء المدرج التكراري متعدد الدقة عن طريق تسجيل نقاط المعلومات في نطاقات متدرجة و متزايدة في الحجم. لذلك فإن النقاط التي لا يتم مطابقتها في الدقة العالية، فهناك احتمالية ليتم مطابقتها في الدقة الأقل. و لقد تم تطبيق هذا الخوارزم علي مجموعات متعددة من الصور مثل ETH-80 database و Caltech 101 database ، و أظهر نتائج مبشرة.
القيود و آخر التطورات
أحد عيوب نموذج حقيبة الكلمات هو أنه يتجاهل العلاقات المكانية للرقعات و الملامح، هذه العلاقات تعد من أهم العناصر في تمثيل الصور. و قد عرض الباحثون العديد من الطرق للتغلب علي هذه المشكلة و محاولة تسجيل العلاقات المكانية للملامح.
بالإضافة إلي ذلك، فإن نموذج حقيبة الكلمات لم يتم اختباره بطريقة قوية و مركزه في حالة اختلاف حجم الملامح و مقياس رسمها، و مازال إلي الآن أداءه غير واضح. و أيضاً يضاف إلي ذلك أن هذا المجال -نموذج حقيبة الكلمات- يفتقد إلي الدراسة المتعمقة فيه.
انظر أيضاً
مراجع
- T. Leung; J. Malik (2001). "Representing and recognizing the visual appearance of materials using three-dimensional textons" ( كتاب إلكتروني PDF ). International Journal of Computer Vision. 43 (1): 29–44. doi:10.1023/A:1011126920638. مؤرشف من الأصل ( كتاب إلكتروني PDF ) في 4 مارس 2016.
- Fei-Fei Li; Perona, P. (2005). "A Bayesian Hierarchical Model for Learning Natural Scene Categories". 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). 2: 524. doi:10.1109/CVPR.2005.16. .
- Koniusz, Piotr; Yan, Fei; Mikolajczyk, Krystian (2013-05-01). "Comparison of mid-level feature coding approaches and pooling strategies in visual concept detection". Computer Vision and Image Understanding. 117 (5): 479–492. doi:10.1016/j.cviu.2012.10.010. ISSN 1077-3142. مؤرشف من الأصل في 15 ديسمبر 2019.
وصلات خارجية
- Bag of features Implementation Details By: A.Vedaldi
- Lazebnik, S.; Schmid, C.; Ponce, J.; , "Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories," Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on , vol.2, no., pp. 2169- 2178, 2006
- Bag of Visual Words – Efficient window histogram computation
- Two bag-of-words classifiers
- Caltech Large Scale Image Search Toolbox