En informatique, le nombre entier est un type de données qui est généralement représenté sur plusieurs octets. Le boutisme (endianness en anglais) ou plus rarement endianisme désigne l'ordre dans lequel ces octets sont placés. Il existe deux conventions opposées : l'orientation gros-boutiste (ou gros-boutienne) qui démarre avec les octets de poids forts, et l'orientation inverse petit-boutiste (ou petit-boutienne).
L'expression est utilisée de manière plus générale pour désigner l'ordre des chiffres dans un système de numération positionnel (par exemple celui des bits).
Le choix du boutisme est typiquement fixé par l'architecture du processeur, ou par le format de données d'un fichier ou d'un protocole.
Étymologie

Gros-boutiste et petit-boutiste viennent des termes anglais big-endian et little-endian, popularisés dans le domaine informatique par Dany Cohen[1], en référence aux Voyages de Gulliver, conte satirique de Jonathan Swift. En 1721, Swift décrit comment de nombreux habitants de Lilliput refusent d'obéir à un décret obligeant à manger les œufs à la coque par le petit bout. La répression pousse les rebelles, dont la cause est appelée big-endian[2], à se réfugier dans l'empire rival de Blefuscu, ce qui entretient une guerre longue et meurtrière entre les deux empires.
En 1980, Cohen publie « une tentative pour arrêter une guerre[1] », celle qui oppose les partisans big-endian et little-endian au sein du groupe qui travaille sur les protocoles réseau qui conduiront à Internet. Dans sa note technique, il indique qu'aucune argumentation logique ne peut montrer la supériorité d'une convention sur l'autre ; cependant, dans le domaine informatique, un choix doit être fait pour éviter le désordre.
En 1727, Pierre-François Guyot Desfontaines, traduit en français pour la première fois le roman de Swift[N 1]. Dans cette traduction, il utilise le terme gros-boutien, par exemple dans le chapitre 4[3]. L'Office québécois de la langue française préconise gros-boutiste[4] et petit-boutiste[5], ce qui conduit au nom boutisme pour traduire endianness.
En informatique, il n'y a pas vraiment de préférence pour le suffixe -iste[N 2]. Le suffixe -iste fait référence à un partisan d'une doctrine, alors que -ien désigne plutôt un membre d'une communauté (à titre d'exemple, on dit linuxien et non linuxiste). En l'occurrence gros-boutiste semblerait plus approprié.
Dans les ordinateurs
Gros-boutisme
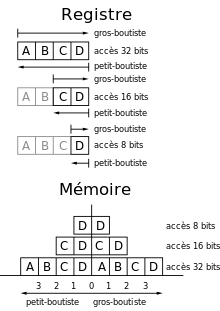
Quand certains ordinateurs enregistrent un entier sur 32 bits en mémoire, par exemple 0xA0B70708 en notation hexadécimale, ils l'enregistrent dans des octets dans l'ordre qui suit : A0 B7 07 08, pour une structure de mémoire fondée sur une unité atomique de 1 octet et un incrément d'adresse de 1 octet. Ainsi, l'octet de poids le plus fort (ici A0) est enregistré à l'adresse mémoire la plus petite, l'octet de poids inférieur (ici B7) est enregistré à l'adresse mémoire suivante et ainsi de suite.
0 |
1 |
2 |
3 |
||
... |
A0 |
B7 |
07 |
08 |
... |
Pour une structure de mémoire ou un protocole de communication fondé sur une unité atomique de 2 octets, avec un incrément d'adresse de 1 octet, l'enregistrement dans des octets sera A0B7 0708. L'unité atomique de poids le plus fort (ici A0B7) est enregistrée à l'adresse mémoire la plus petite.
0 |
1 |
2 |
3 |
||
... |
A0 |
B7 |
07 |
08 |
... |
Les architectures qui respectent cette règle sont dites gros-boutistes, big-endian ou « mot de poids fort en tête ». C'est le cas par exemple pour les processeurs Motorola 68000, les SPARC (Sun Microsystems) ou encore les System/370 (IBM).
De plus, tous les protocoles TCP/IP communiquent en gros-boutiste[6]. Il en va de même pour le protocole PCI Express.
Petit-boutisme
Les autres ordinateurs enregistrent 0xA0B70708 dans l'ordre suivant : 08 07 B7 A0 (pour une structure de mémoire fondée sur une unité atomique de 1 octet et d'un incrément d'adresse de 1 octet), c'est-à-dire avec l'octet de poids le plus faible en premier. De telles architectures sont dites petit-boutistes, little-endian ou « mot de poids faible en tête ». Par exemple, les processeurs x86 ont une architecture petit-boutiste. Celle-ci, au prix d'une moindre lisibilité du code machine par le programmeur, simplifiait la circuiterie de décodage d'adresses courtes et longues en 1975, quand un 8086 avait 29 000 transistors. Elle est d'influence pratiquement nulle en 2016, aussi bien en temps d'exécution (masqué) que d'encombrement (un Haswell typique comporte 1,4 milliard de transistors).
0 |
1 |
2 |
3 |
||
... |
08 |
07 |
B7 |
A0 |
... |
Pour une structure de mémoire ou un protocole de communication fondé sur une unité atomique de 2 octets, avec un incrément d'adresse de 1 octet, l'enregistrement dans des octets sera 0708 A0B7. L'unité atomique de poids le plus faible (ici 0708) est enregistré à l'adresse mémoire la plus petite.
0 |
1 |
2 |
3 |
||
... |
07 |
08 |
A0 |
B7 |
... |
Bi-boutisme
Certaines architectures supportent les deux règles, par exemple les architectures PowerPC (IBM), ARM, DEC Alpha, MIPS, PA-RISC (HP) et IA-64 (Intel). On les appelle bytesexual (jargon), bi-endian ou bi-boutistes. Le choix du mode peut se faire au niveau logiciel, au niveau matériel ou aux deux.
Mi-boutisme
Certaines autres rares architectures, appelées mi-boutistes[7] ou middle-endian, ont un ordonnancement plus complexe : les octets composant les unités atomiques subissent une opération d'inversion. Par exemple 0xA0B70708 est enregistré dans une mémoire mi-boutiste dont les unités atomiques sont de 2 octets, avec un incrément d'adresse de 1 octet, dans l'ordre : 0807 B7A0 ou bien B7A0 0807.
0 |
1 |
2 |
3 |
|||
... |
08 |
07 |
B7 |
A0 |
... |
mi-boutiste, unité atomique 2 octets, incrément d'adresse 1 octet |
ou alternativement
0 |
1 |
2 |
3 |
|||
... |
B7 |
A0 |
08 |
07 |
... |
mi-boutiste, unité atomique 2 octets, incrément d'adresse 1 octet |
Il existe une ambiguïté dans la représentation de cette donnée. En effet, l'information de boutisme sur la manière d'ordonner les unités atomiques existe toujours bel et bien. On utilise donc les termes de gros-boutiste ou petit-boutiste associés à une caractéristique de byte-swap, plutôt que celui de mi-boutiste. L'exemple devient dès lors non ambigu :
1. Dans une mémoire petit-boutiste avec byte-swap, 2 octets d'unité atomique, 1 octet d'incrément d'adresse, 0xA0B70708 est représenté par 0807 B7A0, 08 étant à l'adresse 0.
0 |
1 |
2 |
3 |
|||
... |
08 |
07 |
B7 |
A0 |
... |
petit-boutiste, byte-swap, unité atomique 2 octets, incrément d'adresse 1 octet |
2. Dans une mémoire gros-boutiste avec byte-swap, 2 octets d'unité atomique, 1 octet d'incrément d'adresse, 0xA0B70708 est représenté par B7A0 0807, B7 étant à l'adresse 0.
0 |
1 |
2 |
3 |
|||
... |
B7 |
A0 |
08 |
07 |
... |
gros-boutiste, byte-swap, unité atomique 2 octets, incrément d'adresse 1 octet |
Il est plus difficile de travailler avec de tels processeurs, les PDP-11 par exemple.
Ordre des bits
Dans une architecture gros-boutiste, les bits sont conventionnellement numérotés de la gauche vers la droite. Ainsi le bit de poids le plus fort est le bit 0, et le bit de poids le plus faible est le 7 dans un octet. Dans une architecture petit-boutiste, c'est le contraire.
Si l'octet doit représenter un nombre entier, alors la convention gros-boutiste peut porter à confusion car le poids du bit n est alors 27-n (au lieu de 2n avec la convention petit-boutiste). En revanche, elle convient mieux pour représenter une fraction binaire, le poids du bit n étant alors 2-n (contre 2n-7 pour petit-boutiste).
Un moyen mnémotechnique pour ne pas confondre les deux notations consiste à remplacer « boutiste » par « tête ». On a alors :
- « gros-tête » pour les bits de poids « fort en tête » ;
- « petit-tête » pour les bits de poids « faible en tête ».
Dans les systèmes d'exploitation (par architectures)
Sur architecture petit-boutiste :
- DragonFly BSD sur x86, et x86-64
- ESX sur x86, x86-64
- FreeBSD sur x86, x86-64, MIPS, ARM et Itanium
- iOS sur ARM
- Linux sur x86, x86-64, MIPSEL, Alpha, Itanium, S+core, MN103, CRIS, Blackfin, MicroblazeEL, ARM, M32REL, TILE, SH, XtensaEL et UniCore32
- Mac OS X sur x86, x86-64
- NetBSD sur x86, x86-64, Itanium, etc.
- OpenBSD sur x86, x86-64, Alpha, VAX, Loongson (MIPSEL)
- OpenVMS sur VAX, Alpha et Itanium
- Solaris sur x86, x86-64, PowerPC
- Tru64 UNIX sur Alpha
- Windows sur x86, x86-64, Itanium, Alpha, IBM PowerPC (NT-3.51 et 4.0 seulement) et MIPS.
Sur architecture gros-boutiste :
- AIX sur POWER
- AmigaOS sur PowerPC et 680x0
- FreeBSD sur MIPS, ARM, PowerPC et SPARC
- HP-UX sur Itanium et PA-RISC
- IRIX sur MIPS
- Linux sur MIPS, SPARC, PA-RISC, POWER, PowerPC, 680x0, ESA/390, z/Architecture, H8, FR-V, AVR32, Microblaze, ARMEB, M32R, SHEB, Xtensa et ubicom32.
- Mac OS sur PowerPC et 680x0
- Mac OS X sur PowerPC
- MorphOS sur PowerPC
- MVS and DOS/VSE sur ESA/390, and z/VSE et z/OS on z/Architecture
- NetBSD sur PowerPC, SPARC, etc.
- OpenBSD sur PowerPC, SPARC, PA-RISC, SGI (MIPSEB), Motorola 68k et 88k, Landisk (SuperH-4)
- Solaris sur SPARC
Dans les communications
On appelle cela le problème NUXI, en effet si on veut envoyer la chaîne « UNIX » en regroupant deux octets par mot entier de 16 bits sur une machine de convention différente, alors on obtient NUXI. Ce problème a été découvert en voulant porter une des premières versions d'Unix d'un PDP-11 mi-boutiste sur une architecture IBM gros-boutiste.
Le protocole IP définit un standard, le network byte order (soit ordre des octets du réseau). Dans ce protocole, les informations binaires sont en général codées en paquets, et envoyées sur le réseau, l'octet de poids le plus fort en premier, c'est-à-dire selon le mode gros-boutiste et cela quel que soit le boutisme naturel du processeur hôte.
Les périphériques doivent aussi respecter une convention afin d'assurer la cohérence du système. Tout cela est fixé par le protocole de la couche de liaison du modèle OSI.
Différences pratiques
Bien que la différence entre les modes gros-boutiste et petit-boutiste semble aujourd'hui minime et se limite à un problème de convention, on peut signaler des avantages liés à chacun :
Le mode petit-boutiste présentait des avantages lorsque les processeurs utilisaient des tailles de registre variables, c’est-à-dire 8, 16 ou 32 bits. À partir d'une adresse mémoire donnée, on pouvait lire le même nombre en lisant 8, 16 ou 32 bits.
Par exemple, le nombre 33 (0x21 en hexadécimal) s'écrit 2100 0000 en petit-boutiste sur 32 bits et 2100 en petit-boutiste sur 16 bits, ce qui se lit toujours 21 quel que soit le nombre d'octets lus. Cela est faux en gros-boutiste car la première adresse change suivant le nombre d'octets à lire.
Pour sa part, le mode gros-boutiste offrait un meilleur confort de lecture pour les êtres humains (de langue européenne) lorsque ceux-ci devaient lire des nombres représentés sur plusieurs octets à l'intérieur de dumps mémoire, puisque cette convention d'écriture correspond à celle utilisée pour écrire les nombres dans les langues européennes (de la gauche vers la droite, on écrit les chiffres de poids décroissant).
Par exemple, le nombre 87 653 (0x15665 en hexadécimal) s'écrit 0001 5665 en gros-boutiste sur 32 bits, ce qui correspond à l'écriture usuelle dans les langues indo-européennes. Ce n'est pas le cas avec le mode petit-boutiste, dans lequel le même nombre s'écrit 6556 0100 sur 32 bits : avant de pouvoir le lire, il faut alors mentalement inverser les octets un par un, ce qui n'est pas usuel (pour les êtres humains de langue européenne) et exige un effort cérébral important.
Logiciels et portabilité
On a bien compris que ces conventions posent des problèmes dans le portage des logiciels. Par exemple, en lisant des données binaires, selon l'architecture, on ne va pas obtenir la même donnée après lecture si on ne se soucie pas de la convention.
Bien sûr le choix de gros-boutiste ou petit-boutiste est toujours arbitraire, ce qui soulève des débats intensifs, car il y a nombre d'arguments en faveur de l'un et de l'autre. Ainsi, une rupture de communication en cours de transmission favorise le grosboutisme, car on a transmis une valeur approximative (arrondie) de ce qu'on veut transmettre. Les langues par exemple, selon le groupe linguistique germanique, anglais ou autre, n'ont pas la même perception.
Écriture des nombres dans les langues humaines
Les langues humaines n'ont pas toutes la même convention pour la transcription des nombres.
Le produit de trois par sept a la même valeur en France et en Allemagne. Ce nombre se prononce « vingt-et-un » en français (ce qui correspond à une convention gros-boutiste) ; en allemand, il se dit « einundzwanzig », c'est-à-dire « un et vingt ». Dans chacune de ces langues, la convention d'écriture en toutes lettres reflète la prononciation orale.
En arabe, quand on écrit un nombre en chiffres en suivant le sens habituel d'écriture de l'arabe, on commence par écrire le chiffre des unités, puis celui des dizaines, pour finir avec le chiffre de poids le plus fort : ce qui est analogue à une convention petit-boutiste. Comme l'arabe s'écrit de droite à gauche, le chiffre des unités est à droite de la page. À l'opposé, pour écrire un nombre en chiffres dans un texte en français, on commence par le chiffre de poids le plus fort, pour terminer par le chiffre des unités : c'est donc une convention gros-boutiste, par rapport au sens d'écriture usuel du français. Néanmoins, comme le français et l'arabe s'opposent à la fois sur le boutisme et sur leur sens d'écriture usuel, dans les deux cas, le chiffre des unités est à droite de la page, et le chiffre de poids le plus fort se trouve à gauche.
Écriture des dates
Certains pays ont des standards concernant l'écriture des dates. La notion de boutisme y est présente comme le montrent les exemples suivants :
- Europe : JJ/MM/AAAA (petit-boutiste)
- Japon ou Chine : AAAA/MM/JJ (gros-boutiste)
- États-Unis : MM/JJ/AAAA (mi-boutiste)
- Standard ISO 8601 : AAAA-MM-JJ (gros-boutiste)
Notes et références
Notes
- ↑ Le voyage de Gulliver à Lilliput traduit sur Wikisource.
- ↑ Le débat n’est pas encore tranché, la guerre entre les boutistes et les boutiens, sur les forums et listes de discussions Internet, n’étant pas moins féroce qu’à Lilliput, et les partisans de chaque camp prenant référence de chaque côté à une traduction française publiée ou une autre des mêmes Voyages de Gulliver !
Références
- 1 2 Danny Cohen: On Holy Wars and a Plea for Peace. IETF, avril 1980.
- ↑ texte original sur wikisource.
- ↑ Jonathan Swift, « CHAPITRE IV. », dans Les Voyages de Gulliver : Voyage à Lilliput, Hiard, (lire en ligne), p. 51–60
- ↑ « mode gros-boutiste », sur gdt.oqlf.gouv.qc.ca (consulté le )
- ↑ « mode petit-boutiste », sur gdt.oqlf.gouv.qc.ca (consulté le )
- ↑ (en) Michael Barr et Anthony Massa, Programming Embedded Systems : With C and GNU Development Tools, O'Reilly Media, Inc., (lire en ligne)
- ↑ « Debian -- Lexique », sur debian.org (consulté le )
Voir aussi
Article connexe
- Alignement en mémoire
Lien externe
- (en) [PDF] White Paper: Endianness or Where is Byte 0?