En théorie de l'information, l'entropie de Shannon, ou plus simplement entropie, est une fonction mathématique qui, intuitivement, correspond à la quantité d'information contenue ou délivrée par une source d'information. Cette source peut être un texte écrit dans une langue donnée, un signal électrique ou encore un fichier informatique quelconque (suite d'octets). Elle a été introduite par Claude Shannon.
Du point de vue d'un récepteur, plus la source émet d'informations différentes, plus l'entropie (ou incertitude sur ce que la source émet) est grande. Ainsi, si une source envoie toujours le même symbole, par exemple la lettre 'a', alors son entropie est nulle, c'est-à-dire minimale. En effet, un récepteur qui connaît seulement les statistiques de transmission de la source est assuré que le prochain symbole sera un 'a'. Par contre, si la source envoie un 'a' la moitié du temps et un 'b' l'autre moitié, le récepteur est incertain de la prochaine lettre à recevoir. L'entropie de la source dans ce cas est donc non nulle (positive) et représente quantitativement l'incertitude qui règne sur l'information émanant de la source. L'entropie indique alors la quantité d'information nécessaire pour que le récepteur puisse déterminer sans ambiguïté ce que la source a transmis. Plus le récepteur reçoit d'information sur le message transmis, plus l'entropie (incertitude) vis-à-vis de ce message croît. En particulier, plus la source est redondante, moins elle contient d'information. En l'absence de contraintes particulières, l'entropie est maximale pour une source dont tous les symboles sont équiprobables.
Historique
Au début des années 1940, les télécommunications étaient dominées par le mode analogique. Les sons et les images étaient transformés en signaux électriques dont l'amplitude et/ou la fréquence sont des fonctions continues du signal d'entrée. Un bruit ajouté pendant la transmission résultait en une dégradation du signal reçu. L'archétype de ce type de bruit prend la forme de grésillement pour la radio et de neige pour la télévision. Aujourd'hui, les signaux sont également codés sous forme numérique. Un bruit ajouté pendant la transmission se traduira par une erreur sur les données numériques transmises, se manifestant par exemple par l'apparition de pixels aberrants sur une image de télévision. Dans les deux cas, on souhaite d'une part transmettre le maximum de données en un minimum de temps sur un canal de transmission donné, d'autre part, on souhaite pouvoir corriger les altérations dues au bruit dans une limite donnée.
En 1948, Claude Shannon, ingénieur en génie électrique aux Laboratoires Bell, formalisa mathématiquement la nature statistique de « l'information perdue » dans les signaux des lignes téléphoniques. Pour ce faire, il développa le concept général d'entropie de l'information, fondamental dans la théorie de l'information[1], ce qui lui permit d'évaluer la quantité d'information maximale qu'on pouvait transmettre dans un canal donné. Il a également montré qu'en utilisant une stratégie de codage numérique adéquat, il était possible de transmettre les informations de façon que le récepteur soit en mesure de restaurer le message original bruité sans perte d'information, sous réserve de réduire la vitesse de transmission des informations.
Initialement, il ne semble pas que Shannon ait été au courant de la relation étroite entre sa nouvelle mesure et les travaux précédents en thermodynamique. Le terme entropie a été suggéré par le mathématicien John von Neumann pour la raison que cette notion ressemblait à celle déjà connue sous le nom d'entropie en physique statistique. Il aurait ajouté que ce terme était de plus assez mal compris pour pouvoir triompher dans tout débat[2].
En 1957, Edwin Thompson Jaynes démontrera le lien formel existant entre l'entropie macroscopique introduite par Clausius en 1847, l'entropie microscopique introduite par Gibbs, et l'entropie mathématique de Shannon. Cette découverte fut qualifiée par Myron Tribus de « révolution passée inaperçue »[3].
Le calcul de l'entropie d'une source de messages donne une mesure de l'information minimale que l'on doit conserver afin de représenter ces données sans perte. En termes communs, dans le cas particulier de la compression de fichiers en informatique, l'entropie indique le nombre minimal de bits que peut atteindre un fichier compressé. En pratique, l'entropie de l'image ou du son se voit davantage abaissée en retirant des détails imperceptibles pour les humains, comme lors de la compression des sons par le format MP3, des images par JPEG ou des vidéos par MPEG.
Définition formelle
Pour une source, qui est une variable aléatoire discrète X comportant n symboles, chaque symbole xi ayant une probabilité Pi d'apparaître, l'entropie H de la source X est définie comme :
![{\displaystyle H_{b}(X)=-\mathbb {E} [\log _{b}{P(X)}]=\sum _{i=1}^{n}P_{i}\log _{b}\left({\frac {1}{P_{i}}}\right)=-\sum _{i=1}^{n}P_{i}\log _{b}P_{i}.\,\!}](https://img.franco.wiki/i/de3d4182d0534d54909afa7a8f4bd27486f2a7b2.svg)
où désigne l'espérance mathématique, et le logarithme en base b. On utilise en général un logarithme à base 2 car l'entropie possède alors les unités de bit/symbole. Les symboles représentent les réalisations possibles de la variable aléatoire X. Dans ce cas, on peut interpréter H(X) comme le nombre de questions à réponse oui/non que doit poser en moyenne le récepteur à la source, ou la quantité d'information en bits que la source doit fournir au récepteur pour que ce dernier puisse déterminer sans ambiguïté la valeur de X.



Si on dispose de deux variables aléatoires X et Y, on définit d'une façon analogue la quantité H(X,Y), appelée l'entropie conjointe, des variables X et Y :

ainsi que l'entropie conditionnelle[4] de Y relativement à X :

Justification de la formule
Dans le cas où l'on dispose d'un nombre N de symboles de la forme , avec n entier, et où les N symboles sont équiprobables, il suffit de n questions, en procédant par dichotomie, pour déterminer le symbole envoyé par la source. Dans ce cas, la quantité d'information contenue par le symbole est exactement (on doit diviser n fois par 2 l'ensemble des possibilités pour qu'il n'en reste plus qu'une). Il est naturel de conserver cette formule dans le cas où N n'est pas une puissance de 2. Par exemple, si les symboles sont les lettres de l'alphabet ainsi que le symbole espace (soit 27 symboles), l'information contenue par un symbole est , valeur intermédiaire entre 4 bits (permettant de coder 16 symboles) et 5 bits (qui permet d'en coder 32). Cette définition de l'entropie dans le cas équiprobable est comparable à celle donnée en thermodynamique par Boltzmann.



Supposons maintenant que les N symboles soient répartis en n sous-catégories, la i-ème catégorie étant constituée de Ni symboles (avec donc ). Par exemple, les 27 caractères considérés précédemment peuvent être répartis en trois catégories, les voyelles, les consonnes et le caractère espace. Soit X la variable aléatoire donnant la catégorie du symbole considéré. Posons la probabilité que le symbole considéré appartienne à la i-ème catégorie. La détermination du symbole peut être effectuée en deux temps, d'abord celui de sa catégorie X, exigeant une quantité d'information H(X), puis, au sein de sa catégorie, la détermination du symbole. Si la catégorie à laquelle appartient le symbole est la i-ème, cette dernière étape demande une quantité d'information égale à . Cette éventualité se produisant avec une probabilité Pi, la quantité moyenne d'information pour déterminer le symbole connaissant sa catégorie est . La quantité d'information totale pour déterminer le symbole est donc la somme de la quantité H(X) pour déterminer sa catégorie, et de la quantité moyenne pour déterminer le symbole au sein de sa catégorie. On a donc :







donc :

Par exemple, la quantité d'information de 4,75 bits pour déterminer un caractère parmi 27 se scinde en H(X) = 0,98 bits pour déterminer sa catégorie (voyelle, consonne, espace) auxquels s'ajoutent 3,77 bits en moyenne pour déterminer le caractère au sein de sa catégorie.
On peut vérifier a posteriori la cohérence de cette définition avec la propriété d'additivité de l'entropie. Soient deux variables aléatoires indépendantes et . On s'attend à ce que . Par exemple, si (X,Y) représente la position d'un objet dans un tableau (X étant le numéro de ligne et Y le numéro de colonne), H(X,Y) est la quantité d'information nécessaire pour déterminer cette position. C'est la somme de la quantité d'information H(X) pour déterminer son numéro de ligne et de la quantité d'information H(Y) pour déterminer son numéro de colonne. Or, la probabilité du produit cartésien de ces variables aléatoires est donnée par :




qui sera abrégé par la suite en . On a alors :

![{\begin{aligned}H(X,Y)&=-\sum _{{x\in X}}\sum _{{y\in Y}}P(x,y)\log P(x,y)\\&=-\sum _{{x\in X}}\sum _{{y\in Y}}P(x)P(y)\log \left[P(x)P(y)\right]\\&=-\sum _{{x\in X}}\sum _{{y\in Y}}P(x)P(y)\left[\log P(x)+\log P(y)\right]\\&=-\sum _{{x\in X}}\sum _{{y\in Y}}P(x)P(y)\log P(x)-\sum _{{y\in Y}}\sum _{{x\in X}}P(x)P(y)\log P(y)\\&=-\sum _{{x\in X}}P(x)\log P(x)\sum _{{y\in Y}}P(y)-\sum _{{y\in Y}}P(y)\log P(y)\sum _{{x\in X}}P(x)\\&=-\sum _{{x\in X}}P(x)\log P(x)-\sum _{{y\in Y}}P(y)\log P(y)\\&=H(X)+H(Y)\end{aligned}}](https://img.franco.wiki/i/ca9176187ac9da69624bb829d7258c1197b28c6f.svg)
comme attendu.
Exemples simples
Processus de Bernoulli
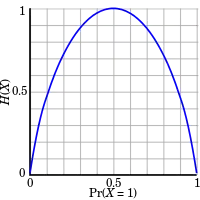
Ici, l'entropie vaut au plus 1 bit, et communiquer le résultat d'un lancer de pièce (2 valeurs possibles) demandera une moyenne d'au plus 1 bit (valeur atteinte pour un tirage équilibré). Pour un tirage de dé (6 issues possibles), on aurait une entropie de log2(6) bits.
On lance une pièce à pile ou face en connaissant les probabilités des deux résultats ; le modèle classique est celui d'un processus de Bernoulli.
L'entropie du résultat du lancer à venir est maximale pour une pièce équilibrée. Il s'agit bien du cas d'incertitude maximale car c'est là qu'il est le plus difficile de prédire l'issue du lancer ; le résultat de chaque lancer de la pièce donne un bit complet d'information. En effet

Cependant, si on sait par avance que la pièce n'est pas équilibrée, mais que pile et face ont des probabilités p et q, avec p ≠ q, alors l'incertitude est moindre. À chaque tirage, un côté est plus susceptible de sortir que l'autre. L'incertitude réduite est quantifiée dans une entropie moindre : en moyenne, chaque lancer délivre moins d'un bit d'information. Par exemple, si p = 0,7, alors

L'équiprobabilité mène à une incertitude maximale et donc une entropie maximale. L'entropie ne peut donc que décroitre en s'éloignant la valeur correspondant à l'équiprobabilité. Les cas extrêmes correspondant à des pièces double-face ou double-pile, où l'incertitude, et donc l'entropie, est nulle, et chaque tirage donne 0 bit d'information puisque le résultat est connu et certain[5]:14–15.
Tirage aléatoire dans une urne
Considérons une urne contenant une boule rouge, une boule bleue, une boule jaune et une boule verte. On tire une boule au hasard. Il s'agit de communiquer la couleur tirée. Aucun tirage n'étant privilégié, l'entropie est maximale, égale ici à log2(4) = 2. Si on convient que les couleurs sont codées respectivement 00, 01, 10, 11, l'information contenue dans le tirage correspond effectivement à 2 bits.
Mais si une certaine couleur est plus représentée que les autres, alors l'entropie est légèrement réduite. Supposons par exemple que l'urne contienne 4 boules rouges, 2 bleues, 1 jaune et 1 verte. L'entropie est alors de 7/4. En effet,
![{\displaystyle {\begin{aligned}H(x)&=-{\frac {4}{8}}\log _{2}\left({\frac {4}{8}}\right)-{\frac {2}{8}}\log _{2}\left({\frac {2}{8}}\right)-{\frac {1}{8}}\log _{2}\left({\frac {1}{8}}\right)-{\frac {1}{8}}\log _{2}\left({\frac {1}{8}}\right)\\[3pt]&=-{\frac {\log _{2}(1/2)}{2}}-{\frac {\log _{2}(1/4)}{4}}-{\frac {\log _{2}(1/8)}{8}}-{\frac {\log _{2}(1/8)}{8}}\\[3pt]&={\frac {\log _{2}(2)}{2}}+{\frac {\log _{2}(4)}{4}}+{\frac {\log _{2}(8)}{8}}+{\frac {\log _{2}(8)}{8}}\\[3pt]&={\frac {1}{2}}+{\frac {2}{4}}+{\frac {3}{8}}+{\frac {3}{8}}={\frac {7}{4}}\end{aligned}}}](https://img.franco.wiki/i/9afedbc35f68a7b83584bd4fb4116debbd037b22.svg)
Si les couleurs sont codées respectivement 0 pour le rouge, 10 pour le bleu, 110 pour le jaune et 111 pour le vert[6], alors l'information sur la couleur tirée occupe 1 bit une fois sur deux, 2 bits une fois sur quatre et 3 bits une fois sur quatre, soit en moyenne 7/4 bits, correspondant à l'entropie calculée.
Entropie d'un texte
Considérons un texte constitué d'une chaîne de lettres et d'espaces, soit 27 caractères. Si ces caractères sont équiprobables, l'entropie associée à chaque caractère est , ce qui signifie qu'il faut entre 4 et 5 bits pour transmettre un caractère. Mais si le texte est exprimé dans un langage naturel tel que le français, comme la fréquence de certains caractères n'est pas très importante (ex : 'w'), tandis que d'autres sont très communs (ex : 'e'), l'entropie de chaque caractère n'est pas si élevée. Compte tenu de la fréquence de chaque caractère, une estimation effectuée sur la langue anglaise par Shannon donne comme valeur de l'entropie environ 4,03[7].

L'entropie est en fait encore plus faible, car il existe des corrélations entre un caractère et celui, voire ceux qui le précèdent. Des expériences ont été menées afin d'estimer empiriquement cette entropie. Par exemple, A dispose du texte et demande à B de le deviner lettre par lettre (espaces comprises). Si B devine correctement la lettre, on compte 1 et si B se trompe, on compte 4,75 (correspondant à l'entropie d'un caractère équiprobable, donnée plus haut). On obtient ainsi expérimentalement une entropie de 1,93 bits par lettre[8],[9].
Enfin, la loi de Zipf (empirique)[10] amène à des considérations du même ordre, cette fois-ci pour les mots. D'après l'ouvrage de 1955 Connaissance de l'électronique[11] une lettre dans une langue donnée représente dans la pratique 1,1 bit-symbole (terminologie employée par cet ouvrage). Cette redondance explique la facilité avec laquelle on peut briser plusieurs chiffrements de complexité moyenne si on dispose de leur algorithme, même sans connaître la clé de chiffrement. C'est elle aussi qui permet de retrouver le contenu d'un texte parlé ou écrit dont une grande partie est altérée pour une raison ou une autre.
Propriétés
Voici quelques propriétés importantes de l'entropie de Shannon :
- avec égalité si et seulement s'il existe tel que
- où est une distribution de probabilité quelconque sur la variable X (Inégalité de Gibbs).












- . La quantité est l'entropie maximale, correspondant à une distribution uniforme, c’est-à-dire quand tous les états ont la même probabilité. L'entropie maximale augmente avec le nombre d'états possibles (ce qui traduit l'intuition que plus il y a de choix possibles, plus l'incertitude peut être grande). Cependant, cette augmentation de l'entropie n'est qu'une possibilité : l'entropie où beaucoup d'états sont possibles mais avec une très faible probabilité pour la plupart d'entre eux peut tout à fait être inférieure à l'entropie du pile ou face (le bit). Par exemple, s'il y a 100 états, dont l'un probable à 99 % et les autres également improbables, l'entropie est de seulement 0,14 bit.





- Elle est symétrique :
- Elle est continue
- avec égalité si et seulement si les variables sont indépendantes.







Utilité pratique
L'entropie de Shannon est utilisée pour numériser une source en utilisant le minimum possible de bits sans perte d'information. Si le canal de transmission de l'information a une capacité de C bits par seconde et si les symboles qu'envoie la source ont une entropie H, alors la vitesse maximale de transmission des symboles est de C/H symboles par seconde, cette vitesse pouvant être approchée d'aussi près que l'on veut au moyen d'un système de codage adéquat des symboles.
De plus, si du bruit brouille la transmission, la capacité C du canal de transmission diminue. En effet, des informations supplémentaires doivent être envoyées par la source afin que le récepteur puisse reconstituer le message sans erreur. Ces informations occupent une place supplémentaire qui diminuent la capacité C. Soit p la probabilité qu'un bit 0 soit modifié en 1 et inversement. Les informations supplémentaires envoyées par la source doivent permettre au récepteur de savoir si le bit envoyé est erroné (avec une probabilité p) ou s'il est correct (avec une probabilité 1 - p). La quantité d'information correspondante par bit est . La capacité de transmission devient alors . Elle est nulle si p = 1/2, cas correspondant à un message totalement brouillé.


L'entropie de Shannon permet aussi de quantifier le nombre minimum de bits sur lesquels on peut coder un fichier, mesurant ainsi les limites que peuvent espérer atteindre les algorithmes de compression sans perte comme le codage de Huffman, puis ultérieurement l'algorithme LZH. Elle est également utilisée dans d'autres domaines, par exemple la sélection du meilleur point de vue d'un objet en trois dimensions[12].
L'entropie de Shannon est utilisée également en imagerie (médicale ou spatiale) à la base de la théorie de l'information Mutuelle (Mutual Information (MI)). Elle permet notamment de recaler deux images différentes l'une sur l'autre en minimisant l'entropie des deux images. En pratique cela permet de comparer les scanners d'un patient A quelconque avec un patient de référence B. Enfin, en génétique, l'entropie de Shannon permet de repérer sur un chromosome les portions d'ADN contenant le plus d'information.
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Entropy (information theory) » (voir la liste des auteurs).
- ↑ (en) Claude E.Shannon, « A mathematical theory of communication », Bell System Technical Journal, vol. vol. 27, , p. 379-423 et 623-656 (lire en ligne)
- ↑ M. Tribus, E.C. McIrvine, “Energy and information”, Scientific American, 224 (September 1971).
- ↑ La référence est dans (en) Myron Tribus, « Some Observations on Systems, Probability, Entropy and Management »
- ↑ Didier Dacunha-Castelle, Marie Duflo, Probabilités et statistiques, t.I, Masson (1982), p.19
- 1 2 (en) Thomas M. Cover et Joy A. Thomas, Elements of Information Theory, Hoboken, New Jersey, Wiley, (ISBN 978-0-471-24195-9)
- ↑ Les codes sont tels qu'aucun d'eux n'est préfixe d'un autre, de sorte qu'une suite de tirages avec remise puisse être communiquée sans ambiguïté pour le récepteur.
- ↑ Léon Brillouin, La science et la théorie de l'information, Masson (1959), réédité par Gabay (1988), p. 23
- ↑ Léon Brillouin, La science et la théorie de l'information, Masson (1959), réédité par Gabay (1988), p. 24
- ↑ La mesure dépend de la culture du récepteur. Une phrase comme "nous obtenons la série suivante rapidement convergente" fournira un plus grand taux de réussite chez des mathématiciens que chez des non-mathématiciens. De même, explique Brillouin, si on utilise d'autres vocabulaires très spécialisés comme médical, financier, politique, etc.
- ↑ ou de sa généralisation mathématique, la loi de Mandelbrot
- ↑ Editions du Tambourinaire, 1955
- ↑ (en) P.-P. Vàzquez, M. Feixas, M. Sbert, W. Heidrich, Viewpoint selection using viewpoint entropy, Proceedings of the Vision Modeling and Visualization Conference, 273-280, 2001.
Voir aussi
Bibliographie
- Léon Brillouin, La science et la théorie de l'information, Masson (1959), réédité par Gabay (1988)
- (en) Claude E. Shannon, [PDF] A mathematical theory of communication, Bell System Technical Journal et 623-656, juillet-octobre, 1948
Articles connexes
- Complexité de Kolmogorov
- Entropie de Rényi
- Entropie métrique
- Entropie différentielle
- Loi de probabilité d'entropie maximale
- Information mutuelle
- Théorème du codage de source
- Théorie de l'information