L’informatique décisionnelle (en anglais business intelligence (BI)[1] ou decision support system (DSS)) est l'informatique à l'usage des décideurs et des dirigeants d'entreprises. Elle désigne les moyens, les outils et les méthodes qui permettent de collecter, consolider, modéliser et restituer les données, matérielles ou immatérielles, d'une entreprise en vue d'offrir une aide à la décision et de permettre à un décideur d’avoir une vue d’ensemble de l’activité traitée.
Ce type d’application repose sur une architecture commune dont les bases théoriques viennent principalement de Ralph Kimball, Bill Inmon et Dan Linstedt.
- Les données opérationnelles sont extraites périodiquement de sources hétérogènes : fichiers plats, fichiers Excel, base de données (DB2, Oracle, SQL Server, etc.), service web, données massives et stockées dans un entrepôt de données.
- Les données sont restructurées, enrichies, agrégées, reformatées, nomenclaturées pour être présentées à l'utilisateur sous une forme sémantique (vues métiers ayant du sens) qui permet aux décideurs d'interagir avec les données sans avoir à connaître leur structure de stockage physique, de schémas en étoile qui permettent de répartir les faits et mesures selon des dimensions hiérarchisées, de rapports pré-préparés paramétrables, de tableaux de bords plus synthétiques et interactifs.
- Ces données sont livrées aux divers domaines fonctionnels (direction stratégique, finance, production, comptabilité, ressources humaines, etc.) à travers un système de sécurité ou de datamart spécialisés à des fins de consultations, d'analyse, d'alertes prédéfinies, d'exploration de données, etc.
L’informatique décisionnelle s’insère dans l’architecture plus large d’un système d'information, mais n'est pas un concept concurrent du management du système d'information. Au même titre que le management relève de la sociologie et de l'économie, la gestion par l'informatique est constitutive de deux domaines radicalement différents que sont le management et l'informatique. Afin d'enrichir le concept avec ces deux modes de pensées, il est possible d'envisager un versant orienté ingénierie de l'informatique portant le nom d'informatique décisionnelle, et un autre versant servant plus particulièrement les approches de gestion appelé management du système d'information.
Définition
Le terme anglais de business intelligence (BI) peut prêter à confusion avec la notion d'intelligence économique (IE). Business intelligence ne signifie pas « intelligence économique », contrairement à ce que laisserait croire une traduction littérale (Cf. cette discussion).
La BI diffère de l'IE sur trois points :
- la BI travaille sur des informations internes à l'entreprise, alors que l'IE exploite des informations externes à l'entreprise ;
- la BI exploite des informations structurées, gérées dans des entrepôts de données, alors que l'IE se fonde sur des informations non structurées ;
- la BI fournit surtout une vision du passé alors que l'IE est tournée vers l'avenir.
Enjeux de l'informatique décisionnelle
Actuellement, les données applicatives métier sont stockées dans une (ou plusieurs) bases de données relationnelles ou non relationnelles.
Ces données sont extraites, transformées et chargées dans un entrepôt de données généralement par un outil de type ETL (Extract-Transform-Load) .
Un entrepôt de données peut prendre la forme d’un data warehouse ou d’un datamart. En règle générale, le data warehouse globalise toutes les données applicatives de l’entreprise, tandis que les datamarts (généralement alimentés depuis les données du data warehouse) sont des sous-ensembles d’informations concernant un métier particulier de l’entreprise (marketing, risque, contrôle de gestion…), des usages spécifiques (analyse, reporting...), ou encore répondent à des exigences ou contraintes particulières (cloisonnement des données, volumétrie...). Le terme comptoir de données ou magasin de données est aussi utilisé pour désigner un datamart.
Les entrepôts de données permettent de produire des rapports qui répondent à la question « Que s’est-il passé ? », mais ils peuvent être également conçus pour répondre à la question analytique « Pourquoi est-ce que cela s’est passé ? » et à la question pronostique « Que va-t-il se passer ? ». Dans un contexte opérationnel, ils répondent également à la question « Que se passe-t-il en ce moment ? », voire dans le cas d’une solution d’entrepôt de données actif « Que devrait-il se passer ? ».
Le reporting est probablement l'application la plus utilisée encore aujourd'hui de l’informatique décisionnelle, il permet aux gestionnaires :
- de sélectionner des données relatives à telle période, telle production, tel secteur de clientèle, etc.
- de trier, regrouper ou répartir ces données selon les critères de leur choix
- de réaliser divers calculs (totaux, moyennes, écarts, comparatif d'une période à l'autre…)
- de présenter les résultats d’une manière synthétique ou détaillée, le plus souvent graphique selon leurs besoins ou les attentes des dirigeants de l’entreprise
Les programmes utilisés pour le reporting permettent bien sûr de reproduire de période en période les mêmes sélections et les mêmes traitements et de faire varier certains critères pour affiner l’analyse. Mais le reporting n'est pas à proprement parler une application d'aide à la décision. L'avenir appartient plutôt aux instruments de type tableau de bord équipés de fonctions d'analyses multidimensionnelles de type Olap. Fonction OLAP qui peut être obtenue de différentes façons par exemple via une base de données relationnelle R-OLAP, ou multidimensionnelle M-OLAP, voire aussi en H-OLAP.
Les datamart et/ou les datawarehouses peuvent ainsi permettre via l'OLAP l’analyse très approfondie de l’activité de l’entreprise, grâce à des statistiques recoupant des informations relatives à des activités apparemment très différentes ou très éloignées les unes des autres, mais dont l’étude fait souvent apparaître des dysfonctionnements, des corrélations ou des possibilités d’améliorations très sensibles.
L'interopérabilité entre les systèmes d'entrepôt de données, les applications informatiques ou de gestion de contenu, et les systèmes de reporting est réalisée grâce à une gestion des métadonnées.
Du tableau à l'hypercube
L'informatique décisionnelle s'attache à mesurer :
- un certain nombre d'indicateurs ou de mesures (que l'on appelle aussi les faits)
- restitués selon les axes d'analyse, que l'on appelle usuellement les dimensions.
Tableau
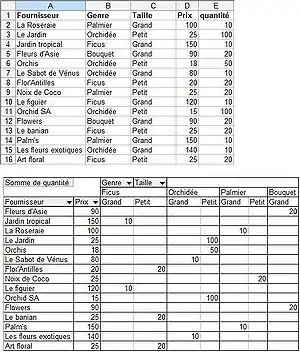
Par exemple, on peut vouloir mesurer :
- Trois faits : le chiffre d'affaires, le nombre de ventes, le montant de taxes pour les ventes de produits
- selon une première dimension, le calendrier : par année, par trimestre, par mois, par jour ;
- et selon une deuxième dimension, la hiérarchie de produits : famille de produits, gamme de produits, référence produit.
On obtient ainsi un tableau à deux entrées :
- par exemple en lignes : la nomenclature produits à 3 niveaux (famille, gamme, référence)
- et en colonnes : les années, décomposées en trimestres, décomposés en mois
- avec au croisement des lignes et colonnes, pour chaque cellule : le chiffre d'affaires, le montant de taxes et le nombre de ventes
À titre d'illustration, les tableaux croisés des principaux tableurs permettent de construire ce type de tableau de bord depuis une base de données.
Cube
Si l'on s'intéresse à une troisième dimension d'analyse, par exemple, la hiérarchie géographique des points de vente (par pays, région, magasin) on passe ainsi à un cube. Les tableaux croisés dynamiques d'Excel permettent de représenter ce type de cube avec le champ "page", qui représente les données agrégées pour chaque niveau hiérarchique et pour chaque dimension.
Hypercube
Si l'on s'intéresse à un axe d'analyse supplémentaire, par exemple la segmentation des clients (par catégorie, profession, client), on obtient alors un cube à plus de 3 dimensions, appelé hypercube. Le terme cube est souvent utilisé en lieu et place d' hypercube.
Navigation dans un hypercube
Les outils du monde décisionnel offrent des possibilités de « navigation » dans les différentes dimensions du cube ou de l'hypercube :
- le drill down ou le forage avant : c'est la possibilité de « zoomer » sur une dimension (par exemple d'éclater les années en 4 trimestres pour avoir une vision plus fine, ou de passer du pays aux différentes régions)
- le drill up ou le forage arrière (aussi appelé "roll-up") : c'est l'opération inverse qui permet d'« agréger » les composantes de l'un des axes (par exemple de regrouper les mois en trimestre, ou de totaliser les différentes régions pour avoir le total par pays)
- le slice and dice, aussi appelé "dice down" (que l'on peut traduire par « hacher menu », c'est-à-dire couper en lamelles puis en dés) : c'est une opération plus complexe qui entraîne une permutation des axes d'analyse (par exemple, on peut vouloir remplacer une vue par pays/régions par une nouvelle vue par familles et gammes de produits)
- le drill through : lorsqu'on ne dispose que de données agrégées (indicateurs totalisés), le drill through permet d'accéder au détail élémentaire des informations (chaque vente de chaque produit à chaque client dans chaque magasin)
Précautions à prendre
Chacune de ces vues partielles du cube se traduit finalement, soit par un tableau à double entrée (tri croisé), soit par un graphique le plus souvent bidimensionnel.
Ainsi, bien que la navigation dans le cube soit multidimensionnelle, le décideur n’a pas, en réalité, accès à une synthèse, mais à une multitude de tris croisés ou de vues bidimensionnelles dont l’exploration, longue et fastidieuse, est parfois court-circuitée faute de temps. Cela peut conduire à de coûteuses erreurs de décision.
Aussi peut-il être utile d’associer à cette démarche une iconographie des corrélations, qui permet une vue d’ensemble réellement multidimensionnelle, débarrassée des redondances.
Fonctions essentielles de l'informatique décisionnelle
Un système d'information décisionnel (SID) doit être capable d'assurer quatre fonctions fondamentales : la collecte, l'intégration, la diffusion et la présentation des données. À ces quatre fonctions s'ajoute une fonction d'administration, soit le contrôle du SID lui-même.
Fonction de collecte
La fonction collecte (parfois appelée datapumping) recouvre l'ensemble des tâches consistant à détecter, sélectionner, extraire et filtrer les données brutes issues des environnements pertinents compte tenu du périmètre couvert par le SID. Comme il est fréquent que les sources de données internes et/ou externes soient hétérogènes — tant sur le plan technique que sur le plan sémantique — cette fonction est la plus délicate à mettre en place dans un système décisionnel complexe. Elle s'appuie notamment sur des outils d'ETL (extract-transform-load pour extraction-transformation-chargement).
Les données sources qui alimentent le SID sont issues des systèmes transactionnels de production, le plus souvent sous forme :
- d'éléments issus de l'enregistrement de flux : compte-rendu d'événement ou compte-rendu d'opération . C'est le constat au fil du temps des opérations (achats, ventes, écritures comptables…), le film de l'activité quotidienne, en tous cas régulière, de l'entreprise
- d'éléments reflétant une situation à un moment donné : compte-rendu d'inventaire ou compte-rendu de stock. C'est l'image photo prise à un instant donné (une fin de période par exemple : mois, trimestre…) de données caractérisant un stock. Par exemple : le stock des clients, des contrats, des commandes, des encours…
La fonction de collecte joue également, au besoin, un rôle de recodage. Une donnée représentée différemment d'une source à une autre impose le choix d'une représentation unique et donc d'une mise en équivalence utile pour les futures analyses.
Fonction d'intégration
La fonction d'intégration consiste à concentrer les données collectées dans un espace unifié, dont le socle informatique essentiel est l'entrepôt de données. Élément central du dispositif, il permet aux applications décisionnelles de masquer la diversité de l'origine des données et de bénéficier d'une source d'information commune, homogène, normalisée et fiable, au sein d'un système unique et si possible normalisé.
Au passage les données sont épurées ou transformées par :
- un filtrage et une validation des données en vue du maintien de la cohérence d'ensemble : les valeurs acceptées par les filtres de la fonction de collecte mais susceptibles d'introduire des incohérences de référentiel par rapport aux autres données doivent être soit rejetées, soit intégrées avec un statut spécial
- une synchronisation : s'il y a nécessité d'intégrer en même temps ou à la même « date de valeur » des événements reçus ou constatés de manière décalée ou déphasée
- une certification : pour rapprocher les données de l'entrepôt des autres systèmes « légaux » de l'entreprise comme la comptabilité ou les déclarations réglementaires)
C'est également dans cette fonction que sont effectuées éventuellement les calculs et les agrégations (cumuls) communs à l'ensemble du projet.
La fonction d'intégration est généralement assurée par la gestion de métadonnées, qui assurent l'interopérabilité entre toutes les ressources informatiques, qu'il s'agisse de données structurées (bases de données accédées par des progiciels ou applications), ou des données non structurées (documents et autres ressources non structurées, manipulés par les systèmes de gestion de contenu).
Fonction de diffusion (ou distribution)
La fonction de diffusion met les données à la disposition des utilisateurs, selon des schémas correspondant aux profils ou aux métiers de chacun, sachant que l'accès direct à l'entrepôt de données ne correspond généralement pas aux besoins spécifiques d'un décideur ou d'un analyste. L'objectif prioritaire est à ce titre de segmenter les données en contextes informationnels fortement cohérents, simples à utiliser et correspondant à une activité décisionnelle particulière. Alors qu'un entrepôt de données peut héberger des centaines ou des milliers de variables ou indicateurs, un contexte de diffusion raisonnable n'en présente que quelques dizaines au maximum. Chaque contexte peut correspondre à un datamart, bien qu'il n'y ait pas de règles générales concernant le stockage physique. Très souvent, un contexte de diffusion est multidimensionnel, c'est-à-dire modélisable sous la forme d'un hypercube; il peut alors être mis à disposition à l'aide d'un outil OLAP.
Les différents contextes d'un même système décisionnel n'ont pas tous besoin du même niveau de détail. De nombreux agrégats ou cumuls, n'intéressent que certaines applications et n'ont donc pas lieu d'être gérés en tant qu'agrégats communs par la fonction d'intégration : La gestion de ce type de spécificité peut être prise en charge par la fonction de diffusion. Ces agrégats pouvant au choix, être stockés de manière persistante ou calculés dynamiquement à la demande.
À ce stade et lorsqu'il s'agit de concevoir un système de reporting, trois niveaux de questionnement doivent être soulevés :
- À qui s'adresse le rapport spécialisé ? : choix des indicateurs à présenter, choix de la mise en page
- Par quel trajet ? : circuit de diffusion type « workflow » pour les personnes ou circuits de transmission « télécoms » pour les moyens
- Selon quel agenda ? : diffusion routinière ou déclenchée sur événement prédéfini
Fonction présentation
Cette quatrième fonction, la plus visible pour l'utilisateur, régit les conditions d'accès de l'utilisateur aux informations, dans le cadre d'une interface Homme-machine déterminé (IHM). Elle assure le contrôle d'accès et le fonctionnement du poste de travail, la prise en charge des requêtes, la visualisation des résultats sous une forme ou une autre. Elle utilise toutes les techniques de communication possibles : outils bureautiques, requêteurs et générateurs d'états spécialisés, infrastructure web, télécommunications mobiles, etc.
Fonction administration
C'est la fonction transversale qui supervise la bonne exécution de toutes les autres. Elle pilote le processus de mise à jour des données, la documentation sur les données (les méta-données), la sécurité, les sauvegardes, et la gestion des incidents.
Projet décisionnel
Dans une entreprise, le volume de données traitées croît rapidement avec le temps. Ces données peuvent provenir des fournisseurs, des clients, de l’environnement, etc. Cette quantité de données augmente en fonction du secteur et de l'activité de l’entreprise. Par exemple, dans la grande distribution, les quantités de données collectées chaque jour sont énormes (notamment lorsque les magasins collectent les tickets des caisses).
L'entreprise dispose de plusieurs options pour traiter ce flux de données :
- les données anciennes sont effacées et l'entreprise ne conserve que les données actives ou un historique récent
- les données sont stockées dans une base et l'entreprise n'envisage pas d'usage immédiat
- les données sont stockées au fur et à mesure qu’elles arrivent de manière cohérente pour qu’elles soient exploitables directement
Le projet décisionnel correspond à cette dernière option. Il s’agit de traiter les données et de les stocker de manière cohérente au fur et à mesure qu’elles se présentent. C’est pour cela que le projet décisionnel est un projet sans limite dans le temps. C'est-à-dire que dès que l’entreprise commence ce projet, elle ne s’arrête pas (sauf cas exceptionnel). Wal-Mart (une chaîne de la grande distribution) est l’une des entreprises qui stockent le plus de données (elle a multiplié par 100 ses données en quelques années) et va atteindre dans les années à venir le pétaoctet (1 000 téraoctets).
Pour mener à bien ces projets décisionnels, il existe une multitude d'outils, chacun étant plus ou moins adapté à la taille de l'entreprise, à la structure des données existantes et au type d'analyse désiré.
Rappel de la chaîne de la valeur décisionnelle
- Des SGBD relationnels et d'autres systèmes qui contiennent les données d'exploitation.
- Un ETL extrait les données pertinentes et les charge dans l'ODS du datawarehouse
- Les données sont structurées dans le datawarehouse [2]
- Des datamarts qui exploitent une technologie X-OLAP sont mis à jour à partir du datawarehouse
- Des rapports sont générés sur ces données
Phase de recueil des exigences
Trois domaines doivent être particulièrement documentés :
- le type d'information dont l'utilisateur des rapports a besoin
- le type de restitution (ergonomie, fréquence, vitesse de restitution)
- le système technique existant : technologies utilisées
Phase de conception et de choix technique
- En fonction des exigences recueillies, quels sont les éléments de la chaîne de la valeur décisionnelle qui doivent être implémentés ?
- Doit-on seulement créer un rapport sur un cube OLAP existant ?
- Construire toute la chaîne ?
- Quelles sont précisément les données que l'on doit manipuler ?
Cela conduit au choix de technologies précises et à un modèle particulier.
Acteurs open source
La quasi-totalité des domaines de l'informatique décisionnelle du monde propriétaire sont aussi couverts par l'OSBI.
L'OSBI, dont les codes logiciels sont en partie publics, n'a rien à voir avec l'open source intelligence (OSINT) qui désigne la recherche dans les sources publiques, c'est-à-dire les journaux, annuaires…
Bases de données
Le monde du logiciel libre propose des alternatives face aux systèmes de bases de données propriétaires Oracle ou Microsoft SQL Server. Les solutions les plus réputées sont :
ETL
Les ETL (extract-transform-load) sont les outils pour manipuler les données, comme pour la construction et l'alimentation des datawarehouse (entrepôts de données).
Les ETL open source permettent d'effectuer un grand nombre de traitements pour l'extraction (« E »), la transformation (« T ») et le chargement (loading, « L ») de données, ceci depuis ou vers un grand nombre de systèmes :
| Etapes | Description |
|---|---|
| Étape 1 : Extraction |
|
| Étape 2 : Transformation |
|
| Étape 3 : Chargement |
|
Il existe plusieurs ETL open source, avec des versions de base entièrement libres (gratuites) et des versions professionnelles (payantes). Ces dernières sont dotées de fonctionnalités avancées et permettant d'obtenir un support direct auprès de l'éditeur.
Les ETL open source les plus complets et reconnus sont les suivants :
| Open source complets et reconnus | Description |
|---|---|
| Talend Open Studio | Talend Open Studio (TOS) est édité par la société Talend. Talend est un ETL dont l'interface graphique s'appuie sur Eclipse RCP et est de type « générateur de code » : un code spécifique est généré (et visible) pour chaque traitement d'intégration de données. Talend Integration Suite (TIS) désigne la version professionnelle, dont l'essentiel des fonctionnalités supplémentaires a pour but de fournir des fonctionnalités avancées d'entreprise : développement collaboratif, gestion des déploiements, console d'administration et de planification des jobs en production. |
| Pentaho (Pentaho) Data Integration (PDI) | également connu sous le nom de « Kettle » : PDI est un ETL qui présente à peu de chose près les mêmes fonctionnalités que Talend, la différence principale étant son interface basée sur Java SWT et son mécanisme de « méta moteur ». PDI embarque en effet la totalité du code nécessaire dans son noyau et ne traite ainsi que les flux de données. Ainsi, un traitement Kettle peut être stocké sous forme de fichier plat (XML) ou bien dans un SGBD (« Kettle repository »), ce dernier servant également de référentiel de travail partagé. Un des attraits de PDI est son niveau d'intégration avec la plateforme OSBI Pentaho : Kettle peut ainsi servir de source de données au moteur de reporting de Pentaho et même permettre l'élaboration de vues d'analyses multidimensionnelles avec le concept « Agile BI » et l'outil Pentaho Analyzer |
| CloverETL (en) | CloverETL est édité par la société Javlin |
| Streamsets | |
| MentDB Weak[3] | C'est une solution ETL open-source édité par la société Innov-AI. Le serveur est basé sur une couche de type Service Oriented Architecture (SOA) et permet avec un langage de programmation compressé (le MQL) d'effectuer des tâches ETL pour transférer des données d'un logiciel à un autre. Il possède aussi un générateur de code pouvant accélérer les développements ainsi que 26 modules de connexions standards prêt à l'usage (FTP, SSH, SFTP, Excel, CSV, JSON, XML, SQL ...). C'est un outil pensé pour du développement collaboratif, le déclenchement de jobs dans le temps et intègre quelques algorithmes de machine learning. |
Outils de reporting et d'analyse multidimensionnelle
- Jasper (iReport), Eclipse Birt (Actuate) et JFreeReport / JFreeChart
- Mondrian et Palo (OLAP database)
SGBD relationnels d'analyse
- InfiniDB et Infobright
Plateformes OSBI WEB
- JasperServer, Pentaho, SpagoBI et Vanilla
Outils d'exploration et d'analyse de données statistiques
Progiciel de gestion intégré (ERP) et de la relation client (CRM)
- Odoo, Axelor et SugarCRM
Acteurs propriétaires
- Access avec Access Insight
- Anaplan, planification financière
- Applied Olap Dodeca [5]
- BiX Software - Solution sur cubes OLAP (MS, ORACLE, IBM, SAP, SAS...) de Reporting et d'Analyse de Données.
- Information Builders (en)
- BearingPoint (HyperCube)
- BiBOARD - Reporting transactionnel qui est en redressement judiciaire depuis le 11/06/2017 [6]
- Bittle - Reporting online et tableaux de bord
- BIME [7]
- BI Square Software (Business Intelligence pour l'IT)
- BOARD [8]
- BrightAnalytics [9]
- Business Objects (SAP) [10] et son nouveau nom SAP BI4
- IMS Health avec le logiciel Reportive
- Coheris Liberty
- Comarch Business Intelligence
- CORICO, logiciel d'iconographie des corrélations
- DATAROCKS avec PROMPTO
- DigDash (Logiciel DigDash Enterprise, logiciel de tableaux de bord full web et mobile)
- Dimensional Insight
- Domo
- Hurence - ETL natif Hadoop et solutions BI basées sur Hadoop, HBase et Pig
- IcCube (en)
- IBM :
- Cognos
- TM1 [11]
- SPSS
- Jedox (en)
- Informatica
- Inside Reporting
- Microsoft
- Power BI[12]
- Excel, PowerPivot et Power View (ce dernier en cours d'abandon)
- SQL Server Reporting Services
- SQL Server Analysis Services
- MicroStrategy
- MyReport
- MyDataViz
- OpenText - ETL OTIC de son ancien nom Génio
- Oracle Corporation avec :
- Oracle Business Intelligence Enterprise Edition (OBIEE) [13]
- Hyperion (ex Brio)
- Sage BI Reporting
- Serenytics
- Tableau Software avec des outils comme Tableau Desktop
- Talend
- Tagetik
- Teradata
- SAS et son outil de Data Visualisation SAS Visual Analytics
- Qlik avec les logiciels QlikView[14] et Qlik Sense
- R2C SYSTEM - MyDataBall (Logiciel de Business Optimisation)
- SYMTRAX avec le logiciel StarQuery
- Weenove
- World Programming (en)
Notes et références
- ↑ « Qu’est-ce que la Business Intelligence (BI) ? »
- ↑ Méthodologie d'un projet Data Warehouse
- ↑ « Innov-AI | Smart-Earth and Strong AI », sur www.mentdb.org (consulté le )
- ↑ « Sipina Research -- Classification Trees Software », sur univ-lyon2.fr (consulté le ).
- ↑ description de Dodeca spreedsheat Management System
- ↑ Redressement Judiciaire BI BOARD http://www.procedurecollective.fr/fr/redressement-judiciaire/1322625/biboard.aspx
- ↑ description de BIME
- ↑ description de Board
- ↑ description de BrightAnalytics
- ↑ La suite BusinessObjects
- ↑
- ↑
- ↑ description d'OBIEE
- ↑ description de qlikView
- Cet article est partiellement ou en totalité issu de l'article intitulé « Informatique décisionnelle open source » (voir la liste des auteurs).
Voir aussi
Articles connexes
- Aide à la décision
- Business analytics
- Analyse décisionnelle des systèmes complexes
- Base de données : IBM , Oracle, Teradata
- Magasin de données
- Modèle de données dit « en étoile »
- Exploration de données
- Entrepôt de données
- Gestion de réseaux (informatique)
- Group Decision Support System
- Informatique décisionnelle open source
- Management du système d'information
- Métadonnée
- Recherche opérationnelle
- Table de décision
- Traitement analytique en ligne
Bibliographie
- Alphonse Carlier, Business Intelligence et Management, Afnor Éditions, 2013, (ISBN 978-2-12-465429-1)
- (en) Lawrence Corr et Jim Stagnitto, Agile Data Warehouse Design : Collaborative Dimensional Modeling, from Whiteboard to Star Schema, DecisionOne Press, , 328 p. (ISBN 978-0-9568172-0-4).

- Jean-Marie Gouarné, Le Projet décisionnel - Enjeux, Modèles, Architectures du Data Warehouse, Eyrolles, 1997, (ISBN 978-2-212-05012-7)
- Alain Garnier, L'Information non structurée dans l'entreprise - Usages et Outils, Hermes - Lavoisier, 2007, (ISBN 978-2-7462-1605-1)
- R. Kimball, L. Reeves, M. Ross, W. Thornthwaite, Le Data Warehouse : Guide de conduite de projet, Eyrolles, 2005, (ISBN 978-2-212-11600-7)
- Alain Fernandez, Les Nouveaux Tableaux de bord des managers, Le Projet Business Intelligence clés en main, Eyrolles, 6e édition, 2013. (ISBN 978-2-212-55647-6) présentation éditeur
- Roland et Patrick Mosimann, Meg Dussault, The Performance Manager Faire de la performance le quotidien de chacun, Cognos Press, 2007, (ISBN 978-0-9730124-4-6)
- James Taylor, Decision Management System, IBM Press, Pearson Education