| Distribution normale multidimensionnelle | |
| Paramètres | moyenne (vecteur réel) matrice de variance-covariance (matrice définie positive réelle ) |
|---|---|
| Support | |
| Densité de probabilité | |
| Espérance | |
| Médiane | |
| Mode | |
| Variance | |
| Asymétrie | 0 |
| Entropie | |
| Fonction génératrice des moments | |
| Fonction caractéristique | |
![{\displaystyle \mu =[\mu _{1},\dots ,\mu _{N}]^{\top }}](https://img.franco.wiki/i/15b940298beb52cb4a4a80495ca0c3919a94e018.svg)








En théorie des probabilités, on appelle loi normale multidimensionnelle, ou normale multivariée ou loi multinormale ou loi de Gauss à plusieurs variables, la loi de probabilité qui est la généralisation multidimensionnelle de la loi normale.
Idée générale
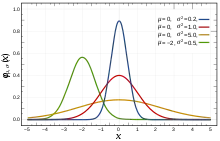
Une loi normale classique est une loi dite « en cloche » en une dimension. Comme le montre la figure, la densité en forme de cloche peut être translatée n'importe où ; l'abscisse où se trouve le pic est la moyenne, aussi appelée centre, ou espérance. Si on fait plusieurs tirages selon une loi normale, on obtient plusieurs nombres réels et la moyenne des valeurs obtenues se situent près du centre. La largeur de la cloche se mesure par la variance. Plus la variance est petite, plus la cloche est resserrée, plus les valeurs tirées auront tendance à être proche de la moyenne. À l'inverse, plus la variance est grande, plus la cloche est large et les valeurs seront plus éparpillées autour de la moyenne. Pour le cas normal, la seule valeur de la variance suffit à caractériser la « largeur » de la cloche.
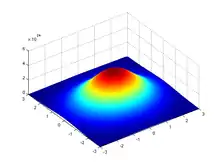
Une loi normale multidimensionnelle reprend le même principe que la loi normale classique mais en plusieurs dimensions, par exemple en deux dimensions. Si on fait des tirages selon une loi normale multidimensionnelle, on obtient des points. On parle de vecteur aléatoire. La deuxième figure montre la densité en forme de cloche en 2D. De la même manière, le point dans le plan où se trouve le pic est la moyenne, centre ou espérance. L'espérance est un point : la figure montre une loi gaussienne de moyenne (50, 50).
De la même façon, la cloche peut être plus ou moins large. Comme il y a plusieurs dimensions, la cloche peut être large pour une dimension et étroite pour une autre. Deux coordonnées peuvent aussi être corrélées : par exemple, il peut arriver que si on tire un point et que sa première coordonnée est positive, il y a plus de chances que la deuxième coordonnée soit aussi positive. Ainsi, comme on est dans le cas de vecteurs gaussiens, on modélise la forme de la cloche avec la matrice de variance-covariance.
Définition
Alors que la loi normale classique est paramétrée par un scalaire μ correspondant à sa moyenne et un second scalaire σ2 correspondant à sa variance, la loi multinormale est paramétrée par un vecteur représentant son centre et une matrice semi-définie positive qui est sa matrice de variance-covariance. On la définit par sa fonction caractéristique, pour un vecteur ,




Dans le cas non dégénéré où Σ est définie positive, donc inversible, la loi normale multidimensionnelle admet la densité de probabilité suivante :
![{\displaystyle f_{{\boldsymbol {\mu }},{\boldsymbol {\Sigma }}}\left({\boldsymbol {x}}\right)={\frac {1}{(2\pi )^{N/2}\det \!\left({\boldsymbol {\Sigma }}\right)^{1/2}}}\;\exp \left[-{\frac {1}{2}}\left({\boldsymbol {x}}-{\boldsymbol {\mu }}\right)^{\top }{\boldsymbol {\Sigma }}^{-1}\left({\boldsymbol {x}}-{\boldsymbol {\mu }}\right)\right]}](https://img.franco.wiki/i/a00ac4c7cf80bfcf181878f81d79e8c5fb2734a8.svg)
Cette loi est habituellement notée par analogie avec la loi normale unidimensionnelle.

Loi non dégénérée
Cette section s'intéresse à la construction de la loi normale multidimensionnelle dans le cas non dégénéré où la matrice de variance-covariance Σ est définie positive.
Rappel sur la loi normale unidimensionnelle
Le théorème central limite fait apparaître une variable U de Gauss centrée réduite (moyenne nulle, variance unité) :
![{\displaystyle \mathbb {E} [U]=0\qquad \mathbb {E} [U^{2}]=1}](https://img.franco.wiki/i/5fb1f4410d92234783969f6c5ae42e33479fbb8d.svg)

On passe à la variable de Gauss générale par le changement de variable

qui conduit à
![{\displaystyle \mathbb {E} [X]=\mu \qquad \mathbb {E} [(X-\mu )^{2}]=\sigma ^{2}}](https://img.franco.wiki/i/96f1e17fe893221c11380a32e96c1b1d172df777.svg)

La densité de cette loi est caractérisée par une exponentielle comportant un exposant du second degré.
Loi unitaire à plusieurs variables
Étant données N variables aléatoires indépendantes de même loi de Gauss centrée réduite, leur densité de probabilité jointe s'écrit :

C'est la loi qui est à la base de la loi du χ².
Elle peut être synthétisée dans des formules matricielles. On définit d'abord le vecteur aléatoire U qui a pour composantes les N variables et le vecteur d'état u qui a pour composantes leurs valeurs numériques.
On peut associer au vecteur d'état le vecteur moyenne qui a pour composantes les moyennes des composantes, c'est-à-dire, dans ce cas, le vecteur nul :
![{\displaystyle \mathbb {E} [{\boldsymbol {U}}]={\boldsymbol {0}}\,}](https://img.franco.wiki/i/6b7be3adbe688e83a1421cd51aa54b70075a2c08.svg)
La matrice de covariance possède des éléments diagonaux (les variances) qui sont égaux à 1 tandis que les éléments non diagonaux (les covariances au sens strict) sont nuls : c'est la matrice unité. Elle peut s'écrire en utilisant la transposition :
![{\displaystyle \mathbb {E} [{\boldsymbol {U}}{\boldsymbol {U}}^{\top }]={\boldsymbol {I}}\,}](https://img.franco.wiki/i/a0e8768a00cf2a09d7ee3eee487f5a2d135d8202.svg)
Enfin, la densité de probabilité s'écrit :

Loi générale à plusieurs variables
Elle s'obtient à partir d'un changement de variable affine

Le problème sera limité au cas d'une matrice a carrée (même nombre de variables en sortie) et régulière. L'opérateur espérance vectoriel étant linéaire, on obtient le vecteur moyen
![{\displaystyle \mathbb {E} [{\boldsymbol {X}}]={\boldsymbol {a}}\mathbb {E} [{\boldsymbol {U}}]+{\boldsymbol {\mu }}={\boldsymbol {\mu }}\,}](https://img.franco.wiki/i/11e569c8b0f6786b6b10adf2121f55e189452ac0.svg)
et la matrice de covariance
![{\displaystyle \mathbb {E} [{\boldsymbol {(X-\mu )}}{\boldsymbol {(X-\mu )}}^{\top }]=\mathbb {E} [{\boldsymbol {a}}{\boldsymbol {U}}{\boldsymbol {U}}^{\top }{\boldsymbol {a}}^{\top }]={\boldsymbol {a}}{\boldsymbol {a}}^{\top }={\boldsymbol {\Sigma }}\,}](https://img.franco.wiki/i/eb24555fba4dd8d062b22f85d87dd5781d2c0ec4.svg)
La densité de probabilité s'écrit

Remarques diverses
- Un nouveau changement de variables linéaire appliqué à X aboutit à une densité de probabilité qui a la même forme mathématique :

- Les formules essentielles, obtenues commodément à partir du calcul matriciel, se traduisent en termes scalaires :


les tjk étant les coefficients de l'inverse de la matrice de covariance.
- L'exposant dans la formule qui précède est du second degré par rapport à toutes les variables. On vérifie qu'une intégration par rapport à l'une d'entre elles donne un résultat analogue. Les (N-1) intégrations successives aboutissent à une loi de probabilité marginale munie d'un exposant quadratique : chaque variable est gaussienne, ce qui n'était pas évident a priori.
- En combinant les remarques précédentes, on aboutit au résultat selon lequel toute combinaison linéaire des composantes d'un vecteur gaussien est une variable gaussienne.
- Dans cette loi de probabilité jointe, à tout couple de variables décorrélées correspond une matrice de covariance diagonale, ce qui assure leur indépendance. En effet, le couple est lui-même gaussien, et sa densité jointe est le produit des densités de ses deux composantes.
- Le terme présent dans l'exponentielle est le carré de la distance de Mahalanobis.

Distributions conditionnelles
Si , et sont partitionnées comme décrit ci-dessous

- avec les dimensions où



- avec les dimensions


et

alors la distribution de conditionnellement à est une loi normale multidimensionnelle où




et la matrice de variance-covariance s'écrit

Cette matrice est le complément de Schur de dans .


On remarquera que savoir que vaut a change la variance de et que, de manière tout aussi surprenante, la moyenne est aussi modifiée. Cela est à comparer avec la situation dans laquelle on ne connaît pas a, auquel cas a pour distribution . Cela résulte de la condition qui n'a rien d'anodine !



La matrice est appelée matrice des coefficients de régression.

Propriétés
- Les iso-contours d'une loi normale multidimensionnelle non singulière sont des ellipsoïdes centrés sur la moyenne μ. Les directions des axes principaux de ces ellipsoïdes sont les vecteurs propres de Σ. Les carrés des longueurs relatives de ces axes sont donnés par les valeurs propres associées à ces vecteurs propres.
- L'entropie différentielle de la loi normale multidimensionnelle est donnée par[1]



- La divergence de Kullback-Leibler prend une forme particulière dans le cas de deux lois normales multidimensionnelles et



- La notion de fonction cumulative Φ (ou fonction de répartition) de la loi normale en dimension 1 peut se généraliser à la loi normale multidimensionnelle[2]. Pour ce faire, le principe clé est la distance de Mahalanobis : la fonction cumulative est la probabilité que la variable aléatoire normale tombe dans l'ellipse déterminée par sa distance de Mahalanobis r au Gaussien. Des formules analytiques existent pour calculer les valeurs de la fonction cumulative[2].

Simulation
Pour simuler une loi multinormale dont les paramètres sont connus ou estimés, soit et , on cherche à générer un échantillon artificiel de vecteurs indépendants de .




Si C n’est pas diagonale, il n’est pas envisageable de produire successivement les n variables Xi, car cette méthode ne respecterait pas les covariances.
L'approche consiste plutôt à exprimer le vecteur X comme une combinaison linéaire de variables scalaires indépendantes entre elles de la forme


où B est une matrice carrée satisfaisant la contrainte

Une propriété de la covariance montre en effet que cette contrainte assure le respect de la covariance de X.
Après avoir déterminé B, il suffit de générer des simulations des Yi pour obtenir (à l’aide de la relation ci-dessus) des versions indépendantes du vecteur X.
Il y a plusieurs possibilités pour le choix de B :
- Si la loi multinormale est non dégénérée, la factorisation de Cholesky de C (alors inversible) permet de déterminer une matrice triangulaire inférieure B satisfaisant précisément la contrainte précédente.
- Dans le cas général, C est semi-définie positive et le procédé de diagonalisation permet de caractériser
- où O est une matrice orthogonale dont les colonnes sont des vecteurs propres de C, et D est une matrice diagonale constituée des valeurs propres de C, toutes positives ou nulles. Il suffit alors de choisir
- .


Remarques :
- Bien que ces approches soient équivalentes en théorie, la seconde est numériquement préférable car elle présente une meilleure stabilité lorsque la condition de la matrice de covariance est « mauvaise ».
- Le plus souvent, un générateur de nombres pseudo-aléatoires produit en boucle les valeurs d’une série limitée (on retrouve les mêmes résultats après avoir atteint la fin de la série). Attention à cet aspect lorsqu’il s’agit de générer un grand nombre de simulations d’un vecteur multinormal de taille n élevée : l’indépendance ne sera plus assurée après épuisement de la série.
Applications
La loi normale multidimensionnelle est notamment utilisée dans le traitement d'images médicales. Ainsi elle est par exemple fréquemment utilisée dans l'imagerie du tenseur de diffusion. Cette imagerie modélise en effet la distribution des principales directions de diffusion de l'eau par une loi normale multidimensionnelle de moyenne nulle. Ainsi le tenseur en chaque point de l'image n'est autre que la matrice de covariance de la loi normale multidimensionnelle.
Une seconde application de la loi normale multidimensionnelle est la détermination, à partir des intensités dans des IRM du cerveau d'un patient, des différentes classes de tissus (matière grise, matière blanche, liquide céphalo-rachidien) qui le composent. Cette technique est basée sur l'utilisation d'un algorithme espérance-maximisation dans lequel chacune des classes est modélisée par une loi normale multidimensionnelle dont la dimension est égale aux nombre de modalités utilisées pour la classification.
Notes et références
- ↑ (en) DV Gokhale, NA Ahmed, BC Res, NJ Piscataway, « Entropy Expressions and Their Estimators for Multivariate Distributions », IEEE Transactions on Information Theory, vol. 35, no 3, , p. 688–692
- 1 2 Voir par exemple (en) Michael Bensimhoun, « N-Dimensional Cumulative Function, And Other Useful Facts About Gaussians and Normal Densities » [PDF],
Articles connexes
- Loi normale
- Loi de probabilité à plusieurs variables
- Algorithme espérance-maximisation: contenant le détail de l'application à la classification tissulaire