La théorie des probabilités en mathématiques est l'étude des phénomènes caractérisés par le hasard et l'incertitude. Elle forme avec la statistique les deux sciences du hasard qui sont partie intégrante des mathématiques. Les débuts de l'étude des probabilités correspondent aux premières observations du hasard dans les jeux ou dans les phénomènes climatiques par exemple.
Bien que le calcul de probabilités sur des questions liées au hasard existe depuis longtemps, la formalisation mathématique n'est que récente. Elle date du début du XXe siècle avec l'axiomatique de Kolmogorov. Des objets tels que les événements, les mesures de probabilité, les espaces probabilisés ou les variables aléatoires sont centraux dans la théorie. Ils permettent de traduire de manière abstraite les comportements ou des quantités mesurées qui peuvent être supposés aléatoires. En fonction du nombre de valeurs possibles pour le phénomène aléatoire étudié, la théorie des probabilités est dite discrète ou continue. Dans le cas discret, c'est-à-dire pour un nombre au plus dénombrable d'états possibles, la théorie des probabilités se rapproche de la théorie du dénombrement ; alors que dans le cas continu, la théorie de l'intégration et la théorie de la mesure donnent les outils nécessaires.
Les objets et résultats probabilistes sont un support nécessaire à la statistique, c'est le cas par exemple du théorème de Bayes, de l'évaluation des quantiles ou du théorème central limite et de la loi normale. Cette modélisation du hasard permet également de résoudre plusieurs paradoxes probabilistes.
Qu'il soit discret ou continu, le calcul stochastique est l'étude des phénomènes aléatoires qui dépendent du temps. La notion d'intégrale stochastique et d'équation différentielle stochastique font partie de cette branche de la théorie des probabilités. Ces processus aléatoires permettent de faire des liens avec plusieurs domaines plus appliqués tels que les mathématiques financières, la mécanique statistique, le traitement d'images, etc.
Historique
Avant que l'étude des probabilités soit considérée comme une science, l'observation du hasard dans les événements naturels a amené les philosophes et les scientifiques à réfléchir sur la notion de liens entre événements, causes et conséquences, et lois de la nature[1]. Les jeux de hasard, les situations météorologiques ou les trajectoires des astres ont fait partie des domaines étudiés[2]. Les explications données sont alors liées au destin, à une colère céleste ou à une présence divine[2].
Il est communément admis que le début de la science des probabilités se situe au XVIe siècle avec l'analyse de jeux de hasard par Jérôme Cardan et au XVIIe siècle avec les discussions entre Pierre de Fermat et Blaise Pascal au sujet du problème des partis posé par Antoine Gombaud, chevalier de Méré[3] : comment partager les gains quand la partie est interrompue à un moment quelconque. Cette nouvelle théorie est nommée géométrie aléatoire par le chevalier de Méré en 1654, elle est appelée par la suite calcul conjectural, arithmétique politique et plus communément aujourd'hui théorie des probabilités[3]. Cette théorie, dite des probabilités modernes, est alors étudiée par de nombreux penseurs jusqu'au XIXe siècle : Kepler, Galilée, Leibniz, Huygens, Halley, Buffon, les frères Bernoulli, Moivre, Euler, D'Alembert, Condorcet, Laplace, Fourier[4],[5]. Elle est principalement basée sur les événements discrets et la combinatoire.
Au début du XXe siècle, Kolmogorov fit la connexion entre la théorie de la mesure de Borel, la théorie de l'intégration de Lebesgue et les probabilités[5].
Des considérations analytiques ont forcé l'introduction de variables aléatoires continues dans la théorie. Cette idée prend tout son essor dans la théorie moderne des probabilités, dont les fondations ont été posées par Andreï Nikolaevich Kolmogorov. Kolmogorov combina la notion d'univers, introduite par Richard von Mises et la théorie de la mesure pour présenter son système d'axiomes pour la théorie des probabilités en 1933. Très vite, son approche devint la base incontestée des probabilités modernes.
Le XXe siècle voit également le développement de l'application de la théorie des probabilités dans plusieurs sciences.
Avec la mécanique newtonienne, la théorie du champ électromagnétique ou la thermodynamique, la physique classique est la théorie utilisée jusqu'à la fin du XIXe siècle. En 1929, Erwin Schrödinger étudie l'équation qui détermine l'évolution d'une onde au cours du temps : l'équation de Schrödinger. Max Born utilise cette équation pour décrire une collision entre des particules telles que des électrons ou des atomes. Les observations de ses expériences l'amène à supposer que la fonction d'onde est la probabilité que la particule soit détectée en un point de l'espace. C'est le début d'une nouvelle approche de la physique quantique[6].
En 1900, Louis Bachelier fut un des premiers mathématiciens à modéliser les variations de prix boursiers grâce à des variables aléatoires[a 1]. « le marché n'obéit qu'à une seule loi : la loi du hasard ». Bachelier utilise alors le calcul stochastique pour étudier les variations boursières au cours du temps. En 1970, Fischer Black et Myron Scholes reprennent les idées de Bachelier pour modéliser les rendements d'une action grâce à leur modèle Black-Scholes[a 1].
L'utilisation des probabilités en biologie a pris un essor dans les années 1970[7], notamment dans l'étude de l'évolution des espèces. La reproduction des individus est modélisée par un choix aléatoire des gènes transmis ainsi que des mutations apparaissant de manière aléatoire sur les individus. L'extinction des espèces ou des gènes est alors étudiée en fonction des effets stochastiques.
Définition
Suivant les époques ou les domaines d'application, la théorie des probabilités peut prendre des noms différents : la théorie de la probabilité mathématique[8], le calcul des probabilités[9], ou plus simplement les probabilités bien qu'il ne faille pas confondre avec une probabilité qui est une loi (ou mesure) de probabilité ou la probabilité d'un événement qui est l'évaluation de son caractère probable. Pour ce dernier terme, voir les différentes approches d'une probabilité.
La théorie des probabilités a évolué au cours de son existence. Dans son cours vers 1893, Henri Poincaré s'exprime ainsi : « On ne peut guère donner de définition satisfaisante de la Probabilité. On dit généralement ... etc. »[a 2]. Cependant, il est toujours fait mention de l'étude de notions comme le hasard, l'aléa, la chance ou encore le caractère probable d'un événement. Une définition peut être donnée sous la forme :
- La théorie des probabilités est l'étude mathématique des phénomènes caractérisés par le hasard et l'incertitude[a 3].
C'est-à-dire que la théorie des probabilités est un domaine des mathématiques. Ce n'a pas toujours été le cas, cette théorie a été rattachée à la théorie des jeux de hasard[a 4], à la philosophie[10], les géomètres ont été parmi les premiers scientifiques à utiliser le calcul des probabilités[11]. Il est à noter que le groupe mathématique Bourbaki, créé en 1930 et dont le but est de proposer une présentation cohérente des mathématiques, a été critiqué pour ne pas avoir pris suffisamment en considération la théorie des probabilités : « Bourbaki s'est écarté des probabilités, les a rejetées, les a considérées comme non rigoureuses et, par son influence considérable, a dirigé la jeunesse hors du sentier des probabilités. » soulignait Laurent Schwartz dans son autobiographie[a 5].
Axiomatique

Pour pleinement appartenir aux mathématiques, la théorie des probabilités a eu besoin d'une axiomatique. Plusieurs constructions sont proposées au début du XXe siècle comme la théorie des collectifs de Richard von Mises ou l'axiomatique de Andreï Kolmogorov. Cette dernière étant la plus pratique des axiomatiques disponibles à l'époque a été adoptée définitivement par les scientifiques à partir de 1950[a 6]. Elle a permis d'étudier le calcul des probabilités au-delà des probabilités finies, dites théorie discrète des probabilités et de considérer un cadre plus général pour la théorie des probabilités. Dans cette axiomatique, la théorie des probabilités est basée sur un espace probabilisé et ainsi beaucoup de notions correspondent à des notions de la théorie de l'intégration[12]. Cependant dans la théorie des probabilités, le but est de proposer un modèle prédictif pour une expérience aléatoire.
- Un ensemble, souvent noté , donne la liste de tous les résultats que l'on pourrait obtenir si on réalisait l'expérience[12]. Cet ensemble, dont les éléments sont appelés « éventualités » ou « cas possibles » ou « issues » est également appelé univers (ou champ) des possibles.
- Un ensemble dont les éléments sont tous les événements liés à l'expérience, chaque événement regroupant les éventualités pour lesquelles une certaine propriété est vérifiée. Ces événements, qui peuvent être réalisés ou pas au cours de l'expérience selon le résultat obtenu, représentent les seuls ensembles de possibilités pour lesquels on sait calculer la probabilité de réalisation. Mathématiquement, un élément est un sous-ensemble de et l'ensemble des événements liés à l'expérience possède une structure de tribu[12].
- L'espace probabilisable est muni d'une mesure de probabilité afin de pouvoir calculer la probabilité de réalisation de n'importe quel événement lié à l'expérience aléatoire. Mathématiquement, cette mesure de probabilité est une application qui à chaque événement associe une valeur réelle comprise au sens large entre 0 et 1, souvent exprimée en pourcentage, dite probabilité de l'événement A. Cette mesure de probabilité vérifie les trois axiomes des probabilités[13] :
- (positivité) la probabilité d'un événement est une valeur entre 0 et 1 : pour tout , ,
- (masse unitaire) la probabilité de l'univers est 1 : ,
- (additivité) pour toute suite dénombrable d'événements disjoints deux à deux, c'est-à-dire tels que pour tous , alors .











L'intérêt de cette construction plutôt abstraite est qu'elle permet une explication globale des calculs de probabilités notamment de pouvoir considérer à la fois les théories des probabilités discrète et continue (voir sections suivantes). Elle permet également de résoudre des problèmes probabilistes en cours au début du XXe siècle comme les paradoxes qui occupaient tant les scientifiques tels que Joseph Bertrand (voir le paradoxe de Bertrand), Émile Borel (voir le paradoxe du singe savant), etc.[a 6].
- Exemples
Donnons une modélisation sous forme d'espace probabilisé d'un exemple simple : le lancer d'un dé usuel cubique parfaitement équilibré.
- ,
- .



Cependant cette axiomatique n'est pas nécessaire pour calculer des probabilités dans des cas simples notamment dans le cas discret : il est facile de calculer que la probabilité d'obtenir un numéro pair dans le lancer de dé précédent est de 1/2.
Il est également possible de décrire une situation plus complexe. On considère le déplacement d'une particule soumise à des perturbations aléatoires[14]. Si on se limite à l'espace de temps , l'espace de probabilité naturel est l'ensemble des fonctions continues à valeurs dans . Autrement dit, un élément de est une fonction continue . La tribu associée à cet espace est la plus petite tribu qui rende toutes les applications mesurables. Reste à définir la mesure de probabilité; un exemple est de prendre la mesure de Wiener, c'est-à-dire la loi d'un mouvement brownien. Le choix de cet espace n'est généralement pas donné, on s'intéresse directement aux propriétés des fonctions définies sur cet espace[15].
![[0,1]](https://img.franco.wiki/i/738f7d23bb2d9642bab520020873cccbef49768d.svg)
![{\displaystyle \Omega ={\mathcal {C}}([0,1],\mathbb {R} ^{3})}](https://img.franco.wiki/i/b9a2e5d7040f14776fdfe57e6c430396fdc0fea3.svg)
![{\displaystyle \omega :[0,1]\rightarrow \mathbb {R} ^{3}}](https://img.franco.wiki/i/da49045b1662d759e2db1933aec8506a35267db0.svg)

Variable aléatoire

L'espace probabilisé construit dans la section précédente est un espace abstrait. Il n'est pas forcément adapté pour effectuer des calculs. Lorsque les résultats possibles de l'expérience aléatoire ne sont pas des nombres, c'est le cas des résultats pile et face dans un lancer de pièce, il est utile de pouvoir associer une valeur numérique à chaque résultat. Une variable aléatoire remplit ce rôle.

Une variable aléatoire est une application mesurable où est un espace mesurable[15]. C'est-à-dire qu'à chaque éventualité est associée une valeur . Si cette valeur est réelle, la variable aléatoire est dite réelle.




Comme précisé précédemment, il n'est pas toujours utile de définir l'espace probabilisé , mais il est possible de donner directement les variables aléatoires sur l'espace . La variable aléatoire s'écrit simplement au lieu de .

De la même manière qu'il existe des cas continus et discrets pour la théorie des probabilités, il existe des variables aléatoires discrètes[16] et continues[17]. Il est possible de considérer un vecteur aléatoire comme une variable aléatoire multidimensionnelle : . Lorsque la dimension n du vecteur n'est plus finie mais infinie, on parle de marche aléatoire ; lorsque la dimension est infinie non dénombrable, on parle de processus stochastique (voir la section Calcul stochastique ci-dessous).

- Exemple
Donnons un exemple simple du lancer de deux dés, ce qui est équivalent à lancer deux fois un dé. Une première variable aléatoire donne le résultat du premier lancer, une deuxième donne le résultat du deuxième lancer, c'est-à-dire et que l'on note plus simplement et .






Il est possible de s'intéresser à la somme des deux résultats, qui peut être notée par une variable aléatoire[15] : .

Théorie des probabilités discrète
La théorie des probabilités est dite discrète lorsque l'ensemble de l'espace probabilisé est fini ou dénombrable[18]. Le plus simple exemple d'étude en théorie des probabilités discrète est le jeu de pile ou face, dans ce cas l'univers ne contient que deux éléments : pile et face. Les études d'un lancer de dé, d'un tirage d'une carte dans un jeu de cartes ou par exemple du loto font également partie de la théorie des probabilités discrète.
Avant que la théorie de la mesure soit introduite, la probabilité d'un événement a été définie comme le nombre de cas favorables divisé par le nombre de cas possibles. De manière plus pratique, une expérience aléatoire était répétée un nombre N de fois, le nombre de fois où l'événement A est réalisé est noté . Lorsque N tend vers l'infini, la proportion converge vers une valeur dite probabilité de A[14].


Cependant ce raisonnement n'est pas si simple pour toute question relative à une expérience aléatoire. Les différentes manières de compter ont amené des paradoxes probabilistes. L'axiomatique de Kolmogorov (voir la section ci-dessus) a permis de résoudre ces problèmes. Dans le cas de la théorie discrète, pour une expérience non répétée, l'axiomatique s'écrit[14] :

où le choix peut être effectué pour représenter les différents résultats équiprobables de l'expérience. Plusieurs choix de tribu sont possibles, cependant il est raisonnable pour une étude discrète de choisir la tribu de l'ensemble des parties puisqu'elle contient tous les événements possibles :

- .

Dans le cas de la théorie discrète, la mesure de probabilité possède la particularité de pouvoir être définie uniquement sur les singletons[17] : . Les probabilités des autres événements s'obtiennent grâce aux axiomes des probabilités (voir la section ci-dessus).

Lorsque l'univers est fini, contenant n éléments, il est possible de choisir la mesure uniforme[16] : et ainsi obtenir la formule utile et cohérente à l'intuition des scientifiques plus anciens :

- pour tout .

Grâce à l'utilisation de ces formules, la théorie des probabilités discrète repose sur la théorie des combinaisons, aujourd'hui appelée la combinatoire et le dénombrement[19].
- Exemple
Reprenons l'exemple du lancer de deux dés[14]. L'ensemble de tous les possibles est :

C'est-à-dire que contient tous les couples de deux chiffres, le premier correspondant au résultat du premier dé, le deuxième au résultat du deuxième. Un choix possible pour la tribu est l'ensemble des parties :

Le choix de l'espace est fait de telle sorte que les singletons de aient tous la même probabilité : ils sont dits équiprobables. Il est alors possible de calculer les probabilités de plusieurs événements comme
- , donc .
- , donc . s'obtient également en décomposant en singletons : .






Théorie des probabilités continue
La théorie des probabilités est dite continue lorsque l'univers n'est plus dénombrable mais quelconque, possiblement non topologique[a 6]. C'est-à-dire lorsque la théorie des probabilités n'est plus discrète.
Il est possible de choisir plusieurs tribus, cependant lorsque l'univers est l'ensemble des réels, il est classique de lui munir la tribu borélienne qui possède de bonnes propriétés. Si ce n'est pas le cas, l'utilisation des variables aléatoires permet de représenter l'univers par l'ensemble des réels . Le terme théorie des probabilités continue est également utilisé pour désigner le cas où la variable aléatoire, ou la loi de probabilité, associée est absolument continue, c'est-à-dire qu'elle possède une densité.

La mesure de probabilité se définit plus facilement sur , c'est-à-dire qu'il est plus facile de définir la loi de probabilité de la variable aléatoire[a 6] :
- pour tout tel que soit l'image réciproque de par : .





Dans certains cas de la théorie des probabilités continue, la variable aléatoire réelle est dite absolument continue par rapport à la mesure de Lebesgue[17], c'est-à-dire qu'il existe une fonction telle que :


où le terme dans l'intégrale est une indicatrice. La fonction est appelée la densité de probabilité de .


Grâce à l'utilisation de ces formules, la théorie des probabilités continue repose sur la théorie de l'intégration[12].
- Exemple
Des algorithmes[20] de calcul utilisent des valeurs choisies de manière uniforme entre 0 et 1. C'est-à-dire que l'on choisit (aléatoirement) une valeur réelle entre 0 et 1 telle qu'aucune des valeurs n'ait plus de chance d'apparaître qu'une autre. Pour formaliser cette expérience, il y a un espace probabilisé non détaillé ici, cependant on se donne une variable aléatoire à valeurs dans muni de sa tribu borélienne ainsi que les probabilités[21] :
![{\displaystyle E=[0,1]}](https://img.franco.wiki/i/6d5a91f52a2bbc326ad37fe44aafc1242d41c20c.svg)
![{\displaystyle {\mathcal {E}}={\mathcal {B}}([0,1])}](https://img.franco.wiki/i/075821c057cd05750de6a1095cd50074d5088bec.svg)
- pour tout intervalle inclus dans .
![{\displaystyle \mathbb {P} (X\in [a,b])=b-a}](https://img.franco.wiki/i/b2c7a042bce5a7a0cd0df475aea03b0432e7dd69.svg)
![[a,b]](https://img.franco.wiki/i/9c4b788fc5c637e26ee98b45f89a5c08c85f7935.svg)
Propriétés et outils
Calculs élémentaires






Plusieurs formules dites élémentaires se déduisent des axiomes des probabilités (voir la section ci-dessus). Certaines sont intuitives, d'autres le sont moins.
Il est à noter que toute tribu contenant l'ensemble vide, le deuxième axiome des probabilités permet d'obtenir sa probabilité : . Un événement de probabilité nulle est appelé ensemble négligeable, ensemble -négligeable, ou ensemble impossible[22]. Il existe des ensembles négligeables autres que l'ensemble vide. Par exemple la probabilité d'obtenir le résultat pile à chaque lancer lors d'une infinité de lancers de pile ou face est nulle.

Il est possible de calculer la probabilité de la négation d'une proposition ; mathématiquement, c'est la probabilité du complémentaire d'un ensemble. Il est également possible d'obtenir la probabilité de se trouver dans une configuration ou dans une autre, cela correspond à une union de deux ensembles. Quant à la probabilité de se retrouver dans deux situations simultanément, c'est la probabilité de l'intersection des deux ensembles[23]. Elle est nulle si et seulement si ces deux ensembles ont une intersection négligeable; c'est le cas en particulier s'ils sont disjoints. En notant le complémentaire d'un événement et respectivement et la réunion et l'intersection de deux événements et , on a :

- .


- Exemple
Reprenons l'exemple du lancer de deux dés.
La probabilité d'obtenir au moins une fois un 6 peut se calculer à partir de la probabilité de ne pas obtenir de 6 lors des deux lancers :
- .

Cet événement est le même qu'obtenir un 6 au premier lancer ou un 6 au deuxième lancer. Sa probabilité s'obtient également par le calcul de la probabilité de l'union :

Indépendance
La notion d'indépendance est une hypothèse utilisée depuis longtemps en théorie des probabilités. On dit que deux événements sont indépendants lorsque le fait de connaître le résultat du premier événement ne nous aide pas pour prévoir le second et inversement. Plusieurs lancers de dés successifs sont considérés indépendants. Dans ce cas l'hypothèse est raisonnable, cependant d'autres situations d'indépendance peuvent paraître indépendantes alors qu'elles ne le sont pas. C'est le cas par exemple du problème de Monty Hall. L'indépendance n'est pas toujours intuitive et demande alors à être étudiée.
L'indépendance peut se définir sur les ensembles[24]; deux événements A et B sont dits indépendants si la probabilité que A apparaisse ne dépend pas de la connaissance de l'obtention de B. Mathématiquement, les événements sont indépendants si et seulement si la probabilité de leur intersection est égale au produit de leur probabilité[25] :

L'indépendance se définit également pour les variables aléatoires en utilisant la formule précédente. Les variables aléatoires X et Y sont indépendantes si[26] :
- , pour tout et tout ,



en reprenant les notations de la section variable aléatoire et pour les variables aléatoires réelles.

De même, des tribus et sont dites indépendantes si[26] :


- , pour tout et tout .



Lorsque l'on considère plusieurs événements, variables aléatoires ou tribus, il existe plusieurs notions d'indépendance. Les événements A, B et C sont dits[24]
- indépendants deux à deux si :
- mutuellement indépendants si : ils sont indépendants deux à deux et .


Ces définitions se généralisent pour plus de trois événements, variables aléatoires ou tribus, possiblement un nombre infini[24].
Probabilité conditionnelle et théorème de Bayes
À partir des probabilités élémentaires, il est possible de définir la probabilité conditionnelle d'un événement A sachant qu'un autre événement B est réalisé, notée ou . Si alors la probabilité de A sachant B est définie par[27] :



- .

Plus mathématiquement, est une nouvelle mesure de probabilité, elle permet de définir des espérances conditionnelles ou des lois conditionnelles. De manière plus générale, il est possible de définir la probabilité conditionnelle sachant une variable aléatoire, une probabilité conditionnelle sachant une tribu, une densité conditionnelle, etc.

Cette formule simple permet de faire le lien entre et par le très utile théorème de Bayes[25] :

- .

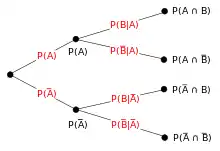
De même que la remarque précédente, il est possible de donner d'autres versions du théorème de Bayes par un conditionnement utilisant des variables aléatoires, des tribus ou par l'intermédiaire de lois de probabilité.
Il est possible de décomposer la probabilité d'un événement en probabilités conditionnelles sachant toutes les situations possibles. C'est le rôle de la formule des probabilités totales[25] : pour une partition d'événements , possiblement infinie,

- .

Une manière de représenter cette formule est un arbre de probabilité, chaque branche représente un cas possible.
- Exemple
Reprenons l'exemple des deux dés. Considérons les deux événements : « le résultat du premier lancer est i », B : « le résultat de la somme des deux lancers est 7 » et C : « le résultat du premier lancer est pair ». Il est facile de calculer les probabilités : , et . La formule des probabilités totales permet d'obtenir :




- et .


Le théorème de Bayes permet d'obtenir la probabilité d'avoir eu un résultat pair au premier lancer sachant que la somme des deux résultats est de 7 :
- .

Lois de probabilité
Comme précisé dans les sections ci-dessus, le choix de la mesure de probabilité pour l'espace probabilisé peut se faire en donnant directement les probabilités d'une variable aléatoire X. Ainsi la mesure de probabilité donnée par[15] :


est appelée la loi de probabilité de la variable X. Elle décrit complètement le comportement de la variable X. De manière plus générale, une loi de probabilité est une mesure décrivant le comportement aléatoire d'un phénomène dépendant du hasard, c'est-à-dire qu'elle n'est pas toujours définie à partir d'une variable aléatoire. Cependant pour une loi de probabilité donnée, il existe une variable aléatoire dont la loi est la loi de probabilité précédente. La représentation d'une loi par une variable aléatoire n'est pas unique, c'est-à-dire que deux variables aléatoires différentes peuvent avoir la même loi. Comme mentionné dans les sections précédentes, il existe des lois discrètes, des lois absolument continues, mais il existe également des lois plus générales. Les lois discrètes et les lois absolument continues peuvent s'écrire respectivement sous la forme[17] :
- et


Certaines lois de probabilité sont fréquemment rencontrées en théorie des probabilités car on les retrouve dans de nombreux processus naturels. Les lois discrètes les plus fréquentes sont la loi uniforme discrète, la loi de Bernoulli, ainsi que les lois binomiale, de Poisson et géométrique. Les lois uniforme continue, normale, exponentielle et gamma sont parmi les plus importantes lois continues.
Plusieurs outils permettent de définir et étudier ces lois. La fonction de répartition, la fonction caractéristique, la fonction génératrice, la fonction quantile, la densité de probabilité (pour les lois continues), la fonction de masse (pour les lois discrètes) en sont les exemples principaux.
Espérance et moments
L'espérance est une propriété des lois de probabilités mais elle s'écrit plus simplement en utilisant une variable aléatoire. Elle donne la moyenne de la variable aléatoire X. L'espérance de la variable aléatoire X de loi est donnée par[17] :

![{\displaystyle \mathbb {E} [X]=\int _{\Omega }X(\omega )\mathbb {P} (\mathrm {d} \omega )=\int _{\mathbb {R} }x\mathbb {P} _{X}(\mathrm {d} x).}](https://img.franco.wiki/i/087e77e5f4fb2722009bd3b00d06f1deba607e98.svg)
Cette expression s'écrit de manière plus simple dans le cas des variables discrètes et des variables continues (en reprenant les notations de la section Lois de probabilité) : pour le cas discret[28] et pour le cas continu, si les séries et intégrales convergent.
![{\displaystyle \mathbb {E} [X]=\sum _{x\in E}xp(x)}](https://img.franco.wiki/i/4020f18a9158684d25d172f8fe6cd5183cd11ea4.svg)
![{\displaystyle \mathbb {E} [X]=\int _{E}xf(x)\mathrm {d} x}](https://img.franco.wiki/i/9d628c6b6d2adbc9f5143c9539d3310197d52ad7.svg)
Il est possible de calculer l'espérance d'une fonction de la variable aléatoire par la formule[29] : pour toute fonction mesurable
![{\displaystyle g:E\rightarrow [0,\infty ]}](https://img.franco.wiki/i/7dc7ba1230d6f8e4770e66ddd3999e54f3d2d231.svg)
- .
![{\mathbb E}[g(X)]=\int _{E}g(x){\mathbb P}_{X}({\mathrm {d}}x)](https://img.franco.wiki/i/a6cd87d025199fdf18b1c99f1f3cf04c7dc48b4a.svg)
Lorsque la fonction est suffisamment générale, alors permet de récupérer la loi de X. Pour la fonction indicatrice , l'espérance redonne la probabilité : . Pour les fonctions , les valeurs sont les moments de la loi de X.

![{\displaystyle \mathbb {E} [g(X)]}](https://img.franco.wiki/i/cb253635a926d6c62d417eb547d9efbe4141ff70.svg)

![{\displaystyle \mathbb {E} [g(X)]=\mathbb {E} [{\mathbf {1} }_{B}(X))]=\mathbb {P} (X\in B)}](https://img.franco.wiki/i/e8577e17b6a9046b3959b349d5f1ad6dddefe967.svg)

![{\displaystyle \mathbb {E} [g(X)]=\mathbb {E} [X^{n}]}](https://img.franco.wiki/i/cd41fa97d29212b615fbec8f94c5cdb567064d43.svg)
Ces définitions sont valides pour tout espace de valeurs de la variable aléatoire. Dans le cas multidimensionnel, c'est-à-dire de vecteurs aléatoires réels, la notion d'espérance se généralise en vecteur des moyennes et la variance en matrice de variance-covariance qui donne les variances des coordonnées sur la diagonale et les covariances entre coordonnées dans le reste de la matrice[30].
L'espérance et les moments permettent d'obtenir des inégalités[31] : sans préciser les conditions d'existence,
- inégalité de Markov : ,
- inégalité de Bienaymé-Tchebychev : .
![{\mathbb P}(|X|\geq t)\leq {\frac {{\mathbb E}[X]}{t}}](https://img.franco.wiki/i/c9b3e7be81fce5e45b7ffd3a82e1a57af72d6da1.svg)
![{\mathbb P}(|X-{\mathbb E}[X]|\geq t)\leq {\frac {Var[X]}{t^{2}}}](https://img.franco.wiki/i/54357ac496421fe4efb80448f5f85b82fb0028f8.svg)
Ces inégalités sont très utiles pour estimer la queue de la loi d'une variable aléatoire, c'est-à-dire le comportement de la variable aléatoire lorsqu'elle prend des valeurs éloignées de sa moyenne.
Convergences et résultats limites
Lorsque l'on considère un nombre infini de données aléatoires, elles sont modélisées par une suite (infinie) de variables aléatoires. Il peut être utile d'étudier le comportement limite de cette suite. Plusieurs notions de convergences de variables aléatoires ont été définies et des théorèmes limites renseignent sur les résultats asymptotiques.
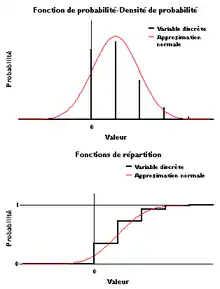
Une suite de variables aléatoires [32],[33] :

- converge en loi vers une variable aléatoire X si la suite de leurs lois de probabilité converge étroitement vers une loi . En particulier dans le cas réel, cette convergence est équivalente à la convergence des fonctions de répartition vers la fonction de répartition de X en tout point de continuité de cette dernière[34]. Cette convergence est également équivalente à la convergence des fonctions caractéristiques, c'est le théorème de continuité de Paul Lévy[35].
- converge en probabilité vers une variable aléatoire X si pour tout , . Cette convergence implique la convergence en loi.
- converge presque sûrement vers une variable aléatoire X si . Cette convergence implique les convergences en probabilité et en loi.
- converge dans vers une variable aléatoire X si . Cette convergence implique la convergence en probabilité.






Donnons quelques théorèmes limites importants :
- théorème de Borel-Cantelli[36] : pour une suite d'événements, si converge alors . Réciproquement, si les événements sont indépendants et si diverge alors .
- loi du zéro un de Kolmogorov[37] (également appelé loi du tout ou rien[38]) : pour une suite de variables aléatoires, notons la tribu asymptotique où , alors pour tout événements , 0 ou 1. Intuitivement, un événement qui ne dépend que d'un comportement limite est de probabilité 0 ou 1.
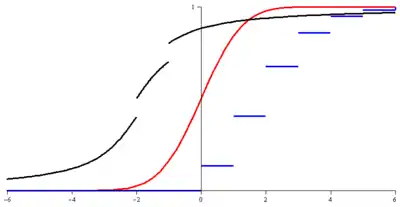
- loi des grands nombres (faible)[39] : pour une suite de variables aléatoires indépendantes, de même loi et de variance finie, alors converge dans vers la moyenne de la loi commune . Les hypothèses de ce théorème peuvent être diminuées pour obtenir cette même convergence dans . Il est également possible d'obtenir une convergence presque sûre, c'est la loi forte des grands nombres[40]. Intuitivement, ces résultats annoncent que lors d'un grand nombre d'expériences, la moyenne calculées des résultats tend à se rapprocher de la moyenne théorique du phénomène aléatoire.
- théorème central limite[41] : pour une suite de variables aléatoires indépendantes, de même loi et de variance finie, alors converge en loi vers une variable aléatoire de loi normale . Ce théorème possède plusieurs versions : dans le cas où les variables aléatoires sont de loi de Bernoulli c'est le théorème de Moivre-Laplace, ce théorème peut s'écrire par l'intermédiaire des fonctions de répartition ou des fonctions caractéristiques. Il existe une version multidimensionnelle de ce théorème central limite pour des vecteurs aléatoires[42].











![\mathbb E[X]](https://img.franco.wiki/i/09de7acbba84104ff260708b6e9b8bae32c3fafa.svg)

![{\displaystyle (X_{1}+\dots +X_{n}-n\mathbb {E} [X_{1}])/{\sqrt {n}}}](https://img.franco.wiki/i/26339208fe56749d020f350135d0178e72f7402d.svg)

Pour pouvoir utiliser ces théorèmes de convergence dans les applications, notamment informatiques, il est utile de connaître leur vitesse de convergence : c'est l'étude du principe de grandes déviations[43].
Calcul stochastique
Le calcul stochastique est l'étude des phénomènes qui évoluent au cours du temps de manière aléatoire[44]. Le temps peut être modélisé de manière discrète, c'est-à-dire par les valeurs entières : , dans ce cas le phénomène est représenté par une suite (infinie) de variables aléatoires : , c'est une marche aléatoire. Le temps peut également être modélisé de manière continue c'est-à-dire par des valeurs réelles ou , il s'agit alors de processus stochastique .





Marche aléatoire et chaîne de Markov
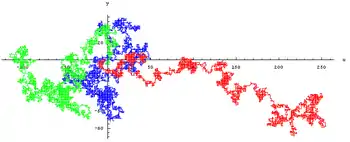

Parmi les modélisations de phénomènes aléatoires dépendant du temps, certaines l'ont été par un temps discret, c'est-à-dire à valeurs entières : . Un processus est appelé marche aléatoire[45] partant d'un point lorsque la variable s'écrit sous la forme d'une somme de pas aléatoires donnée par des variables :



- et pour .



L'espace de probabilité et la tribu sur lequel le processus est défini ne sont pas triviaux, et la notion de filtration a donc été introduite. C'est une suite de tribus prévue pour que la marche aléatoire puisse être définie sur chaque tribu de la suite: le processus est dit adapté[46].
Une propriété particulière des marches aléatoires est régulièrement utilisée. Une marche aléatoire est appelée chaîne de Markov si elle possède la propriété de Markov, c'est-à-dire que le n-ième pas ne dépend pas du comportement du processus avant ce pas. Autrement dit, le comportement à venir ne dépend que du temps présent et non du temps passé. Plusieurs expressions mathématiques traduisent cette propriété; en voici une courante grâce aux probabilités conditionnelles[47] :
- .

La probabilité est appelée la probabilité de transition de l'état à l'état . Lorsque le nombre d'états possibles est fini, toutes ces probabilités sont résumées dans une matrice stochastique, ou matrice de transition. Elle représente à elle seule la chaîne de Markov[47]. La chaîne de Markov dont les états possibles sont les valeurs entières et telle que les probabilités d'aller vers les plus proches voisins sont identiques est appelée la chaîne de Markov simple sur [48].



Les récurrence et transience d'une chaîne de Markov sont également étudiées. Si une marche aléatoire revient indéfiniment au point de départ, elle est dite récurrente, sinon elle est transiente. Les temps d'arrêt représentent le temps en lequel la marche possède pour la première fois une certaine propriété[49].
Ces notions se généralisent de plusieurs manières[50] : les pas peuvent être des vecteurs aléatoires multidimensionnels ; les états possibles peuvent être les points d'un graphe plus général : ceci introduit, entre autres, la théorie des graphes aléatoires et la théorie de la percolation qui font partie de la théorie des systèmes dynamiques ; le n-ième pas peut être la somme d'un nombre aléatoire de variables, c'est le cas des processus de branchement.
L'étude du comportement de la marche aléatoire lorsque le temps devient grand amène à considérer des théorèmes limites sur les processus, tels que le théorème de Donsker ou le théorème de Glivenko-Cantelli très utilisés en statistique. Apparaissent alors des processus aléatoires dont le temps n'est plus discret mais continu.
Processus stochastique et processus de Markov
L'introduction des processus aléatoires à temps continu a été possible notamment grâce à l'axiomatique de Kolmogorov. Les processus stochastiques sont des familles de variables aléatoires indexées par un indice réel : . De même que dans le cas du temps discret, les notions de filtration et de processus adapté, permettent de définir mathématiquement le processus. Les théorèmes d'extension de Kolmogorov et d'extension de Carathéodory permettent de donner l'existence via les lois finies dimensionnelles, c'est-à-dire que le processus est défini par la donnée d'un nombre fini de ses accroissements[51] :

- la loi de peut être donnée par une matrice de variance-covariance.

Des probabilités de transitions sont données par des fonctions du type qui donnent la probabilité que le processus soit dans un des états de l'ensemble A au temps sachant qu'au temps le processus était en . Elle doit vérifier l'équation de Chapman-Kolmogorov[a 6],[52] :



- , pour tout .

![u\in ]s,t[](https://img.franco.wiki/i/169e4e3d0a433338e2c634e7c80f1b02c29ab995.svg)
Un exemple important de processus stochastique est le mouvement brownien, il apparait comme limite (en loi) d'une suite de marches aléatoires via le théorème de Donsker[53], il est également un objet central puisque ses lois finies dimensionnelles sont des lois normales, c'est-à-dire que ses accroissements sont gaussiens. La loi du processus est appelée mesure de Wiener[54]. Le mouvement brownien a été beaucoup étudié et nombreux objets mathématiques lui sont liés : bruit blanc, mouvement brownien fractionnaire, processus de Lévy, pont brownien, arbre brownien, processus stationnaire, etc. Le processus de Poisson est un processus de Markov dont les accroissements sont de loi de Poisson[55], ce processus de comptage est un processus de sauts[56].
Différentes méthodes de définition existent : le processus (en) de Feller est un processus de Markov dont les probabilités de transition possède une propriété dite de Feller[57], le processus d'Ornstein-Uhlenbeck est défini à partir d'une équation différentielle stochastique[58] (voir la section ci-dessous), les processus ponctuels sont définis sur des espaces plus généraux, l'espace des excursions par exemple[59]. Une autre manière est l'utilisation de générateurs infinitésimaux, c'est une fonctionnelle sur les fonctions continues qui décrit comment le processus se déplace de points en points. Le générateur infinitésimal d'un processus de Markov X est l'opérateur A tel que[60] :
![Af(x)=\lim _{{t\rightarrow 0}}{\frac {1}{t}}\left({\mathbb E}[f(X_{t})|X_{0}=x]-f(x)\right).](https://img.franco.wiki/i/41a908a13d68c35ab27e28fd058d51ef20e8e64c.svg)
Les processus stochastiques sont utilisés dans de nombreux domaines[a 5] : historiquement le mouvement brownien a été utilisé pour modéliser des trajectoires de particules ou pour calculer le nombre d'Avogadro, il est également utilisé pour modéliser des phénomènes tels que les marchés financiers dont les premiers travaux sont dus à Louis Bachelier ou les travaux en physique par les travaux de Sydney Chapman[a 6].
Martingales
Parmi les processus stochastiques à temps discret et à temps continu, certains possèdent une propriété liée à la filtration sur laquelle ils sont définis. Un processus est appelé une martingale si[61] :

- pour tout .
![n\in \mathbb{N} ,{\mathbb E}[X_{{n+1}}|{\mathcal F}_{n}]=X_{n}](https://img.franco.wiki/i/ae57b5a8303bc7c3ea494c9aa14306d80611161e.svg)
Cette définition se généralise pour un processus stochastique en temps continu. Le processus est une sur-martingale si et une sous-martingale si . Intuitivement la valeur moyenne du processus à un temps futur n + 1 connaissant le passé est égale à la valeur présente du processus. C'est une représentation du bénéfice dans un jeu équitable, c'est de cette correspondance que provient le nom martingale. Une sous-martingale correspond à un jeu favorable et une sur-martingale à un jeu défavorable.
![{\displaystyle \mathbb {E} [X_{n+1}|{\mathcal {F}}_{n}]\leq X_{n}}](https://img.franco.wiki/i/7cddf0212cbd31940727cf3378d4e8a72a1ce811.svg)
![{\displaystyle \mathbb {E} [X_{n+1}|{\mathcal {F}}_{n}]\geq X_{n}}](https://img.franco.wiki/i/c523150b75088bada6c194580c7bf93e0854d3fd.svg)
Les martingales ont donc une moyenne constante en tout temps ainsi qu'en certains temps aléatoires : les temps d'arrêt, c'est ce qu'annonce le théorème d'arrêt de Doob[48].
Les bonnes propriétés des martingales permettent d'obtenir des inégalités[62] ainsi que des résultats de convergence[63].
Formule d'Itô et équations différentielles stochastiques
Une intégrale stochastique est soit l'intégration d'un processus aléatoire par rapport à une mesure (non aléatoire)[a 6], soit l'intégration d'une fonction (localement bornée) par rapport à un processus stochastique (semi-martingale continue)[64]. Dans le cas où la fonction est étagée, l'intégrale se définit simplement par une formule du type :
- .

De manière plus générale, l'intégrale se définit à partir d'un objet appelé crochet de martingale[65]. L'intégrale s'écrit alors de manière plus simple avec la notation : . En particulier on obtient .



La formule d'Itô dans sa formule générale la plus courante s'écrit sous la forme[a 6] : pour une fonction de classe C1 en et de classe C2 en :


où est un mouvement brownien et X est un processus stochastique solution de l'équation différentielle stochastique :

- .

Cette formule permet d'obtenir des formules utiles dans le cas du mouvement brownien par exemple[66] :

- , ou
- .


Calcul de Malliavin
Le Calcul de Malliavin, également connu sous le nom calcul stochastique des variations, est une méthode de calculer grâce à des opérateurs différentiels de dimension infinie sur l'espace de Wiener[67]. Il a été initié par Paul Malliavin pour étudier les propriétés des fonctionnelles appliquées au processus de Wiener. Le calcul de Malliavin comprend l'utilisation d'un opérateur différentiel, une formule d'intégration par parties liées aux intégrales stochastiques mais également la notion de matrice de covariance.
Relations avec d'autres domaines
Les domaines liés avec la théories des probabilités sont nombreux, donnons ici quelques exemples.
Statistique
La statistique et la théorie des probabilités forment les sciences de l'aléatoire. Ces deux sciences utilisent les mêmes outils aléatoires (loi de probabilité, espérance, écart-type, etc), les frontières entre ces deux domaines sont assez floues[a 7]. Une des différences entre statistique et probabilité vient de l'interprétation faite du hasard : c'est la différence entre probabilité a priori et probabilité a posteriori. Intuitivement, les probabilités permettent d'évaluer les chances de réalisation d'un évènement dans un cadre prédéfini[68] alors que la statistique est l'étude et l'analyse de caractères à partir de données récoltées[69].
Les notions de la théorie des probabilités sont les outils à la base de la théorie statistique[70]. Certaines lois de probabilités ont même une utilisation principalement en statistique plutôt que dans la modélisation directe d'un phénomène[71].
Jeux et paris
Les jeux de hasard ont été une des premières motivations pour développer le calcul des probabilités, avec notamment le problème des partis[3]. Les raisonnements au début faits de manière peu rigoureuse sont devenus plus élaborés avec l'arrivée de l'axiomatique de Kolmogorov. Cette écriture scientifique permet dorénavant de pouvoir faire des calculs plus précis sur des questions autour des jeux de hasard[72] : calcul de probabilité dans les jeux de dés, dans les jeux de pile ou face, pour les paris à la loterie, etc. Ces études ont alors donné naissance à une théorie : la théorie des jeux.
De nombreux paradoxes probabilistes sont devenus des jeux mathématiques[72] : c'est le cas du problème de Monty Hall, du paradoxe des prisonniers ou encore du problème de la Belle au bois dormant.
Physique
Biologie
De nombreuses méthodes statistiques sont utilisées en biologie pour réaliser des échantillonnages d'individus et pouvoir ainsi mieux connaître la population entière. Ces données statistiques sont alors étudiées grâce au calcul des probabilités[73].
Économie
Le calcul des probabilités permet de mieux apprécier les risques économiques qui sont considérés comme aléatoires[74]. C'est le cas dans les calculs d'assurances, dans la gestion des stocks ou dans la finance moderne telle que la création d'un portefeuille d'actifs ou dans les activités de spéculation.
Notes et références
Ouvrages
- ↑ Laplace 1814, p. ii.
- 1 2 Laplace 1814, p. iii.
- 1 2 3 Quetelet 1853, p. 7.
- ↑ Quetelet 1853, p. 78.
- 1 2 Jacod et Protter 2003, p. 1.
- ↑ Omnès 2000, p. 44.
- ↑ Quinio Benamo 2005, p. 61.
- ↑ Cournot 1843, p. iv.
- ↑ Cournot 1843, p. i.
- ↑ Laplace 1814, p. i.
- ↑ Cournot 1843, p. v.
- 1 2 3 4 Le Gall 2006, p. 91.
- ↑ Sinaï 1992, p. 6.
- 1 2 3 4 Le Gall 2006, p. 92.
- 1 2 3 4 Le Gall 2006, p. 93.
- 1 2 Sinaï 1992, p. 9.
- 1 2 3 4 5 Le Gall 2006, p. 94.
- ↑ Sinaï 1992, p. 1.
- ↑ Cournot 1843, p. 21.
- ↑ Le Gall 2006, p. 114.
- ↑ Le Gall 2006, p. 98.
- ↑ Sinaï 1992, p. 7.
- ↑ Bertoin 2000, p. 7.
- 1 2 3 Jacod et Protter 2003, p. 15.
- 1 2 3 Sinaï 1992, p. 44.
- 1 2 Sinaï 1992, p. 45.
- ↑ Jacod et Protter 2003, p. 16.
- ↑ Sinaï 1992, p. 10.
- ↑ Le Gall 2006, p. 95.
- ↑ Bertoin 2000, p. 66.
- ↑ Bertoin 2000, p. 16.
- ↑ Bertoin 2000, p. 34.
- ↑ Bertoin 2000, p. 35.
- ↑ Le Gall 2006, p. 132.
- ↑ Le Gall 2006, p. 136.
- ↑ Bertoin 2000, p. 33.
- ↑ Jacod et Protter 2003, p. 72.
- ↑ Le Gall 2006, p. 127.
- ↑ Le Gall 2006, p. 120.
- ↑ Le Gall 2006, p. 129.
- ↑ Le Gall 2006, p. 138.
- ↑ Bertoin 2000, p. 69.
- ↑ Bertoin 2000, p. 44.
- ↑ Revuz et Yor 2004, p. 15.
- ↑ Le Gall 2006, p. 165.
- ↑ Le Gall 2006, p. 163.
- 1 2 Le Gall 2006, p. 191.
- 1 2 Le Gall 2006, p. 169.
- ↑ Le Gall 2006, p. 167.
- ↑ Le Gall 2006, p. 193.
- ↑ Le Gall 2006, p. 220.
- ↑ Revuz et Yor 2004, p. 80.
- ↑ Le Gall 2006, p. 219.
- ↑ Le Gall 2006, p. 226.
- ↑ Revuz et Yor 2004, p. 58.
- ↑ Revuz et Yor 2004, p. 115.
- ↑ Revuz et Yor 2004, p. 90.
- ↑ Revuz et Yor 2004, p. 38.
- ↑ Revuz et Yor 2004, p. 481.
- ↑ Revuz et Yor 2004, p. 281.
- ↑ Le Gall 2006, p. 164.
- ↑ Revuz et Yor 2004, p. 54.
- ↑ Le Gall 2006, p. 171.
- ↑ Revuz et Yor 2004, p. 141.
- ↑ Revuz et Yor 2004, p. 138.
- ↑ Revuz et Yor 2004, p. 146.
- ↑ Nualard 2013, p. 1.
- ↑ Quinio Benamo 2005, p. 4.
- ↑ Quinio Benamo 2005, p. 36.
- ↑ Delsart et Vaneecloo 2010, p. 257.
- ↑ Delsart et Vaneecloo 2010, p. 207.
- 1 2 Nahin 2008, p. 1.
- ↑ Quinio Benamo 2005, p. 63.
- ↑ Delsart et Vaneecloo 2010, p. 6.
Articles et autres sources
- 1 2 Rama Cont, « risques financiers : quelle modélisation mathématique? », Pour la science, no 375, , p. 24-27 (lire en ligne).
- ↑ Richard von Mises, « Théorie des Probabilités. Fondement et applications », annales de l'IHP, vol. 3, no 2, , p. 137-190 (lire en ligne).
- ↑ En anglais : Probability theory is a branch of mathematics concerned with the analysis of random phenomena, dans « Probability theory », sur Encyclopædia Britannica, .
- ↑ (en) Alan Hájek, « Interpretations of Probability », sur Stanford Encyclopedia of Philosophy, .
- 1 2 Laurent Schwartz, Un mathématicien aux prises avec le siècle, Paris, Odile Jacob, , 531 p. (ISBN 2-7381-0462-2, lire en ligne), p. 172.
- 1 2 3 4 5 6 7 8 Loïc Chaumont, Laurent Mazliak et Marc Yor, A.N. Kolmogorov : Quelques aspects de l'œuvre probabiliste, Belin, (lire en ligne [PDF]).
- ↑ Pierre Dagnelie, « Diversité et unité de la statistique », Journal de la société statistique de Paris, vol. 123, no 2, , p. 86-92 (lire en ligne).
Voir aussi
Bibliographie
- Jean Bertoin, Probabilités : cours de licence de mathématiques appliquées, , 79 p. (lire en ligne)
- Joseph Bertrand, Calcul Des Probabilités (copie d'un ouvrage de 1923), American Mathematical Soc., , 3e éd., 332 p. (lire en ligne)

- Nicolas Bouleau, Probabilités de l'ingénieur, Hermann, , 387 p.
- Antoine-Augustin Cournot, Exposition de la théorie des chances et des probabilités, Paris, Hachette, , 448 p. (lire en ligne)
- Bernard Courtebras, À l'école des probabilités, Press univ. Franche-Comté, , 282 p. (lire en ligne)
- Bernard Courtebras, Mathématiser le hasard, Vuibert, 2008
- Virginie Delsart et Nicolas Vaneecloo, Méthodes statistiques de l'économie et de la gestion, Presses Univ. Septentrion, , 317 p. (lire en ligne)
- (en) Jean Jacod et Philip E. Protter, Probability Essentials, Springer, , 254 p. (lire en ligne)
- Pierre-Simon de Laplace, Théorie analytique des probabilités, Paris, Courcier, , 2e éd., 506 p. (lire en ligne)
- Jean-François Le Gall, Intégration, Probabilités et Processus aléatoires : cours de l'ENS, , 248 p. (lire en ligne)
- (en) Paul J. Nahin, Digital Dice. Computational Solutions to Practical Probability Problems, Princeton University Press, , 263 p. (lire en ligne)
- (en) David Nualard, The Malliavin Calculus and Related Topics, Springer, , 266 p. (lire en ligne)
- Roland Omnès, Comprendre la mécanique quantique, EDP Sciences, , 272 p. (lire en ligne)
- Adolphe Quetelet, Théorie des probabilités, Bruxelles, A. Jamar, , 104 p. (lire en ligne)
- Martine Quinio Benamo, Probabilités et Statistique aujourd'hui : pourquoi faire ? Comment faire ?, Paris/Budapest/Kinshasa etc., l'Harmattan, , 277 p. (ISBN 2-7475-9799-7, lire en ligne)
- Daniel Revuz, Probabilités, Hermann, , 301 p.
- (en) Daniel Revuz et Marc Yor, Continuous martingales and Brownian motion, vol. 293, Springer, , 3e éd., 606 p. (lire en ligne)
- (en) Iakov Sinaï, Probability theory : An introductory course, Berlin/Heidelberg/Paris etc., Springer, , 138 p. (ISBN 3-540-53348-6, lire en ligne)
Articles connexes
- Probabilité
- Axiomes des probabilités
- Loi de probabilité
- Interconnexions entre la théorie des probabilités et les statistiques
- Théorie de la mesure
- Théorie des possibilités
Liens externes
- Notices dans des dictionnaires ou encyclopédies généralistes :
- Ressource relative à la santé :