| Type |
Type of statistical method (d), regression (d), régression |
|---|---|
| Inventeur | |
| Aspect de |
En statistiques, en économétrie et en apprentissage automatique, un modèle de régression linéaire est un modèle de régression qui cherche à établir une relation linéaire entre une variable, dite expliquée, et une ou plusieurs variables, dites explicatives.
On parle aussi de modèle linéaire ou de modèle de régression linéaire.
Parmi les modèles de régression linéaire, le plus simple est l'ajustement affine. Celui-ci consiste à rechercher la droite permettant d'expliquer le comportement d'une variable statistique y comme étant une fonction affine d'une autre variable statistique x.
En général, le modèle de régression linéaire désigne un modèle dans lequel l'espérance conditionnelle de y connaissant x est une fonction affine des paramètres. Cependant, on peut aussi considérer des modèles dans lesquels c'est la médiane conditionnelle de y connaissant x ou n'importe quel quantile de la distribution de y connaissant x qui est une fonction affine des paramètres[1].
Le modèle de régression linéaire est souvent estimé par la méthode des moindres carrés mais il existe aussi de nombreuses autres méthodes pour estimer ce modèle. On peut par exemple estimer le modèle par maximum de vraisemblance ou encore par inférence bayésienne.
Bien qu'ils soient souvent présentés ensemble, le modèle linéaire et la méthode des moindres carrés ne désignent pas la même chose. Le modèle linéaire désigne une classe de modèles qui peuvent être estimés par un grand nombre de méthodes, et la méthode des moindres carrés désigne une méthode d'estimation. Elle peut être utilisée pour estimer différents types de modèles.
Histoire

Ruđer Josip Bošković est le premier scientifique à calculer les coefficients de régression linéaire, en 1755-1757, quand il entreprit de mesurer la longueur de cinq méridiens terrestres en minimisant la somme des valeurs absolues[3]. Pierre-Simon de Laplace utilise cette méthode pour mesurer les méridiens dans « Sur les degrés mesurés des méridiens et sur les longueurs observées sur pendule » en 1789[3]. La première utilisation de la méthode des moindres carrés est attribuée à Adrien-Marie Legendre en 1805 [4] ou à Carl Friedrich Gauss qui dit l'avoir utilisée à partir de 1795[3].
Carl Friedrich Gauss démontre en 1821 le théorème connu aujourd'hui sous le nom de théorème de Gauss-Markov qui exprime sous certaines conditions la qualité des estimateurs ; Andrei Markov le redécouvre en 1900[5].
La paternité de l'expression « régression linéaire » revient à Francis Galton qui, dans un article de 1886[3], constate un phénomène de « régression vers la moyenne »[6] de la taille des fils en fonction de la taille des pères.
Plus tard la colinéarité des variables explicatives est devenue un sujet de recherche important. En 1970, Arthur E. Hoerl et Robert W. Kennard proposent la régression pseudo-orthogonale (Ridge Regression), une des méthodes d'estimation conçues pour pallier la présence de colinéarité de certaines variables explicatives en imposant des contraintes sur les coefficients[7].
La méthode du lasso (Lasso Regression), ayant le même objectif en utilisant une technique analogue, a été créée en 1996 par Robert Tibshirani[8].
Avec les méthodes de régression sur composantes (régression des moindres carrés partiels (PLS) et régression sur composantes principales), les algorithmes recherchent des variables explicatives indépendantes liées aux variables initiales, puis estiment les coefficients de régression sur les nouvelles variables[9].
Applications
Comme les autres modèles de régression, le modèle de régression linéaire est aussi bien utilisé pour chercher à prédire un phénomène que pour chercher à l'expliquer.
Après avoir estimé un modèle de régression linéaire, on peut prédire quel serait le niveau de y pour des valeurs particulières de x.
Il permet également d'estimer l'effet d'une ou plusieurs variables sur une autre en contrôlant par un ensemble de facteurs. Par exemple, dans le domaine des sciences de l'éducation, on peut évaluer l'effet de la taille des classes sur les performances scolaires des enfants en contrôlant par la catégorie socio-professionnelle des parents ou par l'emplacement géographique de l'établissement. Sous certaines hypothèses restrictives, cet effet peut être considéré comme un effet causal.
En apprentissage statistique, la méthode de régression linéaire est considérée comme une méthode d'apprentissage supervisé utilisée pour prédire une variable quantitative[10].
Dans cette perspective, on entraîne généralement le modèle sur un échantillon d'apprentissage et on teste ensuite les performances prédictives du modèle sur un échantillon de test.
Présentation formelle
Notations
On rencontre principalement trois types de notations[11].
Notation simple (ou scalaire)
On considère le modèle pour l'individu i. Pour chaque individu, la variable expliquée s'écrit comme une fonction linéaire des variables explicatives.

où yi et les xi,j sont fixes et εi représente l'erreur.
Notation vectorielle
La notation vectorielle est similaire à la notation simple mais on utilise la notation vectorielle pour synthétiser la notation. Cette notation est pratique lorsqu'il y a un grand nombre de variables explicatives. On définit β le vecteur des paramètres du modèle et xi' le vecteur ligne des variables explicatives pour l'individu i . Le modèle se réécrit alors de la manière suivante[12] :



Notation matricielle
Enfin, on rencontre aussi souvent une notation matricielle. Ici, on écrit le modèle pour chacun des n individus présents dans l'échantillon. Le modèle s'écrit alors[13] :

avec

Terminologie
Le modèle linéaire est utilisé dans un grand nombre de champs disciplinaires. Il en résulte une grande variété dans la terminologie. Soit le modèle suivant :
La variable Y est appelée variable expliquée, variable dépendante, variable endogène ou encore réponse. Les variables X sont appelées variables explicatives, variable indépendante, variables exogènes ou encore prédicteurs. ε est appelé terme d'erreur ou perturbation.
On note généralement le vecteur des paramètres estimés. On définit la valeur prédite ou ajustée et le résidu comme la différence entre la valeur observée et la valeur prédite : .



On définit aussi la somme des carrés des résidus (SCR, ou SSR en anglais) comme la somme sur toutes les observations des carrés des résidus :

Modèle linéaire simple
On appelle généralement modèle linéaire simple un modèle de régression linéaire avec une seule variable explicative[14]. Ce modèle est souvent présenté dans les manuels de statistiques à des fins pédagogiques, sous le titre d'ajustement affine.
On a donc deux variables aléatoires, une variable expliquée Y, qui est un scalaire, une variable explicative X, également scalaire. On dispose de n réalisations de ces variables, (xi)1 ≤ i ≤ n et (yi)1 ≤ i ≤ n, soit :

où εi est le terme d'erreur ; chaque terme d'erreur lui-même est une réalisation d'une variable aléatoire Ei.
Droite de régression
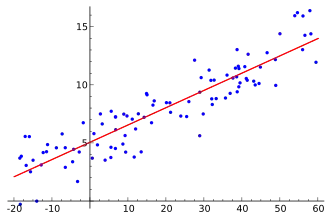
Dans le cadre d'un modèle linéaire simple, on peut représenter graphiquement la relation entre x et y à travers un nuage de points. L'estimation du modèle linéaire permet de tracer la droite de régression, d'équation . Le paramètre β0 représente l'ordonnée à l'origine et β1 le coefficient directeur de la droite.

Modèle linéaire multiple
Par opposition au modèle de régression linéaire simple, on définit le modèle de régression linéaire multiple comme tout modèle de régression linéaire avec au moins deux variables explicatives.
Principales hypothèses
Les hypothèses de Gauss-Markov et les hypothèses de normalité garantissent des propriétés particulièrement intéressantes des estimateurs des coefficients de régression[5]. Les hypothèses peuvent s'exprimer différemment selon qu'il s'agisse de la régression linéaire simple ou multiple, ou bien selon que les [Note 1] sont des valeurs constantes (comme une unité de temps par exemple), ou un échantillon des valeurs d'une variable aléatoire.

Non colinéarité des variables explicatives
Cette hypothèse suppose qu'aucune des variables explicatives du modèle ne peut s'écrire comme une combinaison linéaire des autres variables. Ce qui revient à inversible avec xi' la transposée du vecteur xi en notation vectorielle et à inversible avec X' la transposée de la matrice X en notation matricielle. Cette condition est souvent exprimée par le fait que la matrice X est de rang maximum.


Indépendance des erreurs
Les ε1, ε2, ... εn sont indépendants.
Les termes d'erreur ne sont donc pas corrélés entre eux. Formellement, . Cette hypothèse est souvent violée lorsqu'il s'agit de séries temporelles où les erreurs sont souvent dites autocorrélées[15].

Exogénéité
On dit que les variables explicatives sont exogènes si elles ne sont pas corrélées au terme d'erreur. Ce qu'on note, pour le cas où la variable explicative est aléatoire, en notation vectorielle et en notation matricielle où [Note 1]. Ceci implique que les erreurs sont centrées. Si les variables X sont constantes ceci est noté [5].




Homoscédasticité
Les termes d'erreurs sont supposés de variance constante, ce qui se traduit, si l'hypothèse précédente est vérifiée, par si X est une variable aléatoire ou un ensemble de variables aléatoires, et par sinon[5].


Si les deux précédentes hypothèses sont vérifiées, on peut l'écrire sous forme matricielle :

avec In la matrice identité de taille n.
Normalité des termes d'erreur
Une hypothèse plus forte que les premières est celle consistant à dire que les termes d'erreurs suivent une loi normale, centrées, de variance σ2 soit, en notation vectorielle et sous forme matricielle .


Hiérarchie des hypothèses
À noter que si l'hypothèse de non colinéarité n'est pas vérifiée, l'estimation du modèle est impossible (elle nécessiterait d'inverser une matrice singulière) alors que pour toutes les autres hypothèses l'estimation est possible mais donne un estimateur biaisé et/ou non efficace (à variance non minimale) mais il existe des corrections possibles. La normalité des erreurs est quant à elle non obligatoire mais permet de tirer de bonnes propriétés.
Estimation
Le modèle linéaire peut être estimé par la méthode du maximum de vraisemblance, la méthode des moindres carrés, la méthode des moments ou encore par des méthodes bayésiennes[Note 2].
La méthode des moindres carrés est très populaire et très souvent présentée avec le modèle linéaire[Note 3].
Estimateur des moindres carrés
Dans le cas le plus standard, où les termes d'erreurs sont indépendants et identiquement distribués (iid), l'estimateur des moindres carrés ordinaires est le plus efficace des estimateurs linéaires sans biais (théorème de Gauss-Markov).
Lorsque les termes d'erreurs ne sont pas tous de même variance et/ou qu'ils sont corrélés, on utilise la méthode des moindres carrés généralisés ou des moindres carrés quasi-généralisés.
Estimateur des moindres carrés ordinaires
Sous les hypothèses de Gauss et Markov, le modèle peut être estimé par la méthode des moindres carrés ordinaires. L'estimateur des moindres carrés ordinaires peut s'écrire :

sous forme vectorielle ou

sous forme matricielle[13].
D'après le théorème de Gauss-Markov, l'estimateur des moindres carrés ordinaires est le meilleur estimateur linéaire sans biais du vecteur des coefficients β[16],[17].
Sous l'hypothèse de normalité des termes d'erreur, l'estimateur des moindres carrés est aussi l'estimateur du maximum de vraisemblance[18].
Application dans le cas d'un modèle de régression linéaire simple

L'estimateur des moindres carrés ordinaires est la solution du programme de minimisation de la somme des carrés des écarts entre les valeurs prédites et les valeurs observées par rapport aux deux paramètres β0 et β1[19] (β0 est l'ordonnée à l'origine et β1 est la pente de la droite de régression) :

Le problème admet une solution analytique qui s'obtient en remarquant que, la fonction S(β0, β1) étant différentiable, le minimum de S est le point où son gradient s'annule. On a :


avec la moyenne empirique des xi et la moyenne empirique des yi.


On peut également exprimer le résultat de la manière suivante :

Estimation du modèle par les moindres carrés généralisés et quasi-généralisés
Si on note Σ la matrice de variance-covariance du vecteur des perturbations ε, on peut définir l'estimateur des moindres carrés généralisés[20] :

L'estimateur des moindres carrés généralisés suppose que l'on connaisse la matrice de variance-covariance des termes d'erreur. Généralement, cette matrice est inconnue et doit elle-même être estimée. Dans ce cas, on parle alors de l'estimateur des moindres carrés quasi-généralisés.
Qualité de la prédiction
Pour évaluer la qualité de la prédiction, on peut utiliser différents critères.
Dans un premier temps rappelons que :
- est la variation expliquée par la régression (Sum of Squares Explained, en français SCE Somme des Carrés Expliquée [par la régression]).
- est la variation expliquée par les résidus (Sum of Squared Residuals, en français SCR Somme des Carrés Résiduelle).
- est la variation totale (Sum of Squares Total, en français SCT Somme des Carrés Totale).



Nous pouvons alors définir le coefficient de détermination (R2) comme le ratio entre la somme des carrés des écarts à la moyenne des valeurs prédites par la régression et la somme des carrés des écarts à la moyenne totale :

Le coefficient de détermination varie entre 0 et 1. Lorsqu'il est proche de 0, le pouvoir prédictif du modèle est faible et lorsqu'il est proche de 1, le pouvoir prédictif du modèle est fort.
Tests statistiques
Test de Fisher
Le test de Fisher permet de tester la pertinence statistique de toute restriction linéaire sur les coefficients de la régression.

En particulier, le test de Fisher permet de réaliser un test de nullité jointe de l'ensemble des paramètres[21].
Dans ce cas, on teste l'hypothèse

contre l'hypothèse

Dans ce cas, on peut montrer que la statistique de test s'écrit :

La statistique de test F suit une loi de Fisher de paramètres (K, n-K-1).
Test de Student
Le test de Student permet de tester si l'un des paramètres est égal à une valeur précise. En particulier, il permet de tester la nullité de chacun des paramètres.
Test de Chow
Le test de Chow permet de tester la stabilité des coefficients du modèle entre deux sous-échantillons de l'échantillon de données. C'est une application du test de Fisher.
Test d'autocorrélation des termes d'erreur
Le test de Durbin-Watson permet de tester l'autocorrélation des termes d'erreur.
Test d'hétéroscédasticité
Le test de Breusch-Pagan permet de tester l'hypothèse d'homoscédasticité.
Prévision statistique

Le but de la régression est d'établir la loi y = ƒ(x). Une fois cette loi estimée, on va chercher à prédire une valeur de y pour une valeur de x donnée ; on note y* cette valeur estimée,

Il faut donc donner un intervalle de confiance pour cette valeur de y*. On peut donner deux réponses différentes à cette question.
La valeur y* est censée être l'espérance de la variable aléatoire Y(x) en ce point x donné : si l'on fait, disons, 1 000 mesures de Y, la moyenne E(Y(x)) de ces valeurs devrait être y*. On peut donc se demander avec quelle précision ΔE(Y(x)) on estime E(Y(x)). Pour un risque α donné, on peut déterminer l'intervalle dans lequel E(Y(x)) a α % de se trouver est donné par [y* - ΔE(Y(x)) ; y* + ΔE(Y(x))].
Nous avons :

où t est la loi de Student à n - 2 degrés de liberté pour un risque α. Lorsque x varie, les limites de l'intervalle de confiance décrivent une hyperbole.
L'autre question est : à partir d'une seule mesure de Y(x), qui sera différente de y* ; quel est l'intervalle de confiance Δy pour un risque α donné ? On cherche une réponse de la forme : on a α chances que le y mesuré soit dans l'intervalle [y* - Δy ; y* + Δy].
Si x est proche de x, c'est-à-dire si (x - x)2 est négligeable devant ∑(xi - x)2, et si n est grand, c'est-à-dire si 1/n est négligeable devant 1, alors on a un intervalle de confiance

Sous ces hypothèses, on voit que Δy est constant, c'est-à-dire que l'on a une bande de confiance parallèle à la droite de régression.
L'expression exacte est

On voit que cet intervalle augmente lorsque l'on s'éloigne de x. Cela montre en particulier qu'une extrapolation, c'est-à-dire le fait d'utiliser la loi trouvée en dehors du domaine des points expérimentaux [x1 ; xn] (en supposant les abscisses classées par ordre croissant), comporte un risque statistique.
Cas particuliers
Certaines équations ne sont pas directement linéaires mais peuvent être linéarisées. C'est notamment le cas des polynômes. La régression polynomiale est une application d'une régression linéaire au cas particulier d'un polynôme. Ainsi le modèle suivant : est aussi est modèle linéaire et peut être estimé par une méthode standard[22],[Note 4].

On peut aussi calculer des termes d'interactions entre les variables pour relâcher l'hypothèse d'additivité du modèle linéaire. Par exemple, si on pose le modèle suivant : on peut enrichir ce modèle en ajoutant le terme d'interaction entre xi et zi. Le modèle devient alors : Dans ce nouveau modèle, l'effet de la variable xi est d'autant plus fort que la valeur de zi est élevée[23].


Extensions et liens avec d'autres méthodes
Modèle linéaire à variables instrumentales
Si l'hypothèse d'exogénéité des variables explicatives n'est pas vérifiée, l'estimateur des moindres carrés conduit à une estimation biaisée des paramètres du modèle. Dans ce cas, on peut avoir recours à la méthode des variables instrumentales.
On appelle variable instrumentale une variable z qui a un effet sur les variables explicatives suspectées d'endogénéité mais n'est pas corrélée avec le terme d'erreur.
On note souvent le vecteur des variables instrumentales zi et la matrice des variables instrumentales Z.
Le vecteur de variables instrumentales zi est un bon ensemble d'instruments si et seulement si zi est exogène ( et si la matrice est inversible (condition de rang).


Applications
Très souvent utilisé en économétrie, le modèle à variables instrumentales est aussi utilisé en sciences politiques[24].
Estimation
Le modèle linéaire à variables instrumentales peut être estimé par la méthode des doubles moindres carrés, la méthode des moments généralisés, l'estimateur de Wald ou encore par la méthode des fonctions de contrôle.
Méthode des doubles moindres carrés
Ce modèle peut être estimé par la méthode des doubles moindres carrés et dans ce cas, on obtient : [25].
![\hat\beta = [X'Z(Z'Z)^{-1}Z'X]^{-1}[X'Z(Z'Z)^{-1}Z'y]](https://img.franco.wiki/i/fa27eadfebfc6b42888ed6c6994c5f2543e25495.svg)
Modèle linéaire hiérarchique
Le modèle linéaire hiérarchique ou modèle linéaire multiniveau est un modèle dans lequel il y a au moins deux niveaux d'observations, par exemple la région et les individus et dans lequel on va permettre aux coefficients de varier. Par exemple, le modèle suivant est un modèle linéaire hiérarchique : [26].

Régression quantile
Le modèle linéaire standard est une modélisation de l'espérance conditionnelle de la variable d'intérêt yi. On peut aussi modéliser la médiane conditionnelle ou n'importe quel autre quantile de la distribution conditionnelle. C'est le modèle de régression quantile linéaire notamment développé par Roger Koenker[27].
Variables censurées et biais de sélection
- James Tobin a développé le modèle tobit pour traiter les variables censurées.
- James Heckman a développé le modèle de sélection ou modèle Heckit.
Sélection de variables et contraintes sur les coefficients
Dans le cas où le nombre de variables explicatives est élevé (ie légèrement inférieur ou même supérieur au nombre d'observations), il peut être intéressant de sélectionner les variables ou de contraindre les coefficients. Robert Tibshirani a développé la méthode du lasso, une méthode de contraction des coefficients.
Points aberrants
On définit un point aberrant comme une observation pour laquelle l'écart entre la valeur prédite et la valeur observée de la variable d'intérêt est particulièrement élevé. On peut repérer graphiquement les points aberrants sur un nuage de points représentant en abscisses les valeurs prédites et en ordonnées les résidus.
On peut aussi studentiser les résidus en divisant les résidus par leur écart-type. Les observations dont le résidu studentisés est supérieur à 3 peuvent être considérées comme des points aberrants[28].
Méthode médiane-médiane
La méthode médiane-médiane est une méthode développée par John Tukey en 1971 une méthode robuste pour effectuer une régression linéaire. La méthode des moindres carrés utilise le carré de l'écart et est donc très influencée par les points aberrants, alors que la méthode de Tukey utilise des médianes, qui sont, elles, peu influencées par les points aberrants[29].
Liens avec d'autres méthodes
Le modèle linéaire généralisé est une extension du modèle linéaire dans laquelle on pose . Cette classe de modèles comprend le modèle linéaire, le modèle de régression logistique, le modèle probit, le modèle de Poisson, etc. Elle a été développée par Nelder et Wedderburn 1972 et popularisée par le livre de McCullagh et Nelder 1989[30],[31],[32].

Le modèle additif généralisé est un modèle de régression semi-paramétrique qui conserve l'additivité du modèle linéaire sans imposer de contrainte sur la relation entre chacune des variables explicatives et la variable expliquée.
La décomposition de Blinder-Oaxaca est une méthode statistique cherchant à identifier l'effet des caractéristiques observables et des caractéristiques inobservables pour expliquer les différences entre deux groupes (par exemple les différences de salaire entre hommes et femmes). Dans sa version standard, cette méthode s'appuie sur l'estimation d'une régression linéaire.
Variantes
Moindres carrés des écarts d'abscisse
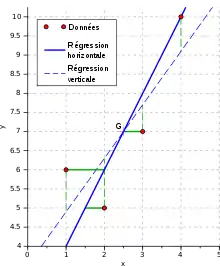
Ci-dessous, nous avons considéré le résidu en ordonnée, le résidu « vertical ». Cette hypothèse est pertinente si les valeurs de x sont connues sans erreur, ou du moins si la variance sur X est plus petite que la variance sur Y.
Dans le cas contraire, on peut considérer le résidu en abscisse, « horizontal ». Le modèle est alors la droite d'équation

On inverse simplement les axes x et y, et on trouve de manière symétrique :

Dans le cas général, cette droite est différente de la précédente. Elle passe également par le centre de gravité.
Si l'on veut se ramener à une équation y = ƒ(x)

il suffit de poser


Régression orthogonale
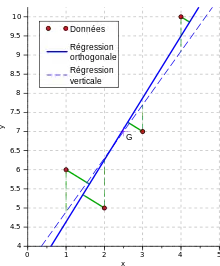
Si les erreurs sur x et sur y sont de même ordre de grandeur, alors il est plus pertinent d'effectuer une « régression orthogonale » ou « régression géométrique » : pour chaque point expérimental i, l'erreur di considérée est la distance du point à la droite modèle, c'est-à-dire la distance prise perpendiculairement à la droite — d'où le terme orthogonal.
On considère toujours la méthode des moindres carrés, que l'on nomme alors « moindre carrés totaux » (MCT) :

On a alors :

L'équation de la droite est donc .
Avec le signe de correspondant au signe de la racine .
(la droite de régression passe encore par le barycentre du nuage de points) avec :




Si l'on impose β0 = 0, on a alors[Note 5]:

Liens avec d'autres notions
Coefficient de corrélation linéaire de Bravais-Pearson
Le minimum de la somme des carrés des résidus vaut :
- .









On a :
- var(X) ≠ 0 ;
- var(Y) ≠ 0 ;
- var(X)var(Y) ≥ cov2(X, Y) le produit des variances est supérieur ou égal au carré de la Covariance.
donc si l'on pose

on a
- -1 ≤ r ≤ 1.
Le paramètre r est appelé coefficient de corrélation. On a alors
- S = n·var(Y)·(1 - r2)
Les variables X et Y sont d'autant mieux corrélées que |r| est proche de 1 ; la somme S est alors proche de 0. Si r = 0, la somme S est maximale et les variables ne sont pas corrélées, c'est-à-dire que le modèle linéaire n'est pas pertinent.
La frontière entre « bonne » et « mauvaise » corrélation, c'est-à-dire la réponse à la question « Le modèle linéaire est-il pertinent ? », n'est pas universelle. Dans un domaine où la mesure est précise et les phénomènes stables, on pourra estimer que les données sont fortement corrélées si |r| ≥ 0,95. Dans des domaines où la mesure est moins précise, et notamment dans les sciences humaines, on se contentera parfois de |r| ≥ 3/4 (soit r2 ≥ 0,56).
Exemples d'applications dans différents domaines
En métrologie
Un certain nombre de phénomènes — physiques, biologiques, économiques… — peuvent se modéliser par une loi affine, de type :

Les paramètres de cette loi, c'est-à-dire les coefficients ai, permettent de caractériser le phénomène. On effectue donc des mesures, c'est-à-dire que l'on détermine des n' + 1-uplets (x1, ..., xn, y).
Une mesure est nécessairement entachée d'erreur. C'est cette erreur qui « crée » le résidu r : chaque n' + 1-uplet j fournit une équation

La régression linéaire permet de déterminer les paramètres du modèle, en réduisant l'influence de l'erreur.
Par exemple, en électricité, un dipôle passif (résisteur) suit la loi d'Ohm :
- ou, pour reprendre la notation précédente,
- ,
- ,




En mesurant plusieurs valeurs de couple (U, I), on peut déterminer la résistance R par régression.
En économie et en économétrie
Le modèle linéaire est très utilisé en économétrie. Il est présenté dans de très nombreux manuels d'économétrie[33].
Dans leur manuel, Colin Cameron et Pravin Trivedi[34] donnent l'exemple de l'évaluation des rendements de l'éducation. On cherche à évaluer l'effet d'une année d'éducation supplémentaire sur le salaire qu'un individu obtient sur le marché du travail. Pour cela, il est courant d'écrire le log du salaire comme une fonction linéaire du nombre d'années d'éducation et d'un certain nombre de facteurs observables ayant une influence potentielle sur le salaire, par exemple le nombre d'années d'expérience sur le marché du travail, le fait d'être une femme, etc. Dans ce cas, le modèle peut alors s'écrire :

avec wi le salaire de l'individu i, educationi le nombre d'années d'éducation de l'individu i, experiencei le nombre d'années d'expérience sur le marché du travail de l'individu i, femmei une variable indicatrice valant 1 si i est une femme et 0 sinon et ui une variable aléatoire représentant l'ensemble des variables non observées dans les données pouvant expliquer le salaire de l'individu i[35]. On trouve de nombreux exemples dans la littérature économique :
- En économie de l'éducation, Joshua Angrist et Victor Lavy utilisent un modèle linéaire pour estimer l'effet causal de la taille des classes sur les performances scolaires des élèves[36].
- Gregory Mankiw, David Romer et David Weil utilisent un modèle linéaire pour tester empiriquement la pertinence du modèle de Solow[37].
- Steven Levitt utilise un modèle linéaire pour estimer l'effet du nombre de policiers sur la criminalité[38].
- Daron Acemoglu, Simon Johnson et James Robinson utilisent une régression linéaire pour estimer l'effet des institutions sur le développement actuel des pays[39].
- Jonathan Gruber et Daniel Hungerman utilisent un modèle linéaire pour analyser sur données américaines l'effet des lois autorisant le travail le dimanche sur la participation religieuse[40].
En sciences politiques
Andrew Gelman et Gary King utilisent un modèle linéaire pour estimer l'avantage des candidats sortants lors des élections à la chambre des représentants des États-Unis[41].
En France, l'analyse des scrutins de 1993 et 1997 au niveau national et au niveau local par Jean Chiche, utilisant la régression linéaire, montre que l'effet balancier droite modérée - PS n'est pas clairement établi contrairement à ce que pouvaient laisser penser les résultats. Des transferts de voix de la gauche modérée vers le PC, et de la droite modérée vers l'extrême droite (et réciproquement) ont eu lieu[42].
De même Bernard Dolez explique le scrutin européen de 1999 en utilisant plusieurs fois la régression linéaire multiple[43].
En sociologie
La structure sociale européenne est analysée, par exemple, à l'aide de la régression linéaire entre l'écart type du niveau de revenu et celui du niveau d'éducation[44].
Patrick Peretti-Watel utilise la régression linéaire pour évaluer l'estime de soi en fonction du niveau de consommation de cannabis, de l'âge et du sexe [45].
Alain Degenne, Marie-Odile Lebeaux, et Catherine Marry, emploient la régression linéaire multiple[46].
En psychologie
Philippe Guimard, Olivier Cosnefroy et Agnès Florin analysent l'évaluation des élèves de l'école primaire par les enseignants en exploitant le modèle linéaire en vue d'apprécier le pouvoir prédictif de ces évaluations[47].
En géographie
L'étude de la pluviométrie en fonction de l'altitude dans les Alpes du Nord effectuée par C. Castellani montre les relations linéaires existantes entre ces deux grandeurs sur des sites différents[48]. Nicole Commerçon exploite plusieurs fois le modèle linéaire pour décrire la présence des résidences secondaires dans le Mâconnais[49].
En géostatistique, Yann Richard et Christine Tobelem Zanin, utilisent la régression linéaire multiple pour décrire la régionalisation des échanges entre la Russie et l'Union européenne[50].
En mécanique
Une pièce réelle comporte forcément des défauts par rapport au plan, sa version idéale. Or, la rectitude et l'orientation d'une arête, la planéité et l'orientation d'une face peuvent être importantes, par exemple s'il s'agit de contacts avec d'autres pièces.
Pour quantifier les défauts, on peut faire un relevé de points par la méthode dite de la métrologie par coordonnées. On obtient donc un ensemble de coordonnées (xi, yi, zi). Ces coordonnées peuvent aussi provenir d'un calcul de déformation par éléments finis : on a une structure supposée parfaite qui se déforme de manière élastique sous l'effet de charges, et l'on veut vérifier que cette déformation reste compatible avec la fonction de la structure.
Pour une arête, une régression linéaire permet d'obtenir la direction moyenne d'une arête, et donc de vérifier si cette direction est suffisamment proche de la direction idéale, et de quantifier les écarts de rectitude. De même, pour une face, une régression linéaire permet de déterminer le plan moyen, et donc de vérifier si son orientation est suffisamment proche de l'orientation idéale, et de quantifier l'état de surface (RA).
Application à des modèles non linéaires
Dans certains cas, on peut utiliser la régression linéaire pour ajuster un modèle non linéaire en effectuant un changement de variable. Par exemple, si l'on a un modèle parabolique

il suffit de considérer et de faire la régression sur (x', y). Par exemple, lorsque l'on s'intéresse à l'oxydation à haute température d'un métal formant un oxyde protecteur, une étude théorique prédit que la prise de masse a un comportement parabolique en fonction du temps (loi d'oxydation de Wagner), Δm α √t. On peut mesurer cette prise de masse par thermogravimétrie, mais le système qui mesure de très faibles variations de masse (de l'ordre du microgramme) est très sensible aux perturbations, ce qui génère du bruit. La régression linéaire avec x = √t et y = Δm permet de caractériser la cinétique d'oxydation.

De fait, pour une loi de puissance en x — c'est-à-dire sous la forme y α xn où n est un nombre réel —, on peut poser x' = xn. Et de manière encore plus générale, si le modèle fait intervenir une fonction ƒ élémentaire dans une formule affine
- y = a + b·ƒ(x)
on peut alors faire le changement de variable x' = ƒ(x) pour avoir une relation affine
- y = a + b·x'.
On peut parfois linéariser la relation en se plaçant en diagramme logarithmique :
- si y = axn, alors ln(y) = ln(a) + n·ln(x)
donc le changement de variable x' = ln(x) et y' = ln(y) donne une relation affine
- y' = a' + n·x'.
La transformation peut être plus complexe. Par exemple, si une variable aléatoire suit une loi normale, on peut déterminer les paramètres de la loi par régression linéaire par la méthode de la droite de Henry.
Si une variable aléatoire suit une loi de Weibull, alors on peut se ramener à un diagramme linéaire à partir de relevés de probabilités y = P(x)[Note 6] :
- en considérant les probabilités cumulées : la fonction de répartition vaut ;
- en effectuant le changement de variable x' = ln(x) et y' = ln(-ln(1 - F)), on a alors ;


la régression linéaire permet alors de déterminer les valeurs de k et de λ.
Dans certains cas, on peut linéariser en se plaçant dans un espace de dimension supérieur. Si l'on est dans un espace à deux dimensions (x, y) et que l'on veut ajuster un modèle polynomial de degré n,
- ƒa0, a1, …, an(x) = a0 + a1x + … + anxn
on peut définir les variables
- xi = xi
et effectuer une régression avec le modèle linéaire, la variable explicative étant le vecteur (x1, …, xn) :
- ga0, a1, …, an(x1, …, xn) = a0 + a1x1 + … + anxn.
Dans le même ordre d'idées, si le modèle est un cercle, d'équation cartésienne
- (x - xc)2 + (y - yc)2 = r2 ;
on peut définir les variables
- y1 = x2 + y2 ;
- x1 = x ;
- x2 = y ;
et effectuer une régression avec le modèle linéaire, la variable expliquée étant y1 et la variable explicative étant le vecteur (x1, x2) :
- ƒa0, a1, a2(x1, x2) = a0 + a1x1 + a2x2
et déduire xc, yc et r de
- a1 = 2xc ;
- a2 = 2yc ;
- a0 = r2 - xc2 - yc2.
Bien que l'on ait effectué une régression par la méthode des moindres carrés dans l'espace (x1, x2, y1), on n'a pas le résultat que l'on obtiendrait avec une régression par la méthode des moindres carrés dans l'expace (x, y).
Considérons maintenant des positions relevées sur une sphère ; il peut s'agir de localisations géographiques, mais un point d'une sphère de référence (centrée sur l'origine du repère et de rayon 1) peut aussi servir à représenter une orientation (voir Coordonnées sphériques > Utilisation). Une régression sur ces points n'est évidemment pas linéaire.
En projection gnomonique, un grand cercle (orthodromie) est représenté par une droite. Si l'on veut trouver la « meilleure orthodromie » pour un jeu de points — par exemple trouver l'orbite d'un satellite devant survoler au plus près un ensemble de sites —, on peut donc effectuer une régression linéaire sur la représentation gnomonique[51].
Notes et références
Notes
- 1 2 K variant de 1 à p, ce qui permet d'inclure le cas de la régression simple.
- ↑ Pour les méthodes bayésiennes, voir l'article anglophone en:Bayesian linear regression
- ↑ Par exemple, James et al. 2013
- ↑ Le modèle est dit linéaire tant qu'il est linéaire dans les paramètres .
- ↑ Voir cette démonstration de MathWorld
- ↑ la loi a une densité de probabilité continue, mais les valeurs sont nécessairement relevées de manière discrète

Références
- ↑ (en) Charles Manski, « Regression », Journal of Economic Literature, vol. 29, no 1, , p. 34-50 (JSTOR 2727353)
- ↑ (en) Michael Friendly et al., HistData : Data sets from the history of statistics and data, (lire en ligne)
- 1 2 3 4 Dodge 2010, p. 451-452
- ↑ Adrien-Marie Legendre, Nouvelles méthodes pour la détermination des orbites des comètes, Paris, F. Didot, , 80 p. (lire en ligne), viii
- 1 2 3 4 Dodge 2010, p. 217
- ↑ (en) Francis Galton, « Regression Towards Mediocrity in Hereditary Stature », Journal of the Anthropological Institute, vol. 15, , p. 246-263 (lire en ligne, consulté le )
- ↑ R Palm et A.F. Iemma, « Quelques alternatives à la régression classique dans le cadre de la colinéarité », Revue de statistique appliquée, vol. 43, no 2, , p. 5-33 (lire en ligne)
- ↑ (en) Robert Tibshirani, « Regression shrinkage and selection via the lasso », Journal of the Royal Statistical Society, vol. 58, no 1, , p. 267-288 (lire en ligne)
- ↑ Thierry Foucart, « Colinéarité et régression linéaire », Mathématiques et sciences humaines, vol. 1, no 173, , p. 5-25 (lire en ligne)
- ↑ James et al. 2013, p. 59
- ↑ Voir par exemple Gelman et Hill 2006, p. 37
- ↑ Cameron et Trivedi 2005, p. 70
- 1 2 Cameron et Trivedi 2005, p. 71
- ↑ Wasserman 2004, p. 210, définition 13.2
- ↑ (en) Alan Krueger, « Symposium on Econometric Tools », The Journal of Economic Perspectives, vol. 15, no 4, , p. 3-10 (JSTOR 2696512)
- ↑ Wasserman 2004, Chapitre 13
- ↑ Gelman et Hill 2006, p. 40
- ↑ Wasserman 2004, p. 213, théorème 13.7
- ↑ Wasserman 2004, p. 211, définition 13.3
- ↑ Cameron et Trivedi 2005, p. 82, équation 4.28
- ↑ James et al. 2013, p. 75
- ↑ James et al. 2013, p. 91
- ↑ James et al. 2013, p. 87
- ↑ (en) Allison Sovey et Donald Green, « Instrumental Variables Estimation in Political Science: A Readers’ Guide », American Journal of Political Science, vol. 55, no 1, , p. 188-200
- ↑ Cameron et Trivedi 2005, p. 101, équation 4.53
- ↑ Gelman et Hill 2006, p. 1
- ↑ Cameron et Trivedi 2005, p. 85
- ↑ James et al. 2013, p. 97
- ↑ (en) Elizabeth J. Walters, Christopher H. Morrell et Richard E. Auer, « An Investigation of the Median-Median Method of Linear Regression », Journal of Statistics Education, vol. 14, no 2, (lire en ligne)
- ↑ (en) John Nelder et Wedderburn, « Generalized linear models », Journal of the Royal Statistical Society Series A, vol. 135, , p. 370–384
- ↑ (en) Peter McCullagh et John Nelder, Generalized linear models, Londres, Chapman & Hall,
- ↑ (en) Daniel Wright, « Ten Statisticians and Their Impacts for Psychologists », Perspectives on psychological science, vol. 4, no 6, , p. 587-597 (lire en ligne, consulté le )
- ↑ Cameron et Trivedi 2005, Angrist et Pischke 2008, Dormont 2007, Mignon 2008...
- ↑ P. K. Trivedi, Microeconometrics : methods and applications, (ISBN 978-0-521-84805-3, 0-521-84805-9 et 9786610202966, OCLC 56599620, lire en ligne)
- ↑ Cameron et Trivedi 2005, p. 69
- ↑ (en) Joshua Angrist et Victor Lavy, « Using Maimonides' Rule to Estimate the Effect of Class Size on Scholastic Achievement », The Quarterly Journal of Economics, vol. 114, no 2, , p. 533-575 (lire en ligne, consulté le )
- ↑ (en) Gregory Mankiw, David Romer et David Weil, « A Contribution to the Empirics of Economic Growth », Quarterly Journal of Economics, vol. 107, no 2, , p. 407-437
- ↑ (en) Steven Levitt, « Using electoral cycles in police hiring to estimate the effect of police on crime », American Economic Review, vol. 87, no 3, , p. 270-290 (JSTOR 2951346)
- ↑ (en) Daron Acemoglu, Simon Johnson et James Robinson, « Reversal of Fortune: Geography and Institutions in the Making of the Modern World Income Distribution », Quarterly Journal of Economics, vol. 117, no 4, , p. 1231-1294
- ↑ (en) Jonathan Gruber et Daniel Hungerman, « The Church versus the Mall : What happens when religion faces increased secular competition ? », The Quarterly Journal of Economics, vol. 123, no 2, , p. 831-862 (lire en ligne, consulté le )
- ↑ (en) Andrew Gelman et Gary King, « Estimating incumbency advantage without bias », American Journal of Political Science, vol. 34, no 4, , p. 1142-1164 (lire en ligne, consulté le )
- ↑ Jean Chiche, « Des évolutions électorales entre logique nationale et cultures politiques régionales », Revue française de science politique, vol. 47, nos 3-4, , p. 416-425 (DOI 10.3406/rfsp.1997.395186, lire en ligne)
- ↑ Bernard Dolez, « La liste Bayrou ou la résurgence du courant démocrate-chrétien », Revue française de science politique, vol. 49, nos 4-5, , p. 663-674 (DOI 10.3406/rfsp.1999.396252, lire en ligne)
- ↑ Louis Chauvel, « Existe-t-il un modèle européen de structure sociale », Revue de l'OFCE, vol. 71, , p. 281-298 (DOI 10.3406/ofce.1999.1562, lire en ligne)
- ↑ Patrick Peretti-Watel, « Comment devient-on fumeur de cannabis ? Une perspective quantitative », Revue française de sociologie, vol. 42, no 1, , p. 3-30 (DOI 10.2307/3322802, lire en ligne)
- ↑ Alain Degenne, Marie-Odile Lebeaux et Catherine Marry, « Les usages du temps : cumuls d'activités et rythmes de vie : Temps sociaux et temps professionnels au travers des enquêtes Emploi du temps », Economie et statistique, nos 352-353, , p. 81-99 (DOI 10.3406/estat.2002.7394, lire en ligne)
- ↑ Philippe Guimard, Olivier Cosnefroy et Agnès Florin, « Évaluation des comportements et des compétences scolaires par les enseignants et prédiction des performances et des parcours à l’école élémentaire et au collège », L'orientation scolaire et professionnelle, nos 36/2, , p. 179-202 (lire en ligne)
- ↑ C. Castellani, « Régionalisation des précipitations annuelles par la méthode de la régression linéaire simple : l'exemple des Alpes du Nord », Revue de géographie alpine, vol. 74, no 4, , p. 393-403 (DOI 10.3406/rga.1986.2658, lire en ligne)
- ↑ Nicole Commerçon, « Les résidences secondaires du Mâconnais : essai d'étude quantitative », Revue de géographie de Lyon, vol. 48, no 4, , p. 331-342 (DOI 10.3406/geoca.1973.1632, lire en ligne)
- ↑ Yann Richard et Christine Tobelem Zanin, « La Russie et l’Europe : une intégration économique encore à venir ? », Cybergeo : European Journal of Geography, (DOI 10.4000/cybergeo.11113, lire en ligne)
- ↑ Droite des moindres carrés, Robert Mellet
Bibliographie
Textes historiques
- (en) Francis Galton, « Regression Towards Mediocrity in Hereditary Stature », Journal of the Anthropological Institute, vol. 15, , p. 246-263 (lire en ligne, consulté le )
Sources
- Michel Armatte, Histoire du modèle linéaire. Formes et usages en statistique et en économétrie jusqu’en 1945, 1995, thèse EHESS sous la direction de Jacques Mairesse.
- (en) E.H. Lehmann, « On the history and use of some standard statistical models », dans Deborah Nolan et Terry Speed, Probability and Statistics: Essays in Honor of David A. Freedman, Beachwood, Ohio, USA, Institute of Mathematical Statistics, (lire en ligne)
Manuels
- (en) Gareth James, Daniela Witten, Trevor Hastie et Robert Tibshirani, An Introduction to Statistical Learning, Springer Verlag, coll. « Springer Texts in Statistics », (DOI 10.1007/978-1-4614-7138-7)
- Régis Bourbonnais, Économétrie, Dunod, 10ème Edt., 2018
- (en) Trevor Hastie, Robert Tibshirani et Jerome Friedman, The Elements of Statistical Learning : Data Mining, Inference, and Prediction, , 2e éd. (1re éd. 2001)
- (en) Joshua Angrist et Jörn-Steffen Pischke, Mostly Harmless Econometrics : An Empiricist's Companion, Princeton University Press, , 1re éd., 392 p. (ISBN 978-0-691-12035-5)

- (en) Colin Cameron et Pravin Trivedi, Microeconometrics : Methods And Applications, Cambridge University Press, , 1056 p. (ISBN 978-0-521-84805-3, lire en ligne)
- Pierre-André Cornillon et Eric Matzner-Løber, Régression : Théorie et applications, Paris/Berlin/Heidelberg etc., Springer, , 1re éd., 302 p. (ISBN 978-2-287-39692-2)
- Bruno Crépon et Nicolas Jacquemet, Économétrie : Méthode et Applications, Bruxelles/Paris, De Boeck Université, coll. « Ouvertures économiques », , 1re éd., 416 p. (ISBN 978-2-8041-5323-6)
- (en) Yadolah Dodge, The Concise Encyclopaedia of Statistics, New York, Springer, , 622 p. (ISBN 978-0-387-31742-7, lire en ligne)
- Brigitte Dormont, Introduction à l'économétrie, Paris, Montchrestien, , 2e éd., 518 p. (ISBN 978-2-7076-1398-1)
- (en) Andrew Gelman et Jennifer Hill, Data Analysis Using Regression And Multilevel/Hierarchical Models, Cambridge University Press, coll. « Analytical Methods for Social Research », , 1re éd., 648 p. (ISBN 978-0-521-68689-1, lire en ligne)
- Valérie Mignon, Économétrie, Economica, coll. « Corpus économie », , 1re éd.
- (en) Larry Wasserman, All of Statistics : A Concise Course in Statistical Inference, New York, Springer-Verlag, , 461 p. (ISBN 978-0-387-40272-7, lire en ligne)
Voir aussi
Articles connexes
- Linéarité
- Corrélation (mathématiques)
- Poursuite de base
- Régression (statistiques)
- Régression multilinéaire
- Régression non linéaire
- Test de Breusch-Pagan, test d'homoscédasticité des résidus
- Test de Chow, test de stabilité temporelle
- Test de Durbin-Watson, test d'autocorrélation des résidus dans le modèle linéaire
- Quartet d'Anscombe : expérience montrant quatre jeux de données pour lesquels les coefficients de la régression linéaire sont identiques alors que les données sous-jacentes sont très différentes.
- Théorème de Frisch-Waugh
Liens externes
- (fr) Philippe Besse, Pratique de la régression linéaire,
- (fr) Thierry Verdel et coll., La régression linéaire, cours de l'École des Mines de Nancy