En mathématiques, l’écart type (aussi orthographié écart-type) est une mesure de la dispersion des valeurs d'un échantillon statistique ou d'une distribution de probabilité. Il est défini comme la racine carrée de la variance ou, de manière équivalente, comme la moyenne quadratique des écarts par rapport à la moyenne. Il se note en général avec la lettre grecque σ (« sigma »), d’après l’appellation standard deviation en anglais. Il est homogène à la variable mesurée.
Les écarts types sont rencontrés dans tous les domaines où sont appliquées les probabilités et la statistique, en particulier dans le domaine des sondages, en physique, en biologie ou dans la finance. Ils permettent en général de synthétiser les résultats numériques d'une expérience répétée. Tant en probabilités qu'en statistique, il sert à l'expression d'autres notions importantes comme le coefficient de corrélation, le coefficient de variation ou la répartition optimale de Neyman.
Quand l'écart type d'une population est inconnu, sa valeur est approchée à l'aide d'estimateurs.
Exemples
- Population de personnes de même taille
On considère une population de 4 personnes mesurant 2 m. La moyenne des tailles est de 2 m. Chaque valeur étant égale à la moyenne, l'écart type est de 0 m.
- Population de personnes de tailles différentes
On considère maintenant une population de 4 personnes de taille 2 m, 1,80 m, 2,20 m et 2 m. La moyenne est aussi de . Les écarts par rapport à la moyenne sont maintenant de 0 m, 0,20 m, 0,20 m et 0 m, respectivement. Ainsi l'écart type est la moyenne quadratique de ces écarts, c'est-à-dire , qui vaut environ 0,14 m.


Histoire
L'écart type est une grandeur dont l'invention remonte au XIXe siècle, qui voit la statistique se développer au Royaume-Uni.
C'est à Abraham de Moivre qu'est attribuée la découverte du concept de mesure de la dispersion qui apparaît dans son ouvrage The Doctrine of Chances en 1718[b 1]. Mais le terme d'écart type (« standard deviation ») a été employé pour la première fois par Karl Pearson en 1893 devant la Royal Society[b 2]. C'est aussi Karl Pearson qui utilise pour la première fois le symbole σ pour représenter l'écart type[b 2]. En 1908, William Gosset, plus connu sous le pseudonyme de Student, définit l'écart type empirique d'un échantillon et montre qu'il est important de le distinguer de l'écart type d'une population[b 2]. La variance est une notion qui apparut plus tard, en 1918, dans un texte de Ronald Fisher intitulé The Correlation between Relatives on the Supposition of Mendelian Inheritance[i 1].
Sur population totale
Définition
À partir d'un relevé exhaustif (x1, ..., xn) d'une variable quantitative pour tous les individus d'une population, l'écart type est la racine carrée de la variance, c'est-à-dire[b 3],[1],[2] :

où représente la moyenne. L'écart type est homogène à la variable mesurée, c'est-à-dire que si par un changement d'unité, toutes les valeurs sont multipliées par un coefficient α > 0, l'écart type sera multiplié par le même coefficient. En revanche, l'écart type est invariant par décalage additif : si on ajoute une constante à toutes les valeurs relevées, cela ne change pas l'écart type. Ces deux propriétés font de l'écart type un indicateur de dispersion.

Par contraste avec d'autres indicateurs de dispersion comme l'écart interquartile, l'écart type a l'avantage de pouvoir se calculer à partir des moyennes et écarts types sur une partition de la population, puisque la variance globale est la somme de la variance des moyennes et de la moyenne des variances. Cela permet de calculer l'écart type en parallèle.
L'écart type est implémenté en Python dans la bibliothèque numpy avec la méthode std. En R, la fonction sd utilise à la place de [3], ce qui correspond à l'estimateur de l'écart-type d'une population à partir d'un échantillon.


Expression comme distance
L'écart type est la distance euclidienne du point de coordonnées à la droite diagonale engendrée par le vecteur dans , atteinte en son projeté orthogonal de coordonnées .





L'écart type est donc le minimum de la fonction qui calcule la distance entre M et le point de coordonnées (t, ..., t).

Coefficient de variation
L'écart type peut être utilisé pour comparer l'homogénéité de plusieurs populations sur une même variable. Par exemple, si on donne deux classes d'un même niveau moyen et évaluées selon les mêmes critères, la classe avec un plus fort écart type des notes sera plus hétérogène. Dans le cas d'une notation de à , l'écart type minimal est (notes toutes identiques), et peut valoir jusqu'à si la moitié de la classe à et l'autre moitié [Note 1].





En revanche, on ne peut comparer tels quels les écarts types de variables différentes, et dont les ordres de grandeur ne correspondent pas nécessairement. Pour une variable quantitative strictement positive, on définit alors le coefficient de variation, égal au quotient de l'écart type par la moyenne[b 4]. Ce nombre adimensionnel ne dépend pas de l'unité de mesure choisie et permet de comparer la dispersion de variables différentes.
Un coefficient de variation élevé peut éventuellement signaler l'existence d'une valeur aberrante. Un critère consiste à rejeter les valeurs qui diffèrent de la moyenne par plus de 3 fois l'écart type. Dans le cas d'une distribution gaussienne, la probabilité d'un tel dépassement[b 5] est de l'ordre de 3/1000.
Pour une variable aléatoire
Définition
La modélisation probabiliste d'une distribution statistique consiste à définir une variable aléatoire, c'est-à-dire une application X avec une mesure de probabilité , laquelle permet de définir les probabilités de la forme . La donnée de ces probabilités constitue la loi de probabilité[b 6] de X. La modélisation est fidèle si la probabilité d'un évènement correspond à la fréquence d'occurrence des valeurs correspondantes dans la population testée, conformément à la loi des grands nombres.


On s'intéresse ici aux variables aléatoires réelles ou vectorielles de carré intégrable, c'est-à-dire dont l'espérance E(X2) converge. Pour une variable vectorielle (à valeurs dans un espace vectoriel normé complet), l'espérance est un vecteur du même espace et le carré désigne le carré de la norme. L'ensemble de ces variables est lui-même un espace vectoriel.

L'écart type de X est la racine carrée de la variance[Note 2],[i 2] .
![{\displaystyle \sigma (X)={\sqrt {\mathbb {E} \left[\left(X-\mathbb {E} [X]\right)^{2}\right]}}={\sqrt {\mathbb {E} [X^{2}]-\mathbb {E} [X]^{2}}}}](https://img.franco.wiki/i/f01de40bd18b7adf744f333ad3789b1699441607.svg)
L'existence de l'écart type est assurée pour une variable aléatoire bornée ou admettant une fonction de densité dominée à l'infini par une fonction puissance avec α > 3.

Exemples
Dans le cas d'une variable aléatoire discrète dont les valeurs sont notées xi, avec , l'écart type s'écrit comme pour une série statistique , où μ est l'espérance de la loi de X.


En particulier, si X est uniforme[b 7] sur un ensemble fini , c'est-à-dire si

- pour tout i entre 1 et n,

alors
- .

Dans le cas d'une variable aléatoire à densité pour laquelle les probabilités s'écrivent où f est une fonction localement intégrable, pour la mesure de Lebesgue par exemple, mais pas nécessairement une fonction continue[b 8], l'écart type de X est défini par où est l'espérance de X.
![{\mathbb P}_{X}\left(]a,b[\right)={\mathbb P}\left(X\in ]a,b[\right)=\int _{a}^{b}f(x)\,{\mathrm {d}}x](https://img.franco.wiki/i/caa539224f7b8c69684177d38a80619c7f950ecc.svg)


Avec ces formules et la définition, le calcul des écarts types pour les lois couramment rencontrées est aisé. Le tableau suivant donne les écarts types de quelques-unes de ces lois :
| Nom de la loi | Paramètre(s) | Description | Écart type |
|---|---|---|---|
| Loi de Bernoulli[b 7] | p ∈ ]0 ; 1[ | Loi discrète sur {0 ; 1} avec une probabilité p d'obtenir 1 | |
| Loi binomiale[b 9] | et p ∈ ]0 ; 1[ | Loi de la somme de n variables indépendantes suivant la loi de Bernoulli de même paramètre p | |
| Loi géométrique[b 10] | p ∈ ]0 ; 1[ | Loi du rang de la première réalisation dans une suite de variables de Bernoulli indépendantes de même paramètre p | |
| Loi uniforme sur un segment[b 11] | a < b | Loi de densité constante sur[a , b] | |
| Loi exponentielle[b 11] | Loi à densité avec un taux de panne constant λ | ||
| Loi de Poisson[b 12] | Loi sur du nombre de réalisations indépendantes sur de moyenne λ | ||
| Loi du χ²[b 13] | n | Loi de la somme de n carrés de variables normales centrées réduites indépendantes | |










Si la variable X suit une loi log-normale alors ln X suit une loi normale et l'écart type de X est relié à l'écart type géométrique[b 14].
Mais toutes les lois de probabilité n'admettent pas forcément un écart type fini : la loi de Cauchy (ou loi de Lorentz) n'a pas d'écart type, ni même d'espérance mathématique[b 15].
Propriétés
- Positivité
- L'écart type est toujours positif ou nul. Celui d'une constante est nul.
- Invariance par translation
- L'écart type ne change pas si on ajoute une constante b à la variable aléatoire X : σX+b=σX.
- Homogénéité[Note 3],[b 16]
- Pour toute constante positive c et toute variable aléatoire réelle X, on a σcX = c σX.
- Somme algébrique de deux variables
- L'écart type de la somme de deux variables s'écrit[b 17] sous la forme

où ρ(X,Y) est le coefficient de corrélation entre les deux variables X et Y.
- Inégalité triangulaire
- L'écart type de la somme est majoré par la somme des écarts types[Note 4] :
- .
- De plus, il y a égalité si et seulement s'il existe une relation affine presque sûre entre les deux variables.
- Distance euclidienne
- L'écart type d'une variable aléatoire réelle X est la distance euclidienne de cette variable à la droite des constantes dans l'espace des variables admettant une variance[b 18]. C'est donc le minimum de la fonction , atteint sur la constante c = E(X).


Usages
Intervalle de fluctuation
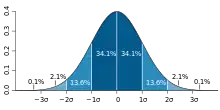
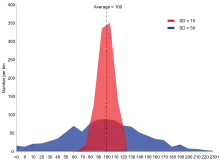
En sciences, il est fréquent de considérer que les mesures d'une grandeur se répartissent selon une distribution gaussienne, par accumulation d'erreurs de mesure ou d'interférences indépendantes avec d'autres phénomènes, en application du théorème central limite. L'histogramme des valeurs observées se rapproche alors d'une courbe en cloche caractéristique de la loi normale. La courbe étant complètement définie par la donnée de la valeur moyenne et de l'écart type, ces deux valeurs permettent de définir un intervalle de fluctuation qui concentre l'essentiel des observations.
Le calcul des quantiles de cette loi montre par exemple que pour une grandeur satisfaisant cette distribution sur une population d'individus, avec une moyenne m et un écart type σ, 95 % des valeurs observées appartiendront à l'intervalle [m – 1,96 σ ; m + 1,96 σ] (voir 97,5ème centile). On peut ainsi associer des probabilités à des intervalles de valeurs centrés sur la moyenne et dont l'amplitude est un multiple de l'écart type[b 19].
| Écart maximal à la moyenne | Proportion des valeurs |
|---|---|
| 68,27 % | |
| 95 % | |
| 95,45 % | |
| 99,73 % |




Dans l'industrie, l'écart type intervient dans le calcul de l'indice de qualité des produits manufacturés ou dans l'indice de fidélité d'un appareil de mesure[i 3],[i 4].
En physique des particules, la détection d'évènements est ainsi quantifiée en nombre de sigmas, représentant l'écart entre la valeur observée et la moyenne attendue en l'absence d'évènement. Un résultat est considéré comme significatif par l'obtention de 5 sigmas, représentant une probabilité d'erreur inférieure à 0,00006 % (soit niveau de confiance de plus de 99,99994 %)[i 5].

Dans le domaine de la communication financière, l'écart type est une mesure de la volatilité des cours des actions des sociétés cotées[b 20]. Les bandes de Bollinger sont des outils facilitant l'analyse des prévisions boursières. John Bollinger a construit la courbe des moyennes mobiles sur 20 jours et les courbes, de part et d'autre de cette courbe, situées à deux fois l'écart type sur ces 20 jours. John Bollinger a utilisé une définition adaptée de l'écart type[i 6]. En outre, le risque d'un actif boursier et le risque associé au marché sont mesurés par l'écart type de la rentabilité attendue, dans le modèle d'évaluation des actifs financiers de Harry Markowitz[i 7].
Variable centrée réduite
.svg.png.webp)
Si X est une variable aléatoire d'écart type non nul, on peut lui faire correspondre la variable centrée et réduite Z définie par . Deux variables aléatoires centrées et réduites Z1 et Z2 sont aisées à comparer, puisque E(Zi)=0 et σZi=1[b 21].

Le théorème central limite a pour objet la limite d'une suite de variables aléatoires centrées réduites[b 22], les coefficients de dissymétrie et d'aplatissement d'une densité de probabilité, E(Z3) et E(Z4), permettent de comparer des distributions différentes[b 23].
Coefficient de corrélation linéaire
Si X et Y sont deux variables aléatoires réelles admettant toutes les deux une variance non nulle, le coefficient de corrélation linéaire est le rapport où est la covariance des variables X et Y. D'après l'inégalité de Cauchy-Schwarz, ; le coefficient de corrélation prend ses valeurs dans l'intervalle [–1 ; +1][b 24].

![{\displaystyle \operatorname {Cov} (X,Y)=\mathbb {E} [(X-\mathbb {E} [X])\,(Y-\mathbb {E} [Y])]=\mathbb {E} [XY]-\mathbb {E} [X]\mathbb {E} [Y]}](https://img.franco.wiki/i/abbe41e3dbb8da2a6cb6d538c605a373b1140b12.svg)

Si les deux variables sont indépendantes, le coefficient de corrélation linéaire est nul, mais la réciproque est fausse.
Si le coefficient de corrélation linéaire vaut 1 ou −1, les deux variables sont presque sûrement en relation affine[b 25].
Inégalité de Bienaymé-Tchebychev
C'est grâce à l'inégalité de Bienaymé-Tchebychev que l'écart type apparaît comme une mesure de la dispersion autour de la moyenne. En effet, cette inégalité exprime que [b 26] et montre que la probabilité pour que X s'écarte de E(X) de plus de k fois l'écart type est inférieure à 1/k2[b 27].

Principe d'incertitude
En mécanique quantique, le principe d'incertitude d'Heisenberg exprime que le produit des écarts types de la position x et de l'impulsion p d'une particule est supérieur ou égal à la constante de Planck réduite divisée par deux, soit [i 8].

Estimation
Lorsqu'il n'est pas possible de connaître toutes les valeurs de la caractéristique considérée, on se trouve dans le cadre de la théorie statistique. Le statisticien procède alors par échantillonnage et estimation pour évaluer les grandeurs analysées telles que l'écart type.

Un estimateur est une fonction permettant d'approcher un paramètre d'une population à l'aide d'un échantillon tiré au hasard[b 28], ou une grandeur sur un phénomène aléatoire à partir de plusieurs réalisations de celui-ci.
Dans le cas d'un échantillon de taille n, et dont la vraie moyenne -ou espérance- μ est connue, l'estimateur est le suivant :

Malheureusement, le plus souvent on ne connaît pas μ et on doit l'estimer à partir de l'échantillon lui-même grâce à l'estimateur suivant : . Différents estimateurs de l'écart type sont généralement utilisés. La plupart de ces estimateurs s'expriment par la formule :


Sn – 1 (ou S′ ) est l'estimateur le plus utilisé[b 29] - [b 3], mais certains auteurs recommandent d'utiliser Sn (ou S)[i 9].
Propriétés des estimateurs
Deux propriétés importantes des estimateurs sont la convergence et l'absence de biais[b 3].
Pour tout k tel que k/n tende vers 1, la loi des grands nombres garantit que S2
n puis S2
k sont des estimateurs convergents de σ2. Grâce au théorème de continuité, stipulant que si f est continue, alors . La fonction racine carrée étant continue, Sk converge lui aussi vers σ. En particulier Sn et Sn – 1 sont des estimateurs convergents de σ, ce qui reflète l'approximation de σ par ces deux séries lorsque n devient de plus en plus grand[Note 5],[b 30] et conforte le statisticien à utiliser ces estimateurs.

L'estimateur de la variance S2
n – 1 est sans biais. Cependant, la non-linéarité de la fonction racine carrée fait que Sn – 1 est légèrement biaisé[i 9]. Les estimateurs S2
n et Sn sont eux aussi biaisés. Le fait de faire intervenir non pas n mais n – 1 au dénominateur (correction de Bessel) dans le calcul de la variance vient du fait que déterminer la moyenne de x à partir de l'échantillon fait perdre un degré de liberté puisque la formule relie aux valeurs xi. On a donc seulement n – 1 valeurs indépendantes après le calcul de . Dans le cas ou l'on cherche à estimer l’écart-type d'une loi normale, on dispose d'un estimateur non biaisé de σ proche de [i 10]. Le choix de permet de corriger le biais supplémentaire lié à la racine carrée.



La précision, donnée par l'erreur quadratique moyenne, est difficile à calculer explicitement pour des lois quelconques. Il semblerait cependant qu'en dépit d'un biais plus important, Sn soit plus précis que Sn –1[i 9].
Écart type des moyennes
Pour estimer la précision de l'estimation de la moyenne d'une variable, la méthode du calcul de l'écart type de la distribution d'échantillonnage des moyennes est utilisée. Appelé aussi erreur type de la moyenne (« Standard error »), noté , c'est l'écart type des moyennes des échantillons de tailles identiques d'une population. Si n est la taille des échantillons prélevés sur une population d'écart type σ, et si N est la taille de la population, alors [b 31]. Lorsque l'écart type σ de la population est inconnu, il peut être remplacé par l'estimateur Sn–1[b 31]. Quand n est suffisamment grand (n ≥ 30), la distribution d'échantillonnage suit approximativement une loi de Laplace-Gauss, ce qui permet de déduire un intervalle de confiance, fonction de , permettant de situer la moyenne de la population par rapport à la moyenne de l'échantillon[b 32],[b 33].


Écart type des écarts types empiriques
En général, il est très difficile de calculer la loi de distribution des écarts types empiriques. Mais si Xn est une suite de variables aléatoires distribuées selon la loi normale , alors suit une loi du χ2 à n degrés de liberté[b 13],[Note 6]. Cette loi a pour écart type √2n et donc l'écart type de la distribution des variances de variables normales a pour expression [b 13].



Sondages d'opinion
Dans les sondages d'opinion, l'écart type évalue l'incertitude des variations accidentelles de x inhérentes au sondage, ce qu'on appelle la marge d'erreur due aux variations accidentelles[i 11].
De plus, avec la méthode d'échantillonnage représentatif, lorsque les différentes strates ont des écarts types très différents, l'écart type est utilisé pour calculer la répartition optimale de Neyman qui permet d'évaluer la population dans les différentes strates en fonction de leur l'écart type ; en d'autres termes est la taille de l'échantillon dans la strate i, où n est la taille totale de l'échantillon, Ni est la taille de la strate i, σi l'écart type de la strate i[i 11].

En algorithmique
Les écarts types obtenus par un programme d'ordinateur peuvent être incorrects si on n'utilise pas un algorithme adapté aux données, comme lorsqu'on utilise celui qui exploite directement la formule sur des grands échantillons de valeurs comprises entre 0 et 1[i 12],[i 13].

Un des meilleurs algorithmes est celui de B.P. Welford qui est décrit par Donald Knuth dans son livre The Art of Computer Programming, vol. 2[i 14],[i 15].
Une approximation de l'écart type de la direction du vent est donnée par l'algorithme de Yamartino dont on se sert dans les anémomètres modernes[i 16],[i 17].
Notes et références
Notes
- ↑ Si n élèves ont 0/20 et n élèves ont 20/20, c'est-à-dire l'échantillon contient n fois la valeur 20 et n fois la valeur 0, la moyenne est ; soit X = 10 et X 2 = 100.
Les valeurs au carré, notées X2, sont n fois 400 et n fois 0. La moyenne de X2 vaut donc . On en déduit que la variance vaut 100 et l'écart type 10. - ↑ La deuxième égalité est donnée par le théorème de König-Huygens.
- ↑ Toutes ces propriétés sont la conséquence directe du théorème de Huygens et des propriétés de l'espérance mathématique.
- ↑ L'inégalité découle de l'égalité précédente et de l'encadrement du coefficient de corrélation : .
- ↑ D'après le théorème de continuité on a :Théorème — Si g est continue, alors :. Comme la fonction racine carrée est une fonction continue, Sn-1 et Sn sont des estimateurs convergents de l'écart type, autrement dit :
- ↑ par définition de la loi du χ2





Références
Ouvrages spécialisés
- ↑ Bernstein 1996, p. 127.
- 1 2 3 Dodge 2010, p. 506
- 1 2 3 Saporta 2006, p. 279-280
- ↑ Saporta 2006, p. 121
- ↑ (en) David R. Anderson, Dennis J. Sweeney et Thomas A. Williams, « statistics », Encyclopaedia Britannica Ultimate Reference Suite, , statistics
- ↑ Saporta 2006, p. 16
- 1 2 Saporta 2006, p. 30
- ↑ Rioul 2008, p. 45
- ↑ Saporta 2006, p. 31
- ↑ Saporta 2006, p. 38
- 1 2 Saporta 2006, p. 39
- ↑ Saporta 2006, p. 33
- 1 2 3 Dodge 2010, p. 71
- ↑ (en) Warren H. Finlay, The Mechanics of Inhaled Pharmaceutical Aerosols : An Introduction, San Diego, Academic Press Inc, , 320 p. (ISBN 978-0-12-256971-5, lire en ligne), p. 5
- ↑ Dodge 2010, p. 60
- ↑ Saporta 2006, p. 23-25
- ↑ Saporta 2006, p. 26
- ↑ Rioul 2008, p. 146
- ↑ Saporta 2006, p. 43-44
- ↑ Jean-Pierre Petit, La Bourse : Rupture et Renouveau, Paris, Odile Jacob économie, , 285 p. (ISBN 978-2-7381-1338-2, lire en ligne), p. 36
- ↑ Gautier et al. 1975, p. 387
- ↑ Saporta 2006, p. 66
- ↑ Rioul 2008, p. 157
- ↑ Rioul 2008, p. 175
- ↑ Rioul 2008, p. 178
- ↑ Saporta 2006, p. 25
- ↑ Jacquard 1976, p. 28-29
- ↑ Saporta 2006, p. 289
- ↑ Tufféry 2010, p. 655
- ↑ Rioul 2008, p. 253
- 1 2 Dodge 2010, p. 508-509
- ↑ Dodge 2010, p. 472
- ↑ Vessereau 1976, p. 56
Articles de revue
- ↑ (en) Ronald Aylmar Fisher, « The Correlation between Relatives on the Supposition of Mendelian Inheritance », Philosophical Transactions of the Royal Society of Edinburgh, vol. 52, , p. 399–433 (lire en ligne [PDF])
- ↑ Sylvie Méléard, « Aléatoire : Introduction à la théorie et au calcul des probabilités » [PDF] (consulté le ), p. 57,94
- ↑ P. Ferignac, « Contrôle de réception quantitatif ou par mesure. », Revue de statistique appliquée, vol. 7, no 2, (lire en ligne [PDF], consulté le )
- ↑ P. Ferignac, « Erreurs de mesure et contrôle de la qualité. », Revue de statistique appliquée, vol. 13, no 2, (lire en ligne [PDF], consulté le )
- ↑ Rolf Heuer, « Une fin d’année pleine de suspense », Bulletin Hebdomadaire du CERN, vol. 2012, no 3, (lire en ligne, consulté le )
- ↑ (en) John Bollinger, « Bollinger Bands Introduction » (consulté le )
- ↑ P Fery, « Risque et calcul socioéconomique », Centre d'analyse stratégique, (lire en ligne [PDF], consulté le )
- ↑ Yves Meyer, « Principe d'incertitude, bases hilbertiennes et algèbres d'opérateurs. », Séminaire Bourbaki, vol. 662, (lire en ligne [PDF], consulté le )
- 1 2 3 Emmanuel Grenier, « Quelle est la « bonne » formule de l’écart-type ? », Revue Modulad, no 37, (lire en ligne [PDF], consulté le )
- ↑ Richard M. Brugger, « A Note on Unbiased Estimation of the Standard Deviation », The American Statistician, vol. 23, no 4, , p. 32–32 (ISSN 0003-1305, DOI 10.1080/00031305.1969.10481865, lire en ligne, consulté le )
- 1 2 W.E. Deming, « Quelques méthodes de sondage. », Revue de statistique appliquée, vol. 12, no 4, (lire en ligne [PDF], consulté le )
- ↑ (en) John D. Cook, « Theoretical explanation for numerical results » (consulté le )
- ↑ (en) John D. Cook, « Comparing three methods of computing standard deviation » (consulté le )
- ↑ (en) B.P. Welford, « Note on a Method for Calculating Corrected Sums of Squares and Products », Technometrics, vol. 4, no 3, , p. 419-420 (lire en ligne [PDF], consulté le )
- ↑ (en) John D. Cook, « Accurately computing running variance » (consulté le )
- ↑ (en) R.J. Yamartino, « A comparison of several "single-pass" estimators of the standard deviation of wind direction », Journal of climate and applied meteorology, vol. 23, , p. 1362-1366 (lire en ligne [PDF], consulté le )
- ↑ (en) Mike Bagot, « Victorian Urban Wind Resource Assessment » [PDF] (consulté le )
Autres références
- ↑ « Basics of Descriptive Statistics », sur www.che.utah.edu (consulté le )
- ↑ Voir théorème de König-Huygens pour l'établissement de la seconde formule
- ↑ (en) « sd: Standard Deviation », sur RDocumentation.
Voir aussi
Bibliographie
- Gilbert Saporta, Probabilités, Analyse des données et Statistiques, Paris, Éditions Technip, , 622 p. [détail des éditions] (ISBN 978-2-7108-0814-5, présentation en ligne), seconde édition

- Alain Monfort, Cours de Statistique Mathématique, Paris, éditions Economica, , 333 p. (ISBN 2-7178-3217-3).
- (en) Encyclopaedia Britannica Ultimate Reference Suite, Chicago, Encyclopædia Britannica, .
- Olivier Rioul, Théorie des probabilités, Paris, éditions Hermes sciences, , 364 p. (ISBN 978-2-7462-1720-1).
- (en) Yadolah Dodge, The Concise Encyclopaedia of Statistics, New York, Springer, , 622 p. (ISBN 978-0-387-31742-7, lire en ligne).
- Stéphane Tufféry, Data Mining et statistique décisionnelle : l'intelligence des données, Paris, éditions Technip, , 705 p. (ISBN 978-2-7108-0946-3, lire en ligne).
- (en) Peter L. Bernstein, Against the Gods : The Remarkable Story of Risk, New York, John Wiley & sons, inc, , 383 p. (ISBN 978-0-471-12104-6).
- Albert Jacquard, Les Probabilités, Paris, Presses Universitaires de France, coll. « Que sais-je » (no 1571), , 125 p. (ISBN 2-13-036532-9).
- C. Gautier, G. Girard, D. Gerll, C. Thiercé et A. Warusfel, Aleph1 Analyse, Paris, éditions Hachette, , 465 p. (ISBN 2-01-001370-0).
- André Vessereau, La Statistique, Paris, Presses Universitaires de France, coll. « Que sais-je » (no 281), , 128 p. (ISBN 2-13-052942-9).
- (en) Richard Herrnstein et Charles Murray, The Bell Curve : Intelligence and Class Structure in American Life, New York, Simon & Schuster Ltd, , 896 p. (ISBN 978-0-684-82429-1), Appendix 1, "Statistics for People Who Are Sure They Can't Learn Statistics"
Articles connexes
- Calcul d'erreur
- Indicateur de dispersion
- Erreur type
- Écart type géométrique
- Moment d'ordre n
- Coefficient de variation
- Variance
- Écart moyen
Liens externes
- Notices dans des dictionnaires ou encyclopédies généralistes :
- (en) Algorithms for calculating variance