| Alphabet phonétique international | |
 Fiche récapitulative de l'API, édition révisée de 2020. | |
| Caractéristiques | |
|---|---|
| Historique | |
L'alphabet phonétique international (API) est un alphabet utilisé pour la transcription phonétique des sons du langage parlé. Contrairement aux nombreuses autres méthodes de transcription qui se limitent à des familles de langues, l'API est conçu pour couvrir l'ensemble des langues du monde. Développé par des phonéticiens français et britanniques sous les auspices de l'Association phonétique internationale, il a été publié pour la première fois en 1888. Sa dernière révision date de 2005 ; celle-ci comprend 107 lettres, 52 signes diacritiques et 4 caractères de prosodie.
Histoire
L'API a été développé au départ par des professeurs de langue britanniques et français sous la direction de Paul Passy dans le cadre de l'Association phonétique internationale, fondée à Paris en 1886 sous le nom de Dhi Fonètik Tîcerz' Asóciécon. La première version de l'API, publiée en 1888, était inspirée de l'alphabet romique de Henry Sweet, lui-même élaboré à partir de l'alphabet phonotypique d'Isaac Pitman et Alexander John Ellis.
L'API a connu plusieurs révisions en 1900, 1932, 1938, 1947, 1951, 1989, 1993, 1996 et 2005.
Principes généraux
La transcription phonétique en API consiste à découper la parole en segments sonores supposés insécables, et à employer un symbole unique pour chacun de ceux-ci, en évitant les multigrammes (combinaisons de lettres, comme le son ch du français, noté /ʃ/ phonologiquement, ou le gli italien, transcrit /ʎ/ phonologiquement).
| langue | mot écrit | phonologie (normative) | phonétique (exemple de réalisation) |
|---|---|---|---|
| français | endurer | /ɑ̃.dy.ʁe/ | [ɒ̃d̪yˈʁe] |
| allemand | dulden | /ˈdul.dən/ | [ˈdʊːldn̩] |
| anglais | tolerate | / ˈtɒl.ə.ɹeɪ̯t/ | [ˈtʰɒˑləɹeɪ̯tʔ] |
| espagnol | aguantar | /a.ɡwanˈtaɾ/ | [äɰʷän̪ˈt̪äɾ] |
| espéranto | suferi | /suˈfe.ri/ | [suˈfeɾi] |
| malgache | mihafy | /mi.a.fi/ | [miˈjafi̥] |
| catalan | aguantar | /ə.ɡwənˈta/ | [əɣwən̪ˈt̪a] |
| italien | sopportare | /sop.porˈta.re/ | [sopːorˈt̪äːre] |
| néerlandais | verdragen | /vɛrˈdra.ɣən/ | [vɛɹˈdraːɣən̩] |
| mandarin | 忍 (ren³) | /ʐən˨˩˦/ | [ʐən˨˩˦] |
| arpitan | endurar | /ɛ̃.du.ˈrar/ | [ɛ̃d̪yˈʁɑ] |
| arabe | عانى | /ˈʕaːnaː/ | [ˈʕaːnaː] |
Le nombre de caractères principaux de l’API est de 118, ce qui permet de couvrir les sons les plus fréquents. Ces caractères sont pour la plupart des lettres grecques ou latines ou des modifications de celles-ci : ɾ, ɽ, ɺ, ɹ (tirés de r) ; ɘ, ə (tirés de e). Les sons moins fréquents sont transcrits à partir des précédents en indiquant une modification du mode ou du point d'articulation par le biais d'un ou plusieurs signes diacritiques (au nombre de 76) sur le caractère principal : par exemple, le b du castillan caber (« tenir, rentrer dans ») est transcrit [β̞] pour indiquer une spirante au lieu de la fricative bilabiale sonore [β]. Il existe également des symboles spéciaux pour noter des phénomènes suprasegmentaux, comme les tons mélodiques ou l'accent tonique : [ˈdʊl·dn̩], transcription de l'allemand dulden (« supporter, tolérer ») indique un accent tonique d'intensité sur la première syllabe (ˈ) et un n final vocalisé ( n̩ ).
Barres obliques (phonologie) et crochets (phonétique)
- L'usage linguistique indique entre barres obliques la transcription phonologique des termes, celle qui oppose les traits pertinents des différents sons d'une langue donnée sans entrer dans le détail de leur prononciation (dont les réalisations possibles sont notées phonétiquement).
- Le découpage syllabique (avec le symbole .) n’est pas aussi pertinent que dans la transcription phonologique d’une langue donnée. Les transcriptions phonologiques revêtent souvent un caractère normatif de la langue : les transcriptions phonologiques ne doivent donc s’interpréter qu'en combinaison avec la langue indiquée (qui définit les équivalences phonétiques reconnues entre ses locuteurs), laquelle utilise un jeu simplifié de symboles phonologiques et non le jeu complet des symboles de l’API.
- Certains sons phonologiques, bien que normalement pertinents dans une langue, peuvent aussi ne pas toujours être prononcés, les locuteurs interprétant une forme ou l’autre comme le même mot, de façon contextuelle. C’est le cas en français avec le e muet qui parfois se prononce quand même (et parfois modifie le découpage syllabique phonologique). Quand ce son ne se prononce le plus souvent pas, on l’omet de la transcription phonologique (cas du e muet français). En revanche, ce cas est plus courant dans des langues comme l’anglais sans qu’aucune préférence ne se dégage. Dans ce cas, on note souvent entre parenthèses les sons concernés.
- L'utilisation de l'API est maintenant établie dans l’enseignement, l'apprentissage et l’étude des langues. Notamment, la plupart des dictionnaires bilingues utilisent cet alphabet pour noter la phonologie, ou bien une transcription phonologique qui en est inspirée. L'API est également un outil essentiel pour rendre à l’écrit les langues jusqu’à présent non écrites : de nombreuses langues d’Afrique se sont dotées d’une orthographe utilisant comme signes complémentaires des caractères de l'API (envers l'Alphabet africain de référence) et liés à la phonologie de ces langues ; par exemple l’alphabet pan-nigérian, l’alphabet général des langues camerounaises, l’alphabet scientifique des langues du Gabon, l’Alphabet des langues nationales du Bénin, l’alphabet national burkinabè, l’alphabet national tchadien, l’alphabet des langues nationales du Mali, l’orthographe pratique des langues ivoiriennes, ou l’orthographe standardisée et uniformisée du Congo-Kinshasa.
- Cependant, les transcriptions phonétiques d’un mot ou d’une phrase (très souvent multiples) se notent entre crochets.
- Ces transcriptions phonétiques (plus précises et pouvant utiliser le jeu complet des symboles de l’API) devraient se lire normalement indépendamment de la langue (cependant des simplifications sont souvent apportées en fonction du contexte de réutilisation de ces transcriptions). La réalisation phonétique de la prononciation ne réalise très souvent pas non plus les découpages syllabiques (qui sont la plupart du temps supprimés des notations phonétiques), sauf en cas de réalisation de pauses, variables entre les réalisations possibles (qui peuvent être notées phonétiquement avec d’autres symboles plus précis que le .).
- De même, on ne transcrit normalement pas les parenthèses phonologiques en notation phonétique : soit on transcrit le son phonétiquement, soit on l’omet totalement des mots transcrits phonétiquement, en indiquant séparément les réalisations possibles de la façon la plus exacte possible.
- Nombre de lecteurs ont des difficultés à lire les transcriptions phonétiques, notamment quand elles reproduisent des sons (phonèmes, tonèmes) dont ils ne perçoivent pas eux-mêmes les différences ou qu’ils sont incapables de prononcer. En revanche, les transcriptions phonétiques sont souvent utiles pour aider les lecteurs à interpréter les notations phonologiques de langues étrangères, afin d’apprendre à faire les distinctions nécessaires, ou savoir si leur propre réalisation phonétique est compatible avec la langue étrangère.
- Ces notations phonétiques se retrouvent donc parfois dans les tableaux expliquant la phonologie d’une langue, mais la plupart du temps ces tableaux sont plus clairs pour le lecteur quand la notation phonologique s’accompagne d’un exemple de mot (de préférence dans la langue native de ce lecteur) dont les réalisations phonétiques habituelles dans sa langue (ou les langues qu’il peut connaitre plus facilement) posent moins de problème au lecteur et lui permettent d’identifier les distinctions pertinentes que la langue étrangère opère dans sa phonologie, tout en lui permettant d’adapter sa prononciation pour mieux reproduire l’accent habituel des locuteurs natifs de cette langue étrangère.
La plupart du temps donc, les notations phonétiques exactes (indépendantes de la langue) sont rarement notées, au contraire des transcriptions phonologiques.
Description de l'alphabet
Voyelles
L'API possède des caractères principaux pour les voyelles orales les plus courantes qui sont classées selon :
- leur degré d'ouverture : voyelles fermées (hautes), pré-fermées (hautes inférieures), mi-fermées (moyennes supérieures), moyennes, mi-ouvertes (moyennes inférieures), pré-ouvertes (basses supérieures), ouvertes (basses) ;
- leur point d'articulation : antérieur, quasi-antérieur, central, quasi-postérieur, postérieur ;
- leur caractère arrondi ou non.
Table des voyelles
Ce tableau classe les voyelles selon les critères ci-dessus, comme le fait le triangle vocalique ou le trapèze vocalique.
| Point d'articulation→ | Antérieures | Quasi-antérieures | Centrales | Quasi-postérieures | Postérieures | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Ouverture↓ | non arr. | arr. | non arr. | arr. | non arr. | arr. | non arr. | arr. | non arr. | arr. | |
| Fermées | i | y | ɨ | ʉ | ɯ | u | |||||
| Pré-fermées | ɪ | ʏ | ɯ̽ | ʊ | |||||||
| Mi-fermées | e | ø | ɘ | ɵ | ɤ | o | |||||
| Moyennes | e̞ | ø̞ (en) | ə | ɤ̞ (en) | o̞ | ||||||
| Mi-ouvertes | ɛ | œ | ɜ | ɞ | ʌ | ɔ | |||||
| Pré-ouvertes | æ | ɐ | |||||||||
| Ouvertes | a | ɶ | ä | ɑ | ɒ | ||||||
Le classement de ces voyelles peut aussi se faire avec une représentation en trois dimensions qui met en évidence les trois critères de classification :
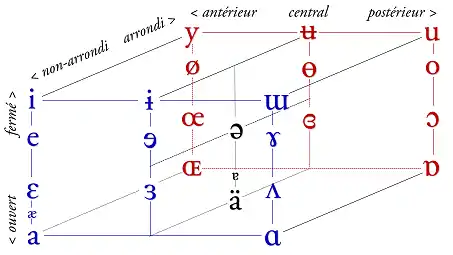
Les autres voyelles sont transcrites à partir de celles-ci par adjonction d'un ou plusieurs diacritiques modifiant son articulation :
Table des diacritiques affectant les voyelles
| modification | diacritique | modification | diacritique | |
|---|---|---|---|---|
| arrondissement (labialisation) | ɔ̹ | avancement de la racine linguale | e̘ | |
| désarrondissement (délabialisation) | ɔ̜ | rétraction de la racine linguale | e̙ | |
| avancement (plus antérieur) | u̟ | centralisation | ë | |
| rétraction (plus postérieur) | i̠ | semi-centralisation | e̽ | |
| moins ouvert (montée) | e̝ | laryngalisation | a̰ | |
| plus ouvert (descente) | e̞ | nasalisation | ẽ | |
| murmure | a̤ | voir l’image PNG modifier | ||
Par exemple :
- les nasales du français standard sont ɔ̃ (on), ɛ̃ (hein), œ̃ (un), ɑ̃ (an) ;
- le /o/ bref du hongrois (par ex. kor, âge) est moins postérieur et légèrement plus ouvert que le /oː/ long (par ex. kór, maladie), une transcription soigneuse le donne comme [o̟̞].
Quantité (allongement ou amuïssement)
La quantité des voyelles est indiquée comme suit :
| modification | allongement | aucune | amuïssement | ||||
|---|---|---|---|---|---|---|---|
| quantité | long | mi-long | bref | extra-bref | |||
| signe | chrone | semi-chrone | aucun | brève | |||
| exemples | aː | tː | aˑ | tˑ | a | t | ă |
Notes :
- Le symbole de ponctuation deux-points est souvent employé à la place du chrone (deux points triangulaires), par exemple [a:] au lieu de [aː].
- Dans les langues où l’allongement ou l’amuïssement des voyelles existent encore pour certains locuteurs mais ne sont plus pertinents (par exemple en français moderne « standard »), on n’annote plus les voyelles longues dans les transcriptions phonologiques, et on y omet même les voyelles amuïes (par exemple le schwa amuï en finale de mot, devenu e muet en français moderne).
- Les transcriptions latines basées sur l’analyse phonémique, dans des langues qui distinguent encore les longueurs de voyelles (par exemple le japonais ou les langues indo-aryennes), s'écartent souvent de la notation API et utilisent un macron (voire un accent circonflexe) pour les voyelles longues.
Par exemple, Pose cette rose !, phonologiquement /poz sɛt ʁoz/, est souvent réalisé en français du nord-ouest parisien [poːsɛtˈʁoːz], en français du sud-ouest [pɔˑzəsɛtəˈʁ̥ɔˑzə], en français de Corse [poːzəsɛtəˈʁoːzə], en français picard [pɔsɛtˈʁɔz], en français de Lorraine/Champagne/Bourgogne [poz'sɛːtʁoːz] (ces réalisations régionales sont des occurrences courantes mais elles peuvent aussi varier légèrement de personne à personne, selon l'âge, l'humeur ou l'intention, c'est pourquoi il est rare de les utiliser comme référence terminologique, les dictionnaires se contentant de l'analyse phonologique sans marquer chaque différence possible dans la réalisation phonétique des phonèmes).
L’amuïssement de voyelles phonémiques longues n'est pas noté phonétiquement : on utilise le symbole usuel en ôtant son signe d’allongement phonétique. En revanche les syllabes courtes sont notées phonologiquement par un accent bref et les voyelles amuïes sont soit supprimées de la notation phonémique soit marquées entre parenthèses.
Tonèmes
La transcription des tonèmes suit le procédé ci-dessous.
- Pour certains tons dont le profil de hauteur est simple on utilise soit un diacritique soit un pictogramme représentant la hauteur du ton ou un accent (par exemple : ton de hauteur constante haut, mi-haut, médian, mi-bas, bas).
- Pour les tons dont le profil de hauteur est plus complexe seul un pictogramme représentant le profil du ton est prévu. Par exemple, il est possible de rendre le mandarin 我姓张 (wǒ xìng zhāng) (« Mon nom de famille est Zhang ») par /wɔ˨˩˦ ɕiŋ˥˩ tʂɑŋ˥/. [voir notes ci-dessous].
| Signes de l’alphabet phonétique international pour la transcription des tonèmes. | ||||||
|---|---|---|---|---|---|---|
| ton | diacritique | barre | ton | diacritique | barre | |
| haut | e̋ | e˥ | ascendant | ě | e˩˥ | |
| mi-haut | é | e˦ | descendant | ê | e˥˩ | |
| médian | ē | e˧ | ascendant haut | e᷄ | e˦˥ | |
| mi-bas | è | e˨ | ascendant bas | e᷅ | e˩˨ | |
| bas | ȅ | e˩ | montant-descendant | e᷈ | e˦˥˦ | |
voir l’image PNG
Diacritiques/barres : notations équivalentes | ||||||
La faille tonale est représentée par ꜜ , le haussement tonal par ꜛ .
Notes :
- Les symboles pour les tons de hauteur variable ne s’affichent correctement que si la police utilisée pour les afficher a prévu cette possibilité et que le navigateur la prend en charge ; dans le cas contraire sont affichés à la suite les symboles correspondant aux différentes hauteurs prises par le ton. Le tracé correct des symboles est donné sur la fiche récapitulative de l'API.
- La notation numérique des tons en exposant, par exemple 我姓张 /wɔ214 ɕiŋ51 tʂɑŋ5/, est souvent utilisée pour pallier la piètre gestion des tons de l’API par les ordinateurs actuels. Cette notation n’est pas standard et son format dépend des familles de langues étudiées, mais elles sont très courantes dans leurs transcriptions phonologiques car ces tons sont linguistiquement pertinents pour distinguer les termes des langues fortement tonales telles que les langues chinoises.
- Dans les translittérations latines (romanisations), où les symboles API ne sont pas utilisés du tout mais sont remplacés par l’usage de graphies proches des langues occidentales et comportant de nombreux digrammes (par exemple la romanisation normalisée pinyin), ces tons sont même notés très souvent avec des chiffres normaux et non des exposants.
- Parfois, ces mêmes tons sont transcrits à l’aide des accents ou diacritiques usuels des orthographes latines (au lieu des chiffres), et souvent sans rapport avec les diacritiques de l’API : de telles romanisations ont même pu évoluer en orthographe normale pour ces langues tonales (par exemple l’écriture latine actuelle du vietnamien, où une même voyelle peut comporter deux signes diacritiques distincts : un accent ou diacritique lié pour noter la modification vocalique, l’autre accent au-dessus de l’ensemble vocalique pour noter le ton).
Consonnes
Segments
L'API classe les consonnes selon trois critères :
- le mode d'articulation ;
- le point d'articulation ;
- le voisement.
| Mode d’articulation | Point d’articulation | ||||||||||||||||||||||||||||||||||
| Labial | Coronal | Dorsal | Radical | Glottal | |||||||||||||||||||||||||||||||
| Pulmoniques | Bilabial | Lab.-dent. | Labial-vél. | Dental | Alvéol. | Pal.-alv. | Rétro. | Alv.-pal. | Alv.-vél. | Palatal | Labio-pal. | Vélaire | Labio-vél. | Uvulaire | Pharyngal | Épiglottal | Aucun | ||||||||||||||||||
| Nasales | m | ɱ | ŋ͡m | n̪ | n | ɳ | ɲ | ŋ | ŋʷ | ɴ | |||||||||||||||||||||||||
| Occl. prénasalisées | m͡p | m͡b | ᵑk͡p | ᵑɡ͡b | n͡t̪ | n͡d̪ | n͡t | n͡d | ɳ͡ʈ | ɳ͡ɖ | ɲ͡c | ɲ͡ɟ | ŋ͡k | ŋ͡ɡ | ɴ͡q | ɴ͡ɢ | |||||||||||||||||||
| Occlusives | p | b | p̪ | b̪ | k͡p | ɡ͡b | t̪ | d̪ | t | d | ʈ | ɖ | c | ɟ | k | ɡ | kʷ | ɡʷ | q | ɢ | ʡ | ʔ | |||||||||||||
| Affriquées | p͡ɸ | b͡β | p͡f | b͡v | t͡θ | d͡ð | t͡s | d͡z | t͡ʃ | d͡ʒ | ʈ͡ʂ | ɖ͡ʐ | t͡ɕ | d͡ʑ | c͡ç | ɟ͡ʝ | k͡x | ɡ͡ɣ | q͡χ | ɢ͡ʁ | ʡ͡ʜ | ʔ͡h | |||||||||||||
| Fric. prénasalisées | m͡ɸ | m͡β | ɱ͡f | ɱ͡v | n͡θ | n͡ð | n͡s | n͡z | n͡ʃ | n͡ʒ | ŋ͡k | ŋ͡ɡ | |||||||||||||||||||||||
| Fricatives | ɸ | β | f | v | θ | ð | s | z | ʃ | ʒ | ʂ | ʐ | ɕ | ʑ | ɧ | ç | ʝ | x | ɣ | xʷ | ɣʷ | χ | ʁ | ħ | ʕ | ʜ | ʢ | h | ɦ | ||||||
| Spirantes | β̞ | ʋ | ð̞ | ɹ | ɻ | j | ɥ | ɰ | ʍ | w | |||||||||||||||||||||||||
| Roulées | ʙ̥ | ʙ | r̪ | r̥ | r | ɽ͡r | ʀ | * | |||||||||||||||||||||||||||
| Battues | * | ⱱ | ɾ̪ | ɾ | ɽ | * | |||||||||||||||||||||||||||||
| Affriquées latér. | t͡ɬ | d͡ɮ | |||||||||||||||||||||||||||||||||
| Fricatives latér. | ɬ | ɮ | ꞎ | ʎ̝̊ | * | ||||||||||||||||||||||||||||||
| Spirantes latér. | l̪ | l̥ | l | ɭ | ɫ | ʎ̥ | ʎ | ʟ | |||||||||||||||||||||||||||
| Battues latér. | ɺ | * | * | * | |||||||||||||||||||||||||||||||
| Non pulmoniques | |||||||||||||||||||||||||||||||||||
| Occl. injectives | ɓ̥ | ɓ | ɗ̪ | ɗ̥ | ɗ | * | ʄ̊ | ʄ | ɠ̊ | ɠ | ʛ̥ | ʛ | |||||||||||||||||||||||
| Occl. éjectives | pʼ | t̪ʼ | tʼ | ʈʼ | cʼ | kʼ | qʼ | ʡʼ | |||||||||||||||||||||||||||
| Affr. éjectives | t̪͡θʼ | t͡sʼ | t͡ʃʼ | ʈ͡ʂʼ | k͡xʼ | q͡χʼ | |||||||||||||||||||||||||||||
| Fric. éjectives | ɸʼ | fʼ | θʼ | sʼ | ʃʼ | ʂʼ | ɕʼ | çʼ | xʼ | χʼ | |||||||||||||||||||||||||
| Clics centraux | ʘ | ǀ | ǃ | ǂ | |||||||||||||||||||||||||||||||
| Clics latéraux | ǁ | ||||||||||||||||||||||||||||||||||
Les parties grisées indiquent une articulation jugée impossible. Les cases blanches vides indiquent des articulations théoriques possibles mais non encore attestées. Les cases marquées d’un astérisque (*) indiquent des sons attestés non encore représentés officiellement dans l’API.
Lorsque deux symboles apparaissent dans une case, celui de gauche représente une consonne sourde, celui de droite une consonne voisée (ne s’applique pas aux clics, présentés au centre des cases en bas du tableau).
Les cases séparées par des pointillés emploient normalement les mêmes symboles API de base, et ne diffèrent éventuellement que par les diacritiques appliqués pour déplacer leur articulation, par exemple la nasale n represente une dentale ou une alvéolaire.
Les affriquées t͡s, d͡z, t͡ʃ, d͡ʒ, t͡ɕ, d͡ʑ sont parfois notées à l’aide des ligatures ʦ, ʣ, ʧ, ʤ, ʨ, ʥ ne faisant plus partie de l’API (il est recommandé de les remplacer par les deux articulations, liées avec une ligature tirant – suscrite ou souscrite).
Les occlusives injectives sourdes, sont parfois notées à l’aide des symboles ƥ, ƭ, ƈ, ʠ (formés sur la base de la consonne pulmonique correspondante avec une crosse ajoutée), qui ne font plus partie de l’API (il est recommandé de les remplacer par le symbole de la consonne voisée avec l'anneau diacritique de dévoisement).
Comme pour les voyelles, des diacritiques permettent d'indiquer une modification du point ou du mode d'articulation afin de transcrire des consonnes qui n'ont pas de symbole principal.
| t̟ | avancement | d̪ | articulation dentale | b̤ | murmure | ||
| t̠ | rétraction | d̺ | articulation apicale | b̰ | laryngalisation | ||
| ɹ̝ | montée | d̻ | articulation laminale | dʷ | labialisation | ||
| β̞ | descente | d̼ | articulation linguo-labiale | dʲ | palatalisation | ||
| d̥ | dévoisement | dˡ | désocclusion latérale | dˠ | vélarisation | ||
| t̬ | voisement | dⁿ | désocclusion nasale | dˤ | pharyngalisation | ||
| x̹ | arrondissement | d̚ | désocclusion inaudible | tʰ | aspiration | ||
| x̜ | désarrondissement | ⁿd | prénasalisation | ɡ͡b | articulation double | ||
| t͡s | affriquée | ə˞ | rhotacisme | Image PNG ; modifier | |||
◌ᶿ : désocclusion fricative dentale sourde
◌ˣ désocclusion fricative vélaire sourde
Par exemple :
Quantité / Gémination
La quantité des consonnes (leur éventuelle gémination) est indiquée de la même manière que pour les voyelles. Le hongrois Mit mondott? (Qu'a-t-il/elle dit ?), phonologiquement /mit mon.dotː/, pourra être transcrit phonétiquement [mɪt̪mo̟n̪d̪o̟t̪].
Vocalisation
Une consonne vocalisée, c'est-à-dire servant de sommet à une syllabe, comporte un trait vertical souscrit dans sa notation phonologique ; en revanche la vocalisation (par exemple un schwa bref) devrait être explicitée dans la notation phonétique, séparément de la consonne mentionnant l’articulation exacte :
Syllabes et accentuation
Le fait que la fin d'un mot et le début du mot suivant forment une seule syllabe est noté par ‿ entre les 2 mots.
Un point ‹ . › sépare les syllabes pertinentes dans la notation phonologique ; de même les mots restent séparés par des espaces. Ces deux signes phonologiques sont généralement omis des transcriptions phonétiques, sauf pour indiquer la présence effective d’une pause. Par exemple, l'allemand Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz (loi sur le transfert de responsabilité de la surveillance de l'étiquetage de la viande bovine) se transcrit phonologiquement :
/ˌʁɪnt.flaɪʃ.ʔeti.kɛ.ˌtiː.ʁʊŋs.ʔyˑbɐ.ˌva.xʊŋs.ˌʔaʊf.ɡaː.bn̩.ʔyˑbɐ.ˌtʁ̥aː.gʊŋs.ɡə.ˈzɛts/.
Les syllabes accentuées sont précédées d’une courte barre verticale :
- en exposant ‹ ˈ › pour l'accent primaire ;
- en indice ‹ ˌ › pour l'accent secondaire.
Les réalisations phonétiques des accents syllabiques peuvent varier suivant les langues et les locuteurs, entre la mutation de la consonne d'attaque, l’allongement ou la diphtongation de la voyelle au sommet de la syllabe, le changement de ton, la gémination ou la mutation de la consonne finale : ces réalisations possibles ne sont pas toujours distinguées clairement, et nombre de transcriptions phonétiques gardent la notation phonologique de ces accents avec les mêmes symboles.
La brève inversée souscrite ‹ ◌̯ › (ou suscrite en cas de manque de place ◌̑ ) signale qu'un élément est à rattacher à la syllabe courante et ne constitue pas un nouvel élément syllabique. Par exemple : /po̯.ˈeta/, transcription phonologique du mot espagnol poeta signifiant « poète ». (exemple tiré du Handbook of the IPA, p. 25).
Au contraire, la syllabicité est notée par la ligne verticale souscrite ◌̩ (ou suscrite en cas de manque de place ◌̍).
Intonation : la rupture mineure est notée par | , la rupture majeure par ‖ , la montée globale par ↗︎ , et la descente globale par ↘︎ .
Unicode
Le jeu de caractères Unicode permet d'écrire l'ensemble de l'API. Les symboles et diacritiques se situent dans les blocs de caractères suivants :
- U+0000 à U+007F : Commandes C0 et latin de base ;
- U+0080 à U+00FF : Commandes C1 et supplément Latin-1 ;
- U+0250 à U+02AF : Alphabet phonétique international ;
- U+02B0 à U+02FF : Lettres modificatives avec chasse ;
- U+0300 à U+036F : Diacritiques ;
- U+0370 à U+03FF : Grec et copte ;
- U+A700 à U+A71F : Lettres modificatives de ton.
Certains caractères précomposés (avec diacritiques) sont accessibles dans les blocs suivants :
- U+0080 à U+00FF : Supplément Latin-1 ;
- U+0100 à U+017F : Latin étendu A ;
- U+0180 à U+024F : Latin étendu B ;
- U+1E00 à U+1EFF : Supplément latin étendu.
Exemple : prononciation du français en API
Tableau emprunté à l'article Alphabet phonétique international sur l'encyclopédie sœur Vikidia :
|
|
Références
Voir aussi
Articles connexes
- Alphabet phonétique international cursif
- Alphabet phonétique américaniste
- Alphabet phonétique ouralien
- Prononciation du français
- TIPA (paquetage permettant l'utilisation de l'API en LaTeX)
- Annexe:Prononciation sur le Wiktionnaire
Bibliographie
- API
- (en) International Phonetics Association, Handbook of the International Phonetics Association : a guide to the use of the International Phonetic Alphabet, Cambridge, Cambridge University Press, , 204 p. (ISBN 0-521-63751-1 et 0-521-65236-7, lire en ligne)
- André Martinet, Éléments de linguistique générale, Paris, Armand Colin, (1re éd. 1960), 223 p. (ISBN 978-2-200-26573-1, 9782200602994 et 2-200-26573-5)
- (en) Luciano Canepari, « The official IPA & other notations », dans A Handbook of Phonetics: ‹Natural› Phonetics, München, Lincom Europa, , 518 p. (ISBN 3-89586-480-3, lire en ligne)
- Exemples linguistiques
- « Illustrations of the IPA - free content [= Illustrations de l’API - contenu gratuit] », sur Journal of the International Phonetic Association
- allemand : Duden, die Grammatik, (ISBN 3-411-04046-7)
- anglais : Cambridge Dictionary of American English, (ISBN 0-521-77974-X)
- mandarin : (fr) CFDICT ou (en) CEDICT
Liens externes
- (en) Site officiel
- Notices dans des dictionnaires ou encyclopédies généralistes :
- canIPA, système de Luciano Canepari : 500 symboles basiques, 300 complémentaires, et 200 supplémentaires (documents PDF en anglais et en italien ; traduction française du chapitre sur le français)
- Tableau API des consonnes et voyelles avec audio et exemples par le Laboratoire de phonétique expérimentale de l'université de Turin, Italie.
- Université de Toulouse, France, « Symboles phonétiques des sons du français » [PDF], (consulté le )