
Une puce à ADN est un ensemble de molécules d'ADN fixées en rangées ordonnées sur une petite surface qui peut être du verre, du silicium ou du plastique. Cette biotechnologie récente permet d'analyser le niveau d'expression des gènes (transcrits) dans une cellule, un tissu, un organe, un organisme ou encore un mélange complexe, à un moment donné et dans un état donné par rapport à un échantillon de référence.
Les puces à ADN sont aussi appelées puces à gènes, biopuces ou par les termes anglais « DNA chip, DNA-microarray, biochip ». Les termes français microréseau d'ADN et micromatrice d'ADN sont aussi des termes proposés par l'Office québécois de la langue française[1].
Le principe de la puce à ADN repose sur la propriété que possède l'ADN dénaturé (simple brin) de reformer spontanément sa double hélice lorsqu'il est en présence d'un brin complémentaire (réaction d'hybridation). Les quatre bases nucléiques de l'ADN (A, G, C, T) ont en effet la particularité de s'apparier deux à deux par des liaisons hydrogène (A = T et T = A ; G ≡ C et C ≡ G).
On parle de sonde (fragment d'ADN synthétique représentatif des gènes dont on cherche à étudier l'expression, fixé de façon covalente à la surface de la biopuce) et de cible (ARNm que l’on cherche à identifier et/ou à quantifier (échantillon)). Les cibles sont marquées par fluorescence (voir plus bas).
Les puces à ADN peuvent être utilisées pour mesurer/détecter les ARN qui seront traduits ou non en protéines. Les scientifiques parlent d'analyse d'expression ou de profil d'expression. Puisqu'il est possible de fixer jusqu'à un million de sondes sur une biopuce, les puces à ADN constituent ainsi une approche massive. Elles ont contribué à la révolution de la génomique[2], puisqu'elles permettent, en une seule expérience, d'avoir une estimation sur l'expression de plusieurs dizaines de milliers de gènes. Il existe également un grand nombre d'applications différentes qui font intervenir la technologie des puces à ADN (criblage de mutations, reséquençage, interactions ADN/protéine, écologie microbienne).
Principe
En pratique, les ARN totaux sont extraits des cellules étudiées et subissent parfois une amplification qui va permettre d'obtenir une quantité de matériel génétique suffisante pour l'expérience. Ces ARNm sont ensuite transformés en ADN complémentaires (ADNc) par la technique de rétrotranscription et marqués. Ce marquage est aujourd'hui assuré par une molécule fluorescente (fluorochrome). Il existe deux fluorochromes majoritairement utilisés : la Cyanine 3 (Cy3) qui fluoresce dans le vert et la Cyanine 5 (Cy5) qui fluoresce dans le rouge. Les cibles ainsi marquées (ADNc) sont ensuite mises en contact avec la puce (portant l'ensemble des sondes à sa surface), cette étape est nommée hybridation. Chaque brin d'ADNc va alors s'hybrider aux sondes qui lui sont complémentaires pour former un duplex sonde/cible double brin. La biopuce est ensuite lavée par des bains spécifiques pour éliminer les brins d'ADNc ne s'étant pas hybridés car non complémentaires des sondes fixées sur la lame. La biopuce va ensuite être analysée par un scanner à très haute résolution, et ce à la longueur d'onde d'excitation de la Cyanine 3 ou de la Cyanine 5. L'image scannée est alors analysée informatiquement afin d'associer une valeur d'intensité à chaque sonde fixée sur la biopuce et ainsi de déterminer s'il y a eu une hybridation pour chaque sonde.
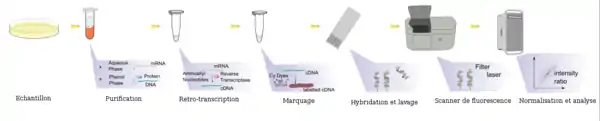
Lors d'une expérience de biopuce ADN visant à comparer l'expression des gènes entre deux conditions (par exemple : cellule saine versus cellule malade), les ARN totaux des deux populations de cellules sont extraits et marqués chacun avec un fluorochrome différent. Les deux échantillons sont alors déposés simultanément sur la biopuce, on parle d'hybridation compétitive. Pour un gène donné, si le nombre de molécules d'ADNc correspondant à ce gène est plus important dans une condition que dans l'autre, l'hybridation entre ces ADNc et les sondes associées sera favorisée. Ainsi, après avoir scanné la biopuce aux deux longueurs des deux fluorochromes utilisés, il est possible de comparer l'intensité du signal vert et celle du signal rouge et donc de savoir, pour chaque gène étudié, dans quelle condition il est le plus exprimé.
Historique
Les balbutiements des puces à ADN se font dès les années 1991 avec une publication[3] de Stephen Fodor (scientifique américain et fondateur de la société Affymetrix) sur la technologie de synthèse in situ. S'ensuivent ensuite plusieurs événements qui entrent en ligne de compte :
- 1995 : Publication de Patrick Brown (biochimiste de l'université de Chicago) sur l’analyse de la transcription[4]
- 1996 : Publication de Patrick Brown sur l’analyse de la transcription dans des cellules tumorales[5]
- 1997 : Analyse globale de l’expression des gènes de la levure[6] grâce à la technologie des biopuces.
- 1999 : Création de la Microarray and Gene Expression Data (MGED) Society et premières analyses du transcriptome du cancer par l'équipe de Patrick Brown[7].
- 2001 : Création du projet MIAME (Minimum Information About a Microarray Experiment) qui décrit les conditions nécessaires à réunir pour assurer la réussite d'une expérience de biopuce ainsi qu'une fiabilité des résultats.
- 2002 : Développement de la technologie NimbleGen Maskless Photolithography[8], la photolithographie étant utilisée dans les biopuces.
- 2004 : Développement de la technologie des Randomly Ordered DNA Arrays[9]
Utilisation et applications
Différentes technologies
On distingue deux types d'analyses de biopuces :
- les biopuces à un canal : aussi appelées puces monochromatiques, ces puces permettent d'analyser un seul échantillon ou une seule condition par expérience. Néanmoins, elles ne permettent pas de connaitre le niveau d'abondance d'un gène dans l'absolu, mais plutôt une abondance relative en étant comparé à d'autres échantillons ou conditions au sein d'une même expérience. Cette comparaison de deux conditions du même gène demande deux hybridations monochromatiques distinctes.
- les biopuces à deux canaux : elles permettent la comparaison de deux échantillons, marqués par deux fluorophores différents, en une seule expérience. Elles reposent sur le principe d'hybridation compétitive entre les deux échantillons comparés.
Une des forces de la biopuce à un canal réside dans le fait qu'un échantillon aberrant n'affecte pas l'analyse des autres échantillons. A contrario, chez les biopuces à deux canaux, il suffit d'un seul échantillon de mauvaise qualité pour diminuer drastiquement la qualité des résultats, même si l'autre échantillon cible est parfait. Une autre force est que les données d'une biopuce à un canal sont plus facilement comparées à d'autres biopuces provenant de différentes expériences. De plus, la biopuce à un canal est parfois la seule solution possible pour certaines applications.
Le tableau suivant est repris de la page anglophone de Wikipédia.
| Nom du procédé ou de la technologie | Description |
|---|---|
| Expression des gènes | Il s'agit de l'utilisation la plus connue de la puce à ADN. On compare l'expression des gènes entre différentes conditions données ou au cours du temps. Grâce à l'hybridation et à une analyse d'image effectuée ensuite, ce procédé permet d'identifier quels gènes sont sur- ou sous-exprimés dans une condition donnée. Une fois ces gènes identifiés, d'autres analyses in silico sont nécessaires, telles que des analyses de clustering pour regrouper les gènes présentant le même profil d'expression. Enfin, les résultats seront souvent confirmés gène par gène par des méthodes telles que la PCR quantitative ou le Northern Blot. (méthodes d'analyse des gènes) |
| Immunoprécipitation de chromatine | Les biopuces peuvent aussi utiliser le phénomène d'immunoprécipitation de chromatine (Chromatin immunoprecipitation on Chip, ou ChIP-On-Chip). Ce procédé permet de déterminer la localisation du site de liaison de la protéine dans le génome. |
| Polymorphisme | La puce à ADN peut aussi permettre de détecter du polymorphisme, c'est-à-dire d'identifier des polymorphismes ponctuels d’allèles au sein d’une population ou entre populations, prédire le développement de maladies au sein d'une population, évaluer les mutations ou encore analyser les liens entre gènes. |
| Tiling | Ces puces sont dédiées à la recherche de nouveaux transcrits (on entend par là gène transcrit). C'est-à-dire que chaque segment de chromosome (pas seulement les gènes connus) est ciblé par une sonde. Un des intérêts est de découvrir de très nombreux ARN non codants (comme les ARN longs non-codants par exemple). On peut ainsi réussir à cartographier les transcrits, rechercher des exons, ou encore rechercher les facteurs de transcription. |
| Biopuce à gène chimère | Il existe aussi des biopuces à gène chimère (ou gène de fusion). Le principe derrière est celui de l'alternative splicing en anglais, ou encore épissage alternatif en français. Une telle biopuce peut alors détecter les gènes transcrits par fusion, donc de spécimens de cancer. |
| Hybridation génomique comparative | Une puce d'hybridation génomique comparative est une puce à ADN employée dans le but d'analyser les variations du nombre de copies dans l'ADN. Cette technique est principalement utilisée pour diagnostiquer les cancers et les maladies génétiques. |
| GeneID | Ces puces à ADN sont utilisées pour détecter certains types d'organismes dans la nourriture (comme des OGM), des mycoplasmes en culture cellulaire, ou certains agents infectieux pour diagnostiquer des maladies. La technique repose principalement sur la réaction en chaîne par polymérase. |
Domaines d'applications
La liste ci-dessous n'a pas vocation à être exhaustive, mais elle donne un panorama des domaines d'applications des biopuces.
- Biologie médicale de cancérologie : domaine de la cancérologie pour le typage tumoral d'après leur profil génétique. L'utilisation des puces à ADN comme outil de diagnostic présente l'avantage de faire appel à de nombreux marqueurs : plusieurs milliers de gènes peuvent être criblés simultanément pour fournir une signature du type cellulaire étudié. Si l'on considère que chaque type de tumeur présente une signature génétique unique, ce système permet virtuellement de distinguer et classer tous les types de tumeurs. Les puces à ADN permettent donc de comparer l'expression des gènes de deux types cellulaires différents (Réseaux de co-expression de gènes) , de faire de l'étude des gènes exprimés sur un grand nombre de patients pour observer l'effet d'un médicament (anti-cancéreux par exemple), de regarder l'effet d'un traitement sur l'expression des gènes, de comparer tissus sains contre tissus malades, traités contre non-traités, etc.
- Microbiologie : afin de définir les résistances aux antibiotiques, par exemple.
- Toxico-génomique : étude de l’influence de diverses substances toxiques sur l’expression des gènes. Les génotoxiques (comme le benzène, l'amiante, les rayonnements radioactifs, les rayonnements solaires, les produits cancérigènes, etc., ) sont visibles grâce au procédé des puces à ADN. En effet, les puces à ADN permettent d'analyser la réponse cellulaire à la présence de génotoxiques (au niveau du transcriptome). On étudie les effets sur un grand nombre d'individus, ces effets seront différents en raison du polymorphisme. Cette étude ouvre la porte à la pharmacogénomique.
- Génomique environnementale :
- détection de bactéries pathogènes dans un échantillon biologique : la puce contient alors des sondes dirigées contre les ARNr 16S de plusieurs bactéries pathogènes (Salmonelles, Légionelles, Staphylocoques...)
- détection de substances polluantes dans l’eau (grâce aux biocapteurs) : même principe que pour la cancérologie, la puce permet l'identification de gènes spécifiquement induits et fortement induits par l’agent polluant introduit dans l'une des cibles.
- biopuces phylogénétiques : composition de la communauté microbienne grâce notamment à la présence de marqueurs phylogénétiques : ARN ribosomiques (16S, 18S, 23S, 25S, 28S)
- biopuces fonctionnelles : évaluation des capacités métaboliques grâce à des marqueurs fonctionnels (gènes codant des enzymes clés dans les processus métaboliques étudiés)
Fabrication
La puce est une lame, généralement en verre, de petite taille environ (6 cm x 3 cm), sur laquelle sont fixés des sondes complémentaire d'un fragment d'acide nucléique (ADN ou ARN) ciblé. Jusqu'à un million de sondes peuvent être fixés sur une puce permettant ainsi l'analyse de plusieurs dizaines voire centaines de milliers de gènes.
Quels types de sonde poser sur la puce[10] ?
| Oligonucléotides | Sondes longues | |
|---|---|---|
| Taille | 15 - 70 mers | > 100 mers |
| Avantages | - Détection des SNP (polymorphisme)
- Livré « prêt à spotter » |
- Insensibles aux allèles/variants
- Production en grande quantité - Collections disponibles (EST, BAC...) - Double brin, plus de choix de marquage, meilleur couverture du génome |
| Inconvénients | - Sensibles aux allèles/variants
- Coût de la production de masse - Le design des oligos est une étape complexe |
- Une résolution plus faible
- La production des produits de PCR est lourde - Problème d’hybridation croisée - Erreurs des collections (EST) |
Quels types de gènes sont concernés ?
En soi, aucune contre-indication n'existe concernant le type de gènes à tester (gènes aux fonctions connues ou inconnues). Néanmoins, afin de pouvoir tirer des informations fiables des expériences de biopuces, il est conseillé d'inclure des sondes de contrôle positif et négatif afin de vérifier et contrôler le bon déroulement de chaque étape de l'expérience.
Par dépôt (spotted)
Ce procédé utilise des sondes longues (une centaine de nucléotides) déposées sur la lame. Les sondes sont synthétisées avant d'être déposées sur la surface par rangées d’infimes gouttelettes, ou spots, (d'où le terme anglais microarray, « microtableau »). On utilise des aiguilles fines contrôlées par un bras robotisé qui est plongé dans les spots. Les aiguilles vont alors injecter dans chaque spot les sondes en excès. La «grille» finale représente les profils d’acides nucléiques des sondes préparées et chaque sonde est prête à s'hybrider avec les cibles.
Cette méthode est la plus simple, ce qui rend cette solution plus accessible aux laboratoires académiques. Elle est utilisée par les scientifiques et chercheurs dans le monde entier pour produire les puces adaptées à leur besoins. Les puces sont facilement personnalisées pour chaque expérience car les chercheurs peuvent choisir le type et l'emplacement des sondes, voire synthétiser les sondes eux-mêmes.
Les scientifiques peuvent ensuite générer leurs propres échantillons cibles, utilisés pour l'hybridation avec les sondes, pour enfin analyser les puces avec leurs propres équipements. Cela fournit une puce moins chère (en évitant les coûts d'achat de puces commerciales) et aussi adaptée à leurs exigences.
Les puces qui sont fabriquées de cette manière ne peuvent cependant pas posséder la même densité de sondes que les puces fabriquées par synthèse in situ.
Par synthèse in situ

Ces puces sont fabriquées en synthétisant les sondes d'ADN de petite taille (< 80-mers) directement sur le support (biopuce) par synthèse chimique.
- Photolithographie. Cette méthode repose sur l'utilisation de nucléotides couplés à des groupements chimiques photosensibles. La présence de ces groupements photosensibles empêche l'élongation. La synthèse in situ repose donc sur l'alternance de cycles de protection et dé-protection (UV) en utilisant des masques ou des micro-miroirs. Les sociétés Affymetrix et Nimblegen utilisent ce système de synthèse in situ.
- Chambre de réaction en diamant (Oxford Gene Technology)[11]
- La société Agilent utilise un procédé similaire à celui de l'impression à jet d'encre pour le dépôt des sondes sur la lame.
Traitement informatique pour l'analyse des résultats
Une image haute résolution est obtenue grâce à des scanners très haute résolution (de l'ordre du micromètre) qui permettent de révéler les interactions sonde/cible par excitation des fluorochromes portés par les cibles. En France la société INNOPSYS développe, fabrique et commercialise une gamme complète de scanners de fluorescence dédiés à la lecture et l'analyse de ce type de lames : InnoScan 710 (2 couleurs, 3 µm/pixel, InnoScan 710-IR, InnoScan 910 (2 couleurs, 1 µm/pixel) et InnoScan 1100 (3 couleurs, 0.5 µm/pixel).
Des logiciels interprètent l'intensité des pixels de l'image afin d'en déduire une mesure numérique de l'expression de chaque gène.

De grands volumes de données sont générés par l'analyse d'une puce à ADN, et de nombreuses techniques sont utilisées pour interpréter les résultats de l'expérience. Ces techniques incluent :
- L'analyse d'image : une analyse automatique de l'image générée par la puce à ADN est dans un premier temps nécessaire. Cela permet notamment de repérer et séparer les spots, d'éliminer les spots défectueux, et d'annoter chaque spot avec son intensité lumineuse globale, afin d'obtenir des résultats numériques exploitables pour un traitement automatisé[12].
- La normalisation : afin de pouvoir comparer les résultats de plusieurs expériences, il est ensuite nécessaire de normaliser les données. En effet, des biais entre plusieurs expériences peuvent être introduits par la qualité et la quantité des échantillons, les fluorochromes utilisés, leur sensibilité à la chaleur ou à la lumière, les conditions dans lesquels les échantillons ont été scannés, etc. Plusieurs méthodes mathématiques existent et reposent sur l'hypothèse principale que la majorité des différences de signal observées sont liés à des biais techniques et non à des différences biologiques.
- L'analyse statistique : de nombreux tests statistiques peuvent être appliqués aux données, permettant par exemple de savoir si un gène est significativement plus exprimé que les autres ou plus exprimé dans une condition que dans l'autre, via un test de Student. Il est souvent intéressant voire nécessaire de recréer plusieurs fois l'expérience en variant légèrement certains paramètres pour mener une analyse fiable. Il existe des méthodes d'analyse statistique tenant compte des différents réplicats de l'expérience et du caractère variable de l'expressivité d'un gène selon l'échantillon[13].
- Le clustering : cette approche consiste à essayer de diviser les données en plusieurs groupes homogènes (ou clusters) . Cela permet notamment de regrouper les gènes impliqués dans le même processus biologique, ou de regrouper des échantillons similaires entre eux. Les algorithmes les plus utilisées incluent K-means, qui a l'inconvénient de nécessiter de connaître le nombre de clusters voulus à l'avance, et le clustering hiérarchique, qui permet de créer une hiérarchie de clusters pour ensuite retenir uniquement les clusters ayant un certain niveau dans la hiérarchie.
- La classification supervisée : cette approche utilise une base de connaissance pour apprendre un modèle de prédiction. On peut, par exemple, à partir de plusieurs échantillons venant de patients porteurs d'une maladie donnée, construire un modèle statistique permettant de prédire si un nouvel échantillon appartient à un patient malade ou non, et ainsi créer un système d'aide au diagnostic[14]. Ces méthodes sont basées sur un jeu de données d'apprentissage, qui permet de construire le modèle prédictif, et un jeu de données de test, qui doit être entièrement différent du jeu de données d'apprentissage et permet d'évaluer la qualité du modèle prédictif face à de nouveaux exemples. Les méthodes les plus courantes incluent l'apprentissage d'un arbre de décision, l'utilisation de réseaux bayésiens, ou les réseaux de neurones artificiels.
Références
- ↑ Office québécois de la langue française, « puce à ADN », novembre (consulté le )
- ↑ Pavel A. Pevzner (trad. de l'anglais), Bio-informatique moléculaire : Une approche algorithmique, Londres, Springer, , 314 p. (ISBN 978-2-287-33908-0)
- ↑ (en) Tim Lenoir et Eric Giannella, « The emergence and diffusion of DNA microarray technology », Journal of Biomedical Discovery and Collaboration, vol. 1, , p. 11 (ISSN 1747-5333, PMID 16925816, PMCID 1590052, DOI 10.1186/1747-5333-1-11, lire en ligne, consulté le )
- ↑ (en) Mark Schena, Dari Shalon, Ronald W. Davis et Patrick O. Brown, « Quantitative Monitoring of Gene Expression Patterns with a Complementary DNA Microarray », Science, vol. 270, , p. 467–470 (ISSN 0036-8075 et 1095-9203, PMID 7569999, DOI 10.1126/science.270.5235.467, lire en ligne, consulté le )
- ↑ DeRisi J, Penland L, Brown PO, Bittner ML, Meltzer PS, Ray M, Chen Y, Su YA, Trent JM. « Use of a cDNA microarray to analyse gene expression patterns in human cancer. » Nat Genet. 1996, 14(4):457-60
- ↑ Lashkari DA, DeRisi JL, McCusker JH, Namath AF, Gentile C, Hwang SY, Brown PO, Davis RW. « Yeast microarrays for genome wide parallel genetic and gene expression analysis.» PNAS, 1997, 94(24):13057-62
- ↑ C. M. Perou, S. S. Jeffrey, M. van de Rijn et C. A. Rees, « Distinctive gene expression patterns in human mammary epithelial cells and breast cancers », Proceedings of the National Academy of Sciences of the United States of America, vol. 96, , p. 9212–9217 (ISSN 0027-8424, PMID 10430922, PMCID 17759, lire en ligne, consulté le )
- ↑ Emile F. Nuwaysir, Wei Huang, Thomas J. Albert et Jaz Singh, « Gene expression analysis using oligonucleotide arrays produced by maskless photolithography », Genome Research, vol. 12, , p. 1749–1755 (ISSN 1088-9051, PMID 12421762, PMCID 187555, DOI 10.1101/gr.362402, lire en ligne, consulté le )
- ↑ Kevin L. Gunderson, Semyon Kruglyak, Michael S. Graige et Francisco Garcia, « Decoding randomly ordered DNA arrays », Genome Research, vol. 14, , p. 870–877 (ISSN 1088-9051, PMID 15078854, PMCID 479114, DOI 10.1101/gr.2255804, lire en ligne, consulté le )
- ↑ « Introduction aux Puces à ADN », sur transcriptome.ens.fr,
- ↑ Matthew J. Moorcroft, Wouter R. A. Meuleman, Steven G. Latham et Thomas J. Nicholls, « In situ oligonucleotide synthesis on poly(dimethylsiloxane): a flexible substrate for microarray fabrication », Nucleic Acids Research, vol. 33, , e75 (ISSN 0305-1048, PMID 15870385, PMCID 1088307, DOI 10.1093/nar/gni075, lire en ligne, consulté le )
- ↑ « Méthodes bioinformatiques d’analyse des puces à ADN », sur transcriptome.ens.fr, (consulté le )
- ↑ Mei-Ling Ting Lee, Frank C. Kuo, G. A. Whitmore et Jeffrey Sklar, « Importance of replication in microarray gene expression studies: Statistical methods and evidence from repetitive cDNA hybridizations », Proceedings of the National Academy of Sciences of the United States of America, vol. 97, , p. 9834–9839 (ISSN 0027-8424, PMID 10963655, PMCID 27599, lire en ligne, consulté le )
- ↑ « De l’Acquisition des Données de Puces à ADN vers leur Interprétation : Importance du Traitement des Données Primaires », sur irisa.fr,
Voir aussi
Liens externes
- [PDF] Julien Tap Mise au point d’une puce à ADN pour le typage et l’étude de la bio-diversité de Listéria(2005)
- [PDF] Alain Baccini et Philippe Besse Analyse statistique de données transcriptomique
- Stéphane LE CROM et Philippe MARC http://transcriptome.ens.fr/sgdb/presentation/principle.php.fr
- Rémi BERNARD, Université d'Aix-Marseille http://biologie.univ-mrs.fr/upload/p64/pucesTD.pdf
- Université de l'Utah Animation sur le fonctionnement des biopuces
Articles connexes
- Chip on chip
- Transcriptome
- Photolithographie
- Microfluidique