| ISO/CEI 646-02 ou ISO/CEI 646-06 (ASCII) | ||
 Les 95 caractères imprimables d'ASCII : !"#$%&'()*+,-./
0123456789:;<=>?
@ABCDEFGHIJKLMNO
PQRSTUVWXYZ[\]^_
`abcdefghijklmno
pqrstuvwxyz{|}~ | ||
| Famille | ISO/CEI 646 | |
|---|---|---|
| Langues | Anglais | |
| Nombre de caractères | 128 | |
| État du projet | Norme établie | |
| Plates-formes | Toutes | |
| Numéro d'enregistrement | 002 006 038 (EBCDIC USA ASCII) 367 (IBM AIX 7-bit US-ASCII) 371 (IBM AIX 7-bit US-ASCII APL) 907 (DOS ASCII APL) 1054 (HP ASCII) 20127 (Microsoft 7-bit US-ASCII) |
|
| Licence | Norme ISO payante | |
| Séquences d'échappement | 002: jeu G0: ESC 2/8 4/0 jeu G1: ESC 2/9 4/0 006: jeu G0: ESC 2/8 4/2 |
|
| Unité de codage (codet) | Sept à huit bits suffisent | |
| Première version | ISO/CEI 646-02 et ISO/CEI 646-06 (1er janvier 1975) | |
L'American Standard Code for Information Interchange (Code américain normalisé pour l'échange d'information), plus connu sous l'acronyme ASCII (/as.ki/, ), est une norme décrivant une table d'encodage de 127 points de code d'entrée-sortie pour des systèmes informatiques sur 7 bits. Elle est apparue dans les années 1960 et est notamment utilisée pour le codage des 95 caractères imprimables d'une machine à écrire américaine (Télétype) : les chiffres arabes de 0 à 9, les 26 lettres de l'alphabet latin en minuscules et en capitales, des symboles mathématiques et de ponctuation.
ASCII est la norme de codage de caractères la plus influente à ce jour. Elle suffit pour représenter les textes en anglais, mais il est trop limité pour les autres langues, dont le français et ses lettres accentuées.
La norme ASCII est à la base de la plupart des systèmes de gestions de fichiers et de données, ce qui fait que les limitations du jeu de caractères ASCII sont encore sensibles au XXIe siècle, par exemple dans le choix restreint de caractères généralement offerts pour composer une adresse électronique ou une adresse web. Ce sujet était concernait aussi les noms de fichiers informatiques
L'ASCII est une des variantes de la norme ISO/CEI 646. Il est inclus dans plusieurs dizaines de normes couvrant plus de caractères, qui sont parfois informellement appelées ASCII étendu. Celles-ci peuvent être régionales (ISO/CEI 8859), nationales (GB 18030) ou internationales (Unicode). Avec l'avènement de la mondialisation et de l'internationalisation des systèmes d'information, les limitations de l'ASCII ne sont plus acceptées que dans des domaines techniques qui requièrent la compatibilité avec des protocoles de communication ou systèmes anciens.
Histoire
Avant la standardisation, de nombreux codages de caractères incompatibles entre eux existaient[1]. Chaque matériel avait son propre codage, lié aux techniques qu'il utilisait. Tout ordinateur, comme l'IBM 1130, était livré avec ses sous-programmes et ses tables permettant de transposer les codes d'un matériel à un autre. D'autres standards, comme l'EBCDIC d'IBM, étaient utilisés, notamment pour les cartes perforées[2],[3].
En 1960, l'ISO a créé le Technical Committee on Computers and Information Processing[4] (Comité technique pour les ordinateurs et le traitement de l'information). Il a été divisé en six groupes de travail A à F :
- A : Glossaire ;
- B : Jeux et codages des caractères ;
- C : Reconnaissance des caractères ;
- D : Supports d'entrée et de sortie ;
- E : Langages de programmation ;
- F : Transmission de données numériques.
L'American Standards Association (ASA, aujourd'hui ANSI) était chargée du standard des États-Unis. L'ASA a reconnu le consortium Business Equipment Manufacturers Association (BEMA, puis, CBEMA) comme le parrain du travail de standardisation du traitement des données. En 1960, BEMA a formé un groupe de traitement des données des partenaires, dont Minneapolis-Honeywell. Ce groupe a formé un Plans and Policies Committee, qui à son tour a formé l'Engineering Committee. L'Engineering Committee a formé le comité X3, qui a été reconnu par l'ASA comme Sectional Committee. Parmi les membres du comité, Bob Bemer est parfois présenté comme père de l'ASCII, ce qu'il ne faut pas comprendre comme inventeur de l'ASCII, mais comme grand artisan de la diffusion d'ASCII[5].
En 1961, le DoD met au point un code standard de transmission de donnée sur 8 bits[6]. Ce standard 8 bits est une variante des standards FIELDATA sixbits utilisés dans la décennie précédente par la défense. Il a eu une influence notable sur la première version de l'ASCII.
En 1963, la première version publiée de l'ASCII apparaît. La liste des caractères à considérer et leur position ont été débattues[7].
Sa dernière version stabilisée a été normalisée par l'ANSI en 1986 sous la désignation ANSI X3.4:1986 (après deux autres versions en 1967 et 1968, historiquement normalisées par l'ASI, devenu ANSI mais qui ne normalisait pas encore toutes les positions). C'est également la variante américaine des jeux de caractères codés selon la norme ISO/CEI 646 avec laquelle on la confond souvent (d'où sa désignation également comme US-ASCII pour lever l'ambigüité, désignation préférée dans le registre IANA des jeux de caractères codés).
À l'époque elle a été en concurrence avec des standards incompatibles. Par la suite, l'existence de nombreux codages reprenant les conventions de l'ASCII l'a rendu très populaire. IBM, qui utilisait sur ses mainframes un autre codage, l'EBCDIC, ne commença à utiliser officiellement l'ASCII sur ses matériels qu'avec l'IBM PC, en 1981.
Principes
L'ASCII définit 128 caractères numérotés de 0 à 127 et codés en binaire de 0000000 à 1111111. Sept bits suffisent donc. Toutefois, les ordinateurs travaillant presque tous sur un multiple de huit bits (un octet) depuis les années 1970, chaque caractère d'un texte en ASCII est souvent stocké dans un octet dont le 8e bit est 0. Aujourd'hui encore, certains systèmes de messagerie électronique et de SMS fonctionnent avec des bytes ou multiplets composés de seulement sept bits (contrairement à un octet qui est un byte ou multiplet standardisé à huit bits).
Les caractères de numéro 0 à 31 et le 127 ne sont pas affichables ; ils correspondent à des commandes de contrôle de terminal informatique. Le caractère numéro 127 est la commande pour effacer. Le caractère numéro 32 est l'espace. Le caractère 7 provoque l'émission d'un signal sonore. Les autres caractères sont les chiffres arabes, les lettres latines majuscules et minuscules sans accent, des symboles de ponctuation, des opérateurs mathématiques et quelques autres symboles.
Limitations
L'absence des caractères des langues étrangères à l'anglais rend ce standard insuffisant à lui seul pour des textes étrangers (par exemple en langue française), ce qui rend nécessaire l'utilisation d'autres encodages.
Lorsqu'il est employé seul pour la langue anglaise, il interdit l'usage des accents dans la langue anglaise.
Quelques-uns des caractères graphiques ASCII ont provoqué une polysémie. Ceci est en tout ou partie lié au nombre limité de codets dans un jeu à sept bits. Ceci se retrouve notamment dans les symboles de ponctuation et l'utilisation des guillemets. L'ASCII a été conservé parce qu'il est omniprésent dans de nombreux logiciels. Cet héritage se retrouve dans Unicode où ces signes sont dans un bloc disjoint des autres symboles similaires, se trouvant pour la plupart codés à partir de U+2000[8].
Internationalisation
Les limites du standard américain ASCII ont conduit, sur trois périodes différentes, à trois approches de l'internationalisation :
- l'utilisation de standards régionaux à caractères mesurant un octet, techniquement les plus faciles à mettre en place ;
- l'utilisation de standards extensibles, où un même octet peut représenter un caractère différent suivant le contexte (famille ISO/CEI 2022) ainsi que des extensions où un caractère est codé sur plusieurs octets ;
- l'utilisation du standard Unicode (famille UTF), qui est celui qui comprend le plus grand nombre de caractères.
Les standards régionaux à caractères mesurant un octet ont l'inconvénient de ne permettre la représentation que d'un ensemble réduit de caractères, comme les caractères d'Europe occidentale. Avec cette approche, l'encodage doit être donné par le contexte.
Les standards extensibles ont l'inconvénient d'être contextuels. Il se peut que des logiciels utilisant certains algorithmes de recherche manquent d'interopérabilité à cet égard.
Standardisation
Le jeu de codage ASCII est défini quasiment identiquement par plusieurs standards différents, a de nombreuses variantes et a donné naissance à une foison (des dizaines ou des centaines) d'extensions plus ou moins incompatibles entre elles.
Les principales extensions sont justifiées par le fait que l'ASCII ne répond pas aux divers besoins régionaux. Elles sont proposées par des organismes de normalisation, ou par des fournisseurs de produits et de services.
Les standards ASCII
N.B. — Ne pas confondre USASI X3.4-1968 ou ANSI X3.4-1968 et ANSI X3.4:1986.
Standards ASCII des États-Unis (les standards hérités, et le standard en vigueur) :
- ASA X3.4-1963, (incomplet avec 28 positions libres, et un code de commande non assigné) ;
- USASI X3.4-1967 (renommé rétroactivement ANSI X3.4-1967), qui ne normalisait pas encore toutes les positions ;
- USASI X3.4-1968 (renommé rétroactivement ANSI X3.4-1968), qui ne normalisait pas encore toutes les positions ;
- ANSI X3.4-1977 ;
- ANSI X3.4:1986 (en 1986, et en vigueur aujourd'hui).
Les standards internationaux suivants sont généralement considérés compatibles (quasi identiques) avec le standard ASCII en vigueur de 1986 à 2011, tout en constituant une normalisation internationale officielle :
- Norme ISO/CEI 646 :
- ISO/CEI 646-US Variante des États-Unis,
- Variante IRV internationale ;
- Code page IBM 367 ;
- Alphabet International de Référence :
La désignation US-ASCII, ASCII É-U ou ASCII des États-Unis est un mélange des désignations précédentes. Le registre IANA lui attribue la dénomination US-ASCII, sans en définir le codage.
Approximation, variantes et extensions
- Norme ISO/CEI 646
- Variante INV invariable (incomplète par rapport aux deux précédentes).
Trois types de codages de caractères se rapprochent de l'ASCII :
- ceux qui ne changent que par la dénomination — ils sont essentiellement identiques à l'ASCII ;
- ceux qui sont des variantes, l'ASCII étant à l'origine la variante locale aux États-Unis de l'ISO/CEI 646 ;
- ceux qui l'augmentent, dits extensions.
Alias
En , le RFC 1345[11] et la chambre d'enregistrement de jeux de caractères Internet Assigned Numbers Authority[12] ont reconnu les alias suivants, insensibles à la casse, convenables pour l'utilisation dans des protocoles Internet :
L'IANA promeut plus particulièrement la dénomination « US-ASCII » pour Internet.
Variantes
ASCII a donné naissance à certaines variantes qui conservent la plupart des caractères, mais en remplacent une partie. Dès lors, il ne s'agit plus d'ASCII à strictement parler. Outre ISO/CEI 646, on trouve d'autres variantes dans l'histoire de l'informatique. Par exemple, le circonflexe (#94) est remplacé par la flèche vers le haut et le soulignement (#95) est remplacé par la flèche vers la gauche, dans l'ensemble de caractères intégré des puces Motorola 6847 (VDG) et du GIME, qui équipaient les adapteurs vidéo du TRS-80 Color Computer et d'autres anciens ordinateurs des années 1980. Mais plusieurs années plus tôt, les ordinateurs Xerox équipés du langage de programmation Smalltalk incluaient les mêmes deux caractères (en mode graphique).
Par ailleurs, certains anciens ordinateurs n'étaient équipés que du deux tiers d'ASCII, c'est-à-dire les caractères 32 à 95 plutôt que 32 à 126. C'est alors à proprement parler une variante à 6 bits. Sur le TRS-80 Color Computer, on mettait dans les fichiers les codes 32 à 127, mais ceux de 96 à 127 étaient des versions en couleurs inversées (vert sur noir plutôt que noir sur vert). Ces blocs de 32 caractères étaient échangés au moment d'envoyer au VDG, pour lequel les codes ASCII 32 à 63 étaient numérotés 96 à 127, tandis que les 0 à 63 étaient en couleurs inversées (en soustrayant 64). En outre, les codes 128 à 255 encodaient des formes de blocs en couleurs. Le GIME était capable de fonctionner soit comme le VDG, soit en mode ASCII, avec circonflexe #94, soulignement #95. Il avait aussi en option sa propre extension 8-bit pour les lettres accentuées minuscules et majuscules, compatible avec probablement aucun autre ordinateur.
Certaines extensions 7-bit ont un caractère #127, comme les premiers Apple, qui y avaient un quadrillé, et les cartes vidéo PC (Page de code 437) qui y avaient une sorte de pentagone, en plus de remplir les cases 0 à 31 de flèches, cercles et signes divers. Naturellement, on ne pouvait pas utiliser ces codes dans les contextes où ils avaient une signification de contrôle ; et inversement, lorsque des codes de contrôle n'étaient pas interprétés comme tels, comme quand le #27 est censé signifier commencer une séquence VT100 (ANSI.SYS) mais apparaît comme une flèche vers la gauche (par exemple, ).
{kind=link}
Huitième bit et augmentations
De nombreuses normes de codage de caractères ont repris les codes ASCII et ajouté d’autres caractères pour les codes supérieurs à 127.
Parmi les nombreuses extensions 8 bits de l'ASCII, le Multinational Character Set créé par Digital Equipment Corporation pour le terminal informatique VT220 est considéré comme à la fois l'ancêtre de l'ISO/CEI 8859-1 et de l'Unicode[13].
Extensions mono-octets
En particulier, beaucoup de pages de code étendent l'ASCII en utilisant le 8e bit pour définir des caractères numérotés de 128 à 255. La norme ISO/CEI 8859 fournit des extensions pour diverses langues. Par exemple, l'ISO/CEI 8859-1, aussi appelée Latin-1, étend l'ASCII avec les caractères accentués utiles aux langues originaires d'Europe occidentale comme le français ou l'allemand.
Par abus de langage, on appelle souvent « ASCII » des normes qui étendent l'ASCII, mais qui ne sont pas compatibles entre elles (et parfois même ne sont pas compatibles sur leurs 128 premiers caractères codés). En particulier, les standards Windows-1252 (couramment utilisé sur Microsoft Windows dans les pays occidentaux), ISO/CEI 8859-1 (couramment utilisé sur Internet et Unix) et les pages de code pour PC numéro 437 et 850 (couramment utilisées sur DOS) ne sont pas la norme ASCII. Cet abus de langage ne va pas sans causer des confusions causant des incompatibilités, souvent rendues visibles par le fait que les caractères non ASCII comme les « lettres accentuées » (éÈç) s'affichent mal. On écrit parfois « ASCII de base » pour différencier l'ASCII d'un standard plus étendu.
Extensions asiatiques, à base de séquences d'échappement
Afin d'unifier les différents codages de caractères complétant l'ASCII et y intégrer les codages complètement différents (le JIS pour le japonais par exemple, qui bien que développé aussi sur la base de l'US-ASCII, en diffère dans l'assignation d'un des 128 premiers codets), la norme ISO/CEI 10646 a été inventée (et aussi développée au départ séparément par le Consortium Unicode dans une version de sa norme Unicode 1.0 initialement incompatible avec ISO/CEI 10646).
Voir notamment ISO/CEI 2022.
Extensions Unicode
La version 1.0 a été abandonnée depuis la version 1.1 afin d'unifier et fusionner les deux répertoires dans un jeu universel de caractères codés. ISO/CEI 10646 codifie des dizaines de milliers de caractères, mais les 128 premiers restent compatibles avec ASCII (dans sa dernière version X3.4-1986) ; la norme Unicode y ajoute des sémantiques supplémentaires. Dans la norme Unicode, le standard ASCII est défini sous le nom de « C0 Controls and Basic Latin ».
Toutefois, certains pays d'Asie orientale (la République populaire de Chine, les anciens dominions britannique et portugais en Chine, de Hong Kong et Macao, qui sont devenus depuis des régions administratives spéciales de Chine, la République de Chine à Taïwan, et le Japon) ont choisi de continuer à développer leur propre norme pour coder le jeu de caractères universel, tout en choisissant de les maintenir entièrement convertibles avec l'ISO/CEI 10646 ; parmi ces normes asiatiques, seule la norme nationale japonaise continue à maintenir une différence dans ses 128 premières positions avec le jeu ASCII, en codant le symbole monétaire du yen à la place de la barre oblique inversée (comme c'est aussi le cas dans la variante japonaise de la norme ISO/CEI 646).
Influence
L'ASCII a eu une influence importante dans le monde informatique. En particulier, il a longtemps limité les caractères disponibles aux caractères latins non accentués, notamment dans le monde de l'Internet, que ce soit pour les noms de domaine, les adresses de courrier électronique, les caractères disponibles dans le BIOS, ou les caractères dans lesquels peuvent être écrits des programmes informatiques.
Description
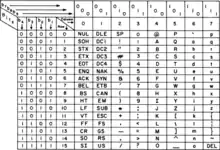
Table des 128 caractères ASCII
On peut présenter la table des caractères ASCII sous une forme condensée qui met en évidence une organisation fondée sur la base 16.
| en fr |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U+0000 | NUL |
SOH |
STX |
ETX |
EOT |
ENQ |
ACK |
BEL |
BS |
HT |
LF |
VT |
FF |
CR |
SO |
SI |
| U+0010 | DLE |
DC1 |
DC2 |
DC3 |
DC4 |
NAK |
SYN |
ETB |
CAN |
EM |
SUB |
ESC |
FS |
GS |
RS |
US |
| U+0020 | SP |
! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| U+0030 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| U+0040 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| U+0050 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| U+0060 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| U+0070 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Dans la table détaillée suivante, les 32 caractères de contrôle (codes 0 à 31 et 127) et l'espace (code 32) sont présentés avec leur nom en anglais suivi d'une traduction entre parenthèses.
| Code en base | Caractère | Signification | |||
|---|---|---|---|---|---|
| 10 | 8 | 16 | 2 | ||
| 0 | 0 | 00 | 0000000 | NUL | Null (nul) |
| 1 | 01 | 01 | 0000001 | SOH | Start of Heading (début d'en-tête) |
| 2 | 02 | 02 | 0000010 | STX | Start of Text (début de texte) |
| 3 | 03 | 03 | 0000011 | ETX | End of Text (fin de texte) |
| 4 | 04 | 04 | 0000100 | EOT | End of Transmission (fin de transmission) |
| 5 | 05 | 05 | 0000101 | ENQ | Enquiry (demande) |
| 6 | 06 | 06 | 0000110 | ACK | Acknowledge (accusé de réception) |
| 7 | 07 | 07 | 0000111 | BEL | Bell (sonnerie) |
| 8 | 010 | 08 | 0001000 | BS | Backspace (espacement arrière/supprimer) |
| 9 | 011 | 09 | 0001001 | HT | Horizontal Tab (tabulation horizontale) |
| 10 | 012 | 0A | 0001010 | LF | Line Feed (saut de ligne) |
| 11 | 013 | 0B | 0001011 | VT | Vertical Tab (tabulation verticale) |
| 12 | 014 | 0C | 0001100 | FF | Form Feed (saut de page) |
| 13 | 015 | 0D | 0001101 | CR | Carriage Return (retour chariot/retour à la ligne) |
| 14 | 016 | 0E | 0001110 | SO | Shift Out (code spécial) |
| 15 | 017 | 0F | 0001111 | SI | Shift In (code standard) |
| 16 | 020 | 10 | 0010000 | DLE | Data Link Escape (échappement en transmission) |
| 17 | 021 | 11 | 0010001 | DC1 | Device Control 1 à 4 (contrôle de périphérique) |
| 18 | 022 | 12 | 0010010 | DC2 | |
| 19 | 023 | 13 | 0010011 | DC3 | |
| 20 | 024 | 14 | 0010100 | DC4 | |
| 21 | 025 | 15 | 0010101 | NAK | Negative Acknowledge (accusé de réception négatif) |
| 22 | 026 | 16 | 0010110 | SYN | Synchronous Idle (attente synchronisée) |
| 23 | 027 | 17 | 0010111 | ETB | End of Transmission Block (fin de bloc de transmission) |
| 24 | 030 | 18 | 0011000 | CAN | Cancel (annulation) |
| 25 | 031 | 19 | 0011001 | EM | End of Medium (fin de support) |
| 26 | 032 | 1A | 0011010 | SUB | Substitute (remplacement) |
| 27 | 033 | 1B | 0011011 | ESC | Escape (échappement) |
| 28 | 034 | 1C | 0011100 | FS | File Separator (séparateur de fichier) |
| 29 | 035 | 1D | 0011101 | GS | Group Separator (séparateur de groupe) |
| 30 | 036 | 1E | 0011110 | RS | Record Separator (séparateur d'enregistrement) |
| 31 | 037 | 1F | 0011111 | US | Unit Separator (séparateur d'unité) |
| 32 | 040 | 20 | 0100000 | SP | Space (espacement) |
| 33 | 041 | 21 | 0100001 | ! | Point d'exclamation |
| 34 | 042 | 22 | 0100010 | " | Guillemet |
| 35 | 043 | 23 | 0100011 | # | Croisillon[10] |
| 36 | 044 | 24 | 0100100 | $ | Dollar |
| 37 | 045 | 25 | 0100101 | % | Pour cent |
| 38 | 046 | 26 | 0100110 | & | Esperluette[10] |
| 39 | 047 | 27 | 0100111 | ' | Apostrophe[14] |
| 40 | 050 | 28 | 0101000 | ( | Parenthèse ouvrante |
| 41 | 051 | 29 | 0101001 | ) | Parenthèse fermante |
| 42 | 052 | 2A | 0101010 | * | Astérisque |
| 43 | 053 | 2B | 0101011 | + | Plus |
| 44 | 054 | 2C | 0101100 | , | Virgule |
| 45 | 055 | 2D | 0101101 | - | Trait d'union, moins[10] |
| 46 | 056 | 2E | 0101110 | . | Point |
| 47 | 057 | 2F | 0101111 | / | Barre oblique |
| 48 | 060 | 30 | 0110000 | 0 | Chiffre zéro |
| 49 | 061 | 31 | 0110001 | 1 | Chiffre un |
| 50 | 062 | 32 | 0110010 | 2 | Chiffre deux |
| 51 | 063 | 33 | 0110011 | 3 | Chiffre trois |
| 52 | 064 | 34 | 0110100 | 4 | Chiffre quatre |
| 53 | 065 | 35 | 0110101 | 5 | Chiffre cinq |
| 54 | 066 | 36 | 0110110 | 6 | Chiffre six |
| 55 | 067 | 37 | 0110111 | 7 | Chiffre sept |
| 56 | 070 | 38 | 0111000 | 8 | Chiffre huit |
| 57 | 071 | 39 | 0111001 | 9 | Chiffre neuf |
| 58 | 072 | 3A | 0111010 | : | Deux-points |
| 59 | 073 | 3B | 0111011 | ; | Point-virgule |
| 60 | 074 | 3C | 0111100 | < | Inférieur |
| 61 | 075 | 3D | 0111101 | = | Égal |
| 62 | 076 | 3E | 0111110 | > | Supérieur |
| 63 | 077 | 3F | 0111111 | ? | Point d'interrogation |
| 64 | 0100 | 40 | 1000000 | @ | Arobase[10] |
| 65 | 0101 | 41 | 1000001 | A | Lettre latine capitale A |
| 66 | 0102 | 42 | 1000010 | B | Lettre latine capitale B |
| 67 | 0103 | 43 | 1000011 | C | Lettre latine capitale C |
| 68 | 0104 | 44 | 1000100 | D | Lettre latine capitale D |
| 69 | 0105 | 45 | 1000101 | E | Lettre latine capitale E |
| 70 | 0106 | 46 | 1000110 | F | Lettre latine capitale F |
| 71 | 0107 | 47 | 1000111 | G | Lettre latine capitale G |
| 72 | 0110 | 48 | 1001000 | H | Lettre latine capitale H |
| 73 | 0111 | 49 | 1001001 | I | Lettre latine capitale I |
| 74 | 0112 | 4A | 1001010 | J | Lettre latine capitale J |
| 75 | 0113 | 4B | 1001011 | K | Lettre latine capitale K |
| 76 | 0114 | 4C | 1001100 | L | Lettre latine capitale L |
| 77 | 0115 | 4D | 1001101 | M | Lettre latine capitale M |
| 78 | 0116 | 4E | 1001110 | N | Lettre latine capitale N |
| 79 | 0117 | 4F | 1001111 | O | Lettre latine capitale O |
| 80 | 0120 | 50 | 1010000 | P | Lettre latine capitale P |
| 81 | 0121 | 51 | 1010001 | Q | Lettre latine capitale Q |
| 82 | 0122 | 52 | 1010010 | R | Lettre latine capitale R |
| 83 | 0123 | 53 | 1010011 | S | Lettre latine capitale S |
| 84 | 0124 | 54 | 1010100 | T | Lettre latine capitale T |
| 85 | 0125 | 55 | 1010101 | U | Lettre latine capitale U |
| 86 | 0126 | 56 | 1010110 | V | Lettre latine capitale V |
| 87 | 0127 | 57 | 1010111 | W | Lettre latine capitale W |
| 88 | 0130 | 58 | 1011000 | X | Lettre latine capitale X |
| 89 | 0131 | 59 | 1011001 | Y | Lettre latine capitale Y |
| 90 | 0132 | 5A | 1011010 | Z | Lettre latine capitale Z |
| 91 | 0133 | 5B | 1011011 | [ | Crochet ouvrant |
| 92 | 0134 | 5C | 1011100 | \ | Barre oblique inversée |
| 93 | 0135 | 5D | 1011101 | ] | Crochet fermant |
| 94 | 0136 | 5E | 1011110 | ^ | Accent circonflexe (avec chasse) |
| 95 | 0137 | 5F | 1011111 | _ | Tiret bas[10] |
| 96 | 0140 | 60 | 1100000 | ` | Accent grave (avec chasse)[15] |
| 97 | 0141 | 61 | 1100001 | a | Lettre latine minuscule a |
| 98 | 0142 | 62 | 1100010 | b | Lettre latine minuscule b |
| 99 | 0143 | 63 | 1100011 | c | Lettre latine minuscule c |
| 100 | 0144 | 64 | 1100100 | d | Lettre latine minuscule d |
| 101 | 0145 | 65 | 1100101 | e | Lettre latine minuscule e |
| 102 | 0146 | 66 | 1100110 | f | Lettre latine minuscule f |
| 103 | 0147 | 67 | 1100111 | g | Lettre latine minuscule g |
| 104 | 0150 | 68 | 1101000 | h | Lettre latine minuscule h |
| 105 | 0151 | 69 | 1101001 | i | Lettre latine minuscule i |
| 106 | 0152 | 6A | 1101010 | j | Lettre latine minuscule j |
| 107 | 0153 | 6B | 1101011 | k | Lettre latine minuscule k |
| 108 | 0154 | 6C | 1101100 | l | Lettre latine minuscule l |
| 109 | 0155 | 6D | 1101101 | m | Lettre latine minuscule m |
| 110 | 0156 | 6E | 1101110 | n | Lettre latine minuscule n |
| 111 | 0157 | 6F | 1101111 | o | Lettre latine minuscule o |
| 112 | 0160 | 70 | 1110000 | p | Lettre latine minuscule p |
| 113 | 0161 | 71 | 1110001 | q | Lettre latine minuscule q |
| 114 | 0162 | 72 | 1110010 | r | Lettre latine minuscule r |
| 115 | 0163 | 73 | 1110011 | s | Lettre latine minuscule s |
| 116 | 0164 | 74 | 1110100 | t | Lettre latine minuscule t |
| 117 | 0165 | 75 | 1110101 | u | Lettre latine minuscule u |
| 118 | 0166 | 76 | 1110110 | v | Lettre latine minuscule v |
| 119 | 0167 | 77 | 1110111 | w | Lettre latine minuscule w |
| 120 | 0170 | 78 | 1111000 | x | Lettre latine minuscule x |
| 121 | 0171 | 79 | 1111001 | y | Lettre latine minuscule y |
| 122 | 0172 | 7A | 1111010 | z | Lettre latine minuscule z |
| 123 | 0173 | 7B | 1111011 | { | Accolade ouvrante |
| 124 | 0174 | 7C | 1111100 | | | Barre verticale |
| 125 | 0175 | 7D | 1111101 | } | Accolade fermante |
| 126 | 0176 | 7E | 1111110 | ~ | Tilde |
| 127 | 0177 | 7F | 1111111 | DEL | Delete (effacement) |
Groupement par type de caractères
Caractères de contrôle
ASCII réserve les 32 premiers codes (nombres décimaux de 0 à 31) pour les caractères de contrôle : codes destinés non à représenter des informations imprimables, mais plutôt à contrôler des périphériques (tels que des imprimantes) qui utilisent ASCII ou à fournir des méta-informations sur les flux de données, tels que ceux stockés sur bande magnétique.
| Binaire | Oct. | Déc. | Hex. | Abréviation | [note 1] | [note 2] | [note 3] | Nom (1967) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1963 | 1965 | 1967 | ||||||||
| 000 0000 | 000 | 0 | 00 | NULL | NUL | ␀ | ^@ | \0 | Caractère nul | |
| 000 0001 | 001 | 1 | 01 | SOM | SOH | ␁ | ^A | Caractère de début d'en-tête | ||
| 000 0010 | 002 | 2 | 02 | EOA | STX | ␂ | ^B | Caractère de début de texte | ||
| 000 0011 | 003 | 3 | 03 | EOM | ETX | ␃ | ^C | Caractère de fin de texte | ||
| 000 0100 | 004 | 4 | 04 | EOT | ␄ | ^D | Caractère de fin de transmission | |||
| 000 0101 | 005 | 5 | 05 | WRU | ENQ | ␅ | ^E | Caractère de demande de renseignement | ||
| 000 0110 | 006 | 6 | 06 | RU | ACK | ␆ | ^F | Caractère d'acquittement | ||
| 000 0111 | 007 | 7 | 07 | BELL | BEL | ␇ | ^G | \a | Caractère d'appel | |
| 000 1000 | 010 | 8 | 08 | FE0 | BS | ␈ | ^H | \b | Caractère de retour arrière[note 4],[note 5] | |
| 000 1001 | 011 | 9 | 09 | HT/SK | HT | ␉ | ^I | \t | Caractère de tabulation horizontale[note 6] | |
| 000 1010 | 012 | 10 | 0A | LF | ␊ | ^J | \n | Caractère de saut de ligne | ||
| 000 1011 | 013 | 11 | 0B | VTAB | VT | ␋ | ^K | \v | Caractère de tabulation verticale | |
| 000 1100 | 014 | 12 | 0C | FF | ␌ | ^L | \f | Caractère de changement de page | ||
| 000 1101 | 015 | 13 | 0D | CR | ␍ | ^M | \r | Caractère de retour chariot[note 7] | ||
| 000 1110 | 016 | 14 | 0E | SO | ␎ | ^N | Shift Out | |||
| 000 1111 | 017 | 15 | 0F | SI | ␏ | ^O | Shift In | |||
| 001 0000 | 020 | 16 | 10 | DC0 | DLE | ␐ | ^P | Data Link Escape | ||
| 001 0001 | 021 | 17 | 11 | DC1 | ␑ | ^Q | Device Control 1 (souvent XON) | |||
| 001 0010 | 022 | 18 | 12 | DC2 | ␒ | ^R | Device Control 2 | |||
| 001 0011 | 023 | 19 | 13 | DC3 | ␓ | ^S | Device Control 3 (souvent XOFF) | |||
| 001 0100 | 024 | 20 | 14 | DC4 | ␔ | ^T | Device Control 4 | |||
| 001 0101 | 025 | 21 | 15 | ERR | NAK | ␕ | ^U | Negative Acknowledgement | ||
| 001 0110 | 026 | 22 | 16 | SYNC | SYN | ␖ | ^V | Synchronous Idle | ||
| 001 0111 | 027 | 23 | 17 | LEM | ETB | ␗ | ^W | End of Transmission Block | ||
| 001 1000 | 030 | 24 | 18 | S0 | CAN | ␘ | ^X | Cancel | ||
| 001 1001 | 031 | 25 | 19 | S1 | EM | ␙ | ^Y | End of Medium | ||
| 001 1010 | 032 | 26 | 1A | S2 | SS | SUB | ␚ | ^Z | Substitute | |
| 001 1011 | 033 | 27 | 1B | S3 | ESC | ␛ | ^[ | \e[note 8] | Escape[note 9] | |
| 001 1100 | 034 | 28 | 1C | S4 | FS | ␜ | ^\ | File Separator | ||
| 001 1101 | 035 | 29 | 1D | S5 | GS | ␝ | ^] | Group Separator | ||
| 001 1110 | 036 | 30 | 1E | S6 | RS | ␞ | ^^[note 10] | Record Separator | ||
| 001 1111 | 037 | 31 | 1F | S7 | US | ␟ | ^_ | Unit Separator | ||
| 111 1111 | 177 | 127 | 7F | DEL | ␡ | ^? | Delete[note 11],[note 5] | |||
NUL
Null : nul. Il est à l'origine une NOP, c'est-à-dire un caractère à ignorer. Lui donner le code 0 permettait de prévoir des réserves sur les bandes perforées en laissant des zones sans perforation pour insérer de nouveaux caractères a posteriori. Avec le développement du langage C, il a pris une importance particulière quand il a été utilisé comme indicateur de fin de chaîne de caractères.
SOH
Start of Heading : début d'en-tête. Il est aujourd'hui souvent utilisé dans les communications séries pour permettre la synchronisation après erreur[16].
DEL
Delete : effacement. Lui donner le code 127 (1111111 en binaire) permettait de supprimer a posteriori un caractère sur les bandes perforées qui codaient les informations sur 7 bits. N'importe quel caractère pouvait être transformé en DEL en complétant la perforation des 7 bits qui le composaient.
LF, CR
Line Feed : saut de ligne, Carriage Return : retour chariot. Dans un fichier texte, la fin d'une ligne est représentée par un ou deux caractères de contrôle. Plusieurs conventions existent :
- sur les systèmes Multics, Unix, Type Unix (Linux, AIX, Xenix, Mac OS X, etc.), BeOS, AmigaOS, RISC OS entre autres, la fin de ligne est indiquée par un saut de ligne (LF) ;
- sur les machines Apple II et Mac OS jusqu'à la version 9, la fin de ligne est indiquée par un retour chariot (CR) ;
- sur les systèmes DEC, RT-11 et généralement tous les premiers systèmes non-Unix et non-IBM, CP/M, MP/M, MS-DOS, OS/2 ou Microsoft Windows, la fin de ligne est indiquée par un retour chariot suivi d'un saut de ligne (CR suivi de LF).
Ainsi, lorsqu'on transfère un fichier ASCII entre des systèmes ayant des conventions de fin de ligne différentes, il faut convertir les fins de ligne pour pouvoir manipuler le fichier confortablement sur le système cible. Autrement, il faut utiliser un éditeur de texte capable de gérer les diverses conventions de fin de ligne, ce qui n'est par exemple pas le cas du classique Bloc-notes de Microsoft Windows. Les programmes utilisant les fichiers ASCII ne sont en général pas perturbés par un changement de type de fin de ligne.
SUB
Substitute : remplacement. Il est souvent associé à la combinaison de touches Ctrl + z et est utilisé dans les communications séries pour permettre l'envoi des données en lieu et place de la touche entrée.
Caractères imprimables
Les codes 20hex à 7Ehex, appelés caractères imprimables, représentent des lettres, des chiffres, des signes de ponctuation et quelques symboles divers. Il y a 95 caractères imprimables au total.
Le code 20hex, le caractère espace, désigne l'espace entre les mots, tel que produit par la barre d'espace d'un clavier. Le caractère espace étant considéré comme un graphique invisible (plutôt que comme caractère de contrôle[17]:223,[18]), il est répertorié dans le tableau ci-dessous et non dans la section précédente.
Le code 7Fhex correspond au caractère d'effacement (DEL) n'est pas imprimable et est donc omis de ce tableau. Il est inclus dans le tableau de la section précédente.
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Notes
- ↑ Les caractères Unicode de la zone U+2400 à U+2421 sont réservés pour représenter les caractères de contrôle quand il est nécessaire de les imprimer ou de les afficher plutôt que de les laisser jouer leur fonction prévue. Certains navigateurs peuvent ne pas les afficher correctement.
- ↑ Le caret est souvent utilisé pour représenter les caractères de contrôle sur un terminal. Sur la plupart des terminaux texte, tenir enfoncée la touche Ctrl tout en tapant le second caractère imprimera le caractère de contrôle. Parfois la touche majuscule n'est pas utile, par exemple
^@peut être tapé avec seulement Ctrl et 0. - ↑ Séquences d'échappement en C et dans beaucoup d'autres langages influencés par lui, tels que Java et Perl (bien que toutes les implémentations ne supportent pas nécessairement toutes les séquences d'échappement).
- ↑ Le caractère Backspace peut aussi être entré en appuyant sur la touche Backspace de certains claviers.
- 1 2 L'ambiguïté de Backspace est due aux premiers terminaux conçus en supposant que l'utilisation principale du clavier serait de perforer manuellement la bande de papier sans être connecté à un ordinateur. Pour supprimer le caractère précédent, il fallait sauvegarder le poinçon de bande de papier, qui pour des raisons mécaniques et de simplicité était un bouton sur le poinçon lui-même et non le clavier, puis taper le caractère d'effacement. Ils ont donc placé une clé produisant un effacement à l'emplacement utilisé sur les machines à écrire pour le retour arrière. Lorsque les systèmes utilisaient ces terminaux et fournissaient une édition en ligne de commande, ils devaient utiliser le code rubout pour effectuer un retour arrière et n'interprétaient souvent pas le caractère de retour arrière (ils pouvaient faire écho à
^Hpour revenir en arrière). D'autres terminaux non conçus pour la bande de papier ont fait la clé à cet endroit pour produire Backspace, et les systèmes conçus pour ceux-ci ont utilisé ce caractère pour sauvegarder. Étant donné que le code de suppression produit souvent un effet de retour arrière, cela oblige également les fabricants de terminaux à faire en sorte que n'importe quelle touche Delete produise autre chose que le caractère Delete. - ↑ Le caractère de tabulation peut aussi être entré en appuyant sur la touche de tabulation Tab sur la plupart des claviers.
- ↑ Le caractère de retour de chariot peut aussi être entré en appuyant sur la touche d'entrée (Entrée) sur la plupart des claviers.
- ↑ La séquence d'échappement
\ene fait pas partie des spécifications de l'ANSI C et de beaucoup d'autres langages. Cependant, elle est comprise par plusieurs compilateurs, dont GCC. - ↑ Le caractère d'échappement peut aussi être entré en appuyant sur la touche Esc de certains claviers.
- ↑ ^^ signifie Ctrl + ^ (en appuyant sur les touches "Ctrl" et caret).
- ↑ Le caractère d'effacement peut parfois être entré en appuyant sur la touche Backspace sur certains claviers.
Références
- ↑ « trailing-edge.com/~bobbemer/SU… »(Archive.org • Wikiwix • Archive.is • Google • Que faire ?).
- ↑ Flermond Richard, Histoire des supports de stockage: de la carte perforée à la clé USB, université de Lyon et ENSSIB, (lire en ligne)
- ↑ Mathias Chaillot, « La folle évolution du stockage informatique », Capital, (lire en ligne)
- ↑ (en) « Archives and Special Collections / University of Minnesota Libraries », sur umn.edu (consulté le ).
- ↑ Bob Bemer, « Computer History Vignettes: That Troublesome "Father of" », sur www.bobbemer.com (version du 2 octobre 2017 sur Internet Archive)
- ↑ Appendix §A.6.8 de la norme de A963
- ↑ « Character histories - notes on some Ascii code positions », sur jkorpela.fi (consulté le )
- ↑ (fr) Unicode 5.0 en pratique, chapitre 7 « Ponctuation », Patrick Andries.
- ↑ Alphabet International de référence no 5 : RECOMMANDATION T50, Union international des télécommunications, (lire en ligne)
- 1 2 3 4 5 6 Alphabet International de référence : ANCIEN ALPHABET INTERNATIONAL no 5 ou AI5, RECOMMANDATION T50, Union international des télécommunications, (lire en ligne)
- ↑ (en) K. Simonsen, Rationel Almen Planlaegning, Request for comments: 1345 : Character Mnemonics & Character Sets, Network Working Group, (lire en ligne).
- 1 2 Internet Assigned Numbers Authority (May 14, 2007). "Character Sets". Accessed 2008-04-14.
- ↑ Roman Czyborra, « ISO 8859-1 and MCS, from ISO 8859 Alphabet Soup », sur czyborra.com
- ↑ La norme ANSI X3.4 définit le caractère 39 par apostrophe (closing single quotation mark, acute accent) et les anciennes tables de caractères le représentaient souvent incliné. Les encodages plus récents restreignent ce code à la représentation de l'apostrophe verticale (ni penchée à droite, ni à gauche, mais neutre). Voir (en) Latin-1's apostrophe, grave accent, acute accent.
- ↑ Le code 96 est également employé comme guillemet ouvrant simple en ASCII. En Unicode, il existe un code plus approprié.
- ↑ (en) ASCII character set
- ↑ (en) Charles E. Mackenzie, The Systems Programming Series, Addison-Wesley Publishing Company, Inc., , 6, 66, 211, 215, 217, 220, 223, 228, 236–238, 243–245, 247–253, 423, 425–428, 435–439 (ISBN 0-201-14460-3, LCCN 77-90165, lire en ligne)
- ↑ (en) Vinton Gray Cerf, « ASCII format for Network Interchange », Network Working Group, (NB : quasiment identique à l'USAS X3.4-1968 mis-à-part l'introduction.)
Voir aussi
Articles connexes
- Art ASCII
- ASCII porn
- Fichier texte
- Vidéotex
- Unicode
- (3568) ASCII, astéroïde nommé en ce nom
Bibliographie
- (en) Business Equipment Manufacturer Associations, American Standard Code for Information Interchange : ASA standard X3.4-1963, American Standards Asociation Incorporated, (lire en ligne)
- (en) Eric Fischer, The Evolution of Character Codes, 1874-1968, .transbay.net (lire en ligne)
- (en) American Standard Code for Information Interchange, AMERICAN STANDARDS ASSOCIATION, , 12 p. (lire en ligne)